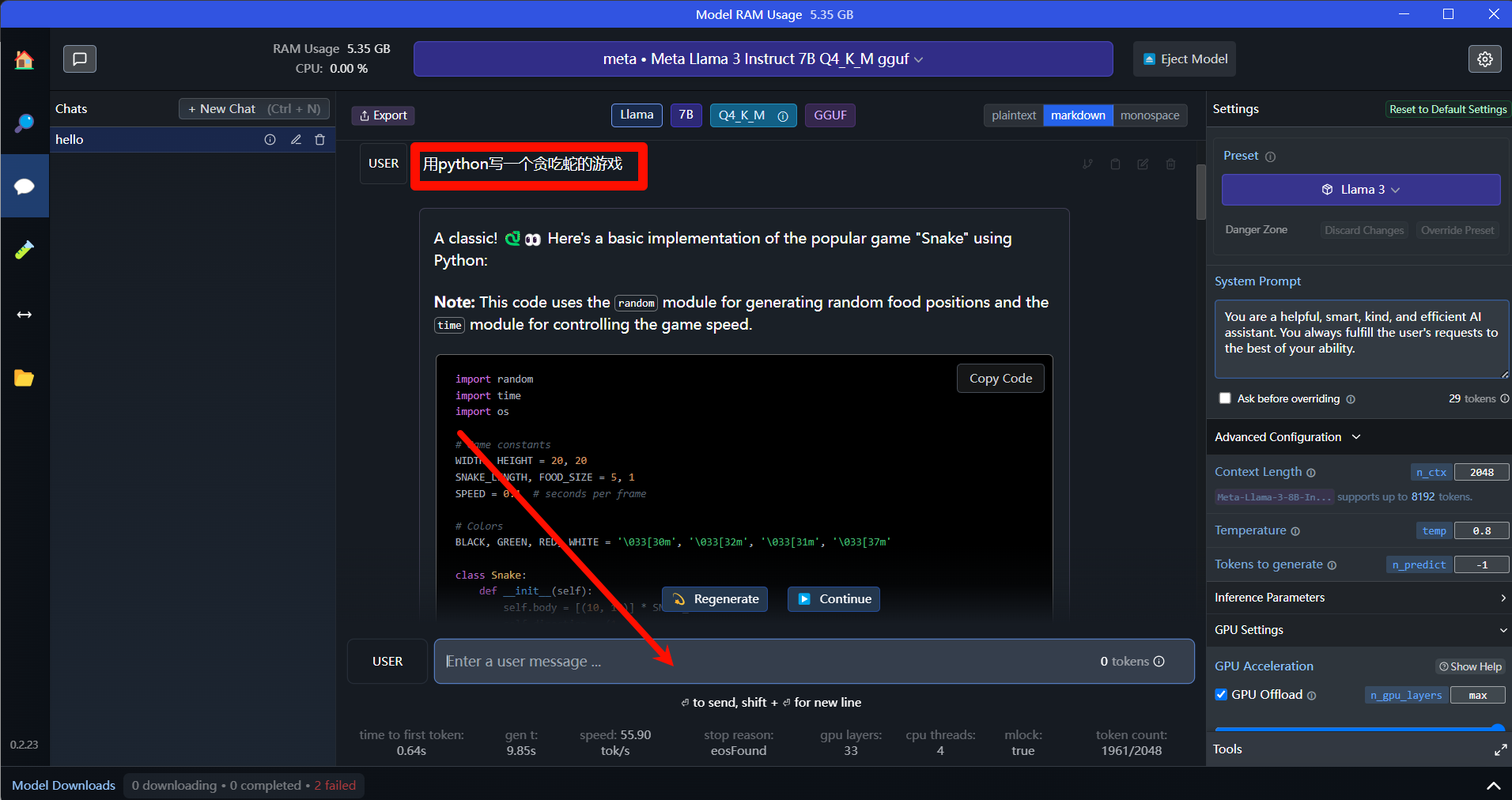
一首歌的时间部署本地Llama3大模型
LLaMA3真的是相当相当炸裂啊!远超过去的体验!看数据Llama3-8B超过Mistra-7BMMLU10分;70B超过Claude3Sonet3分。 这是一个惊人的成绩,一个开源模型超过闭源模型这样多。我只能说Meta是真正的OpenAI。自从它从Meta这个邪路上转正后,在OpenAI的路上一骑绝尘了! 不废话,动手来给自己的电脑部署下吧。
有什么硬件要求
N卡独占,起步4G显存,建议8G+。纯CPU也能跑,如果你不嫌慢的话。
1. 安装LM studio
就这个软件(LM Studio - Discover, download, and run local LLMs)

安装成功,打开后应该出现如下界面
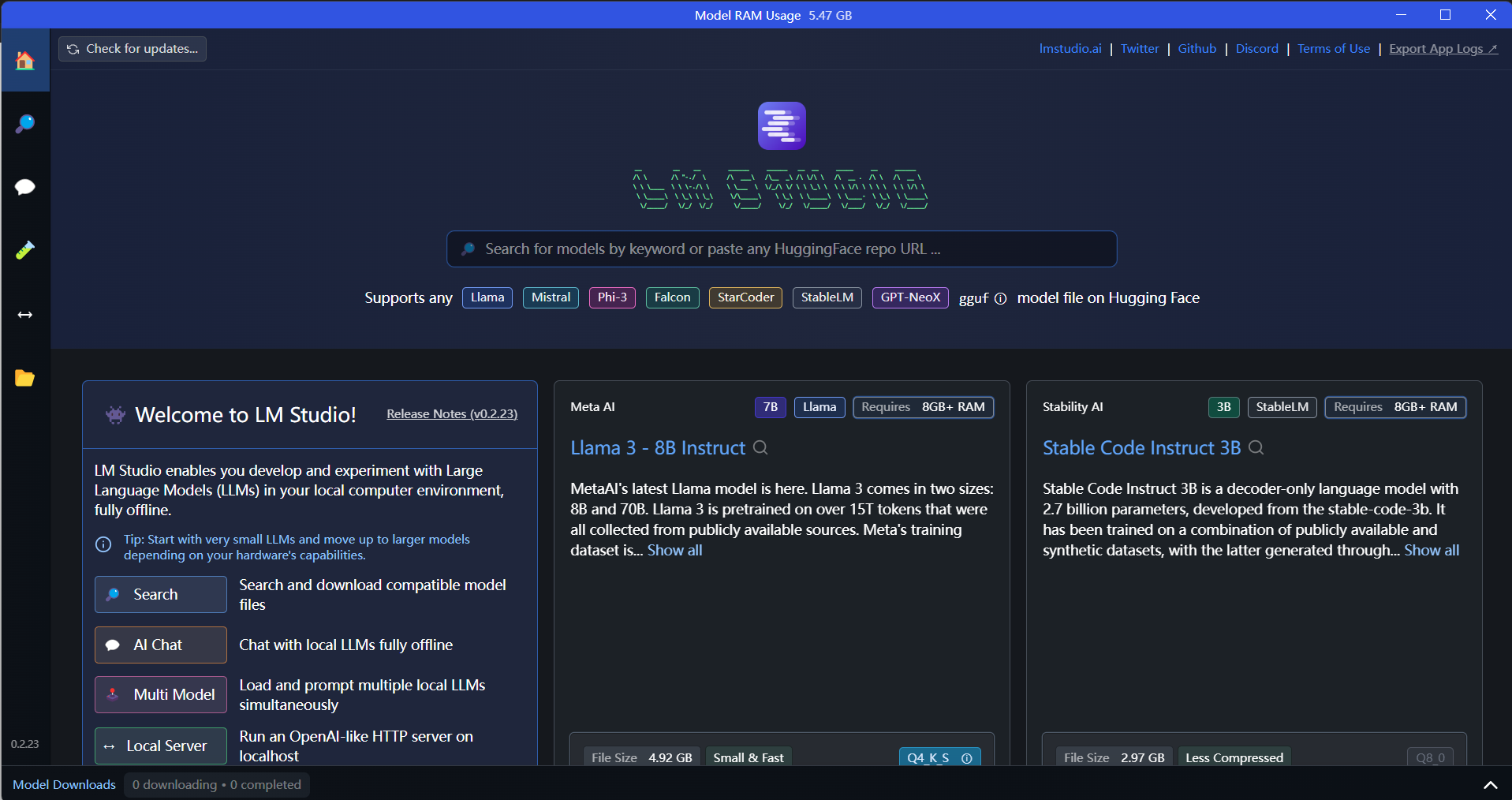
2. 选择llama3-8B模型
我们直接搜索llama 3-8B,找到该模型
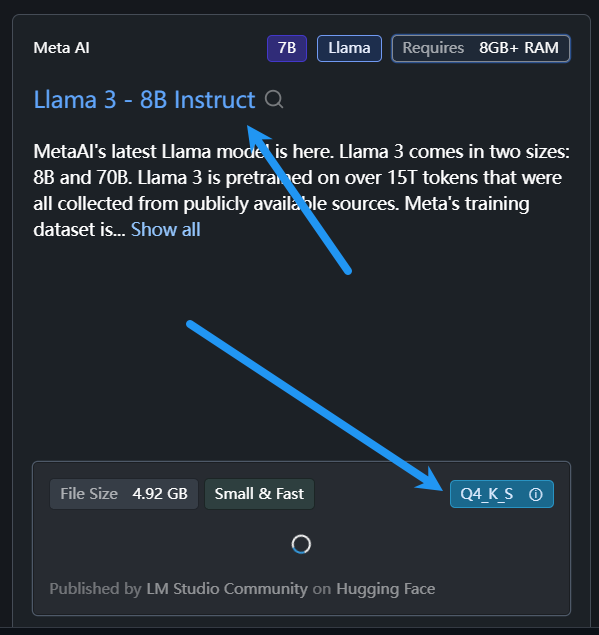
当然我们也可以选择其他模型,模型选择的重要因素是大小,也就是参数量。模型参数量一般写在名字上,比如 Dolphin 2.6 Mistral 7b – DPO Laser 就是7B大小,也就是70亿参数。根据自己的电脑内存和显存容量选(CPU运行就看内存,GPU运行就看显存,混合运行就两个加起来),我电脑是8G显存,用的7B模型。
然后就是模型指标,现在huggingface上有成百上千个LLM,可以根据benchmark的成绩选,排名网页在此:Open LLM Leaderboard - a Hugging Face Space by HuggingFaceH4 。
还有就是模型特性,比如是否经过审查,适合于什么类型的工作等。
3. 下载gguf文件
1. 在LM Studio内部下载,需要配置网络
如果有国际互联网连接就可以直接下载。如果没有见下一步。
2. 在huggingface下载并转移到LM Studio中
1. 下载
手动将网址复制到浏览器下载。
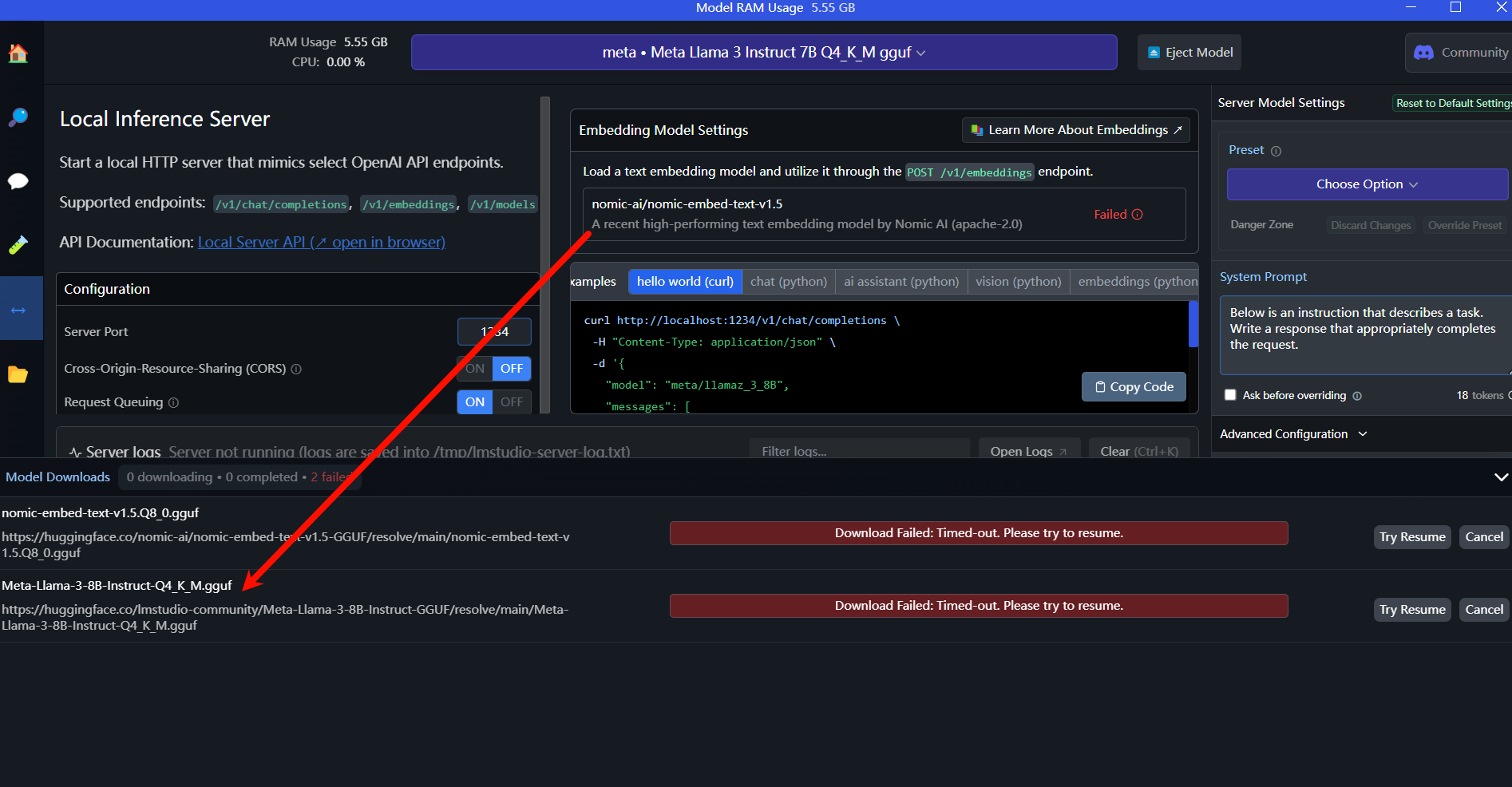
2. 移动下载的gguf文件到LM studio识别的位置
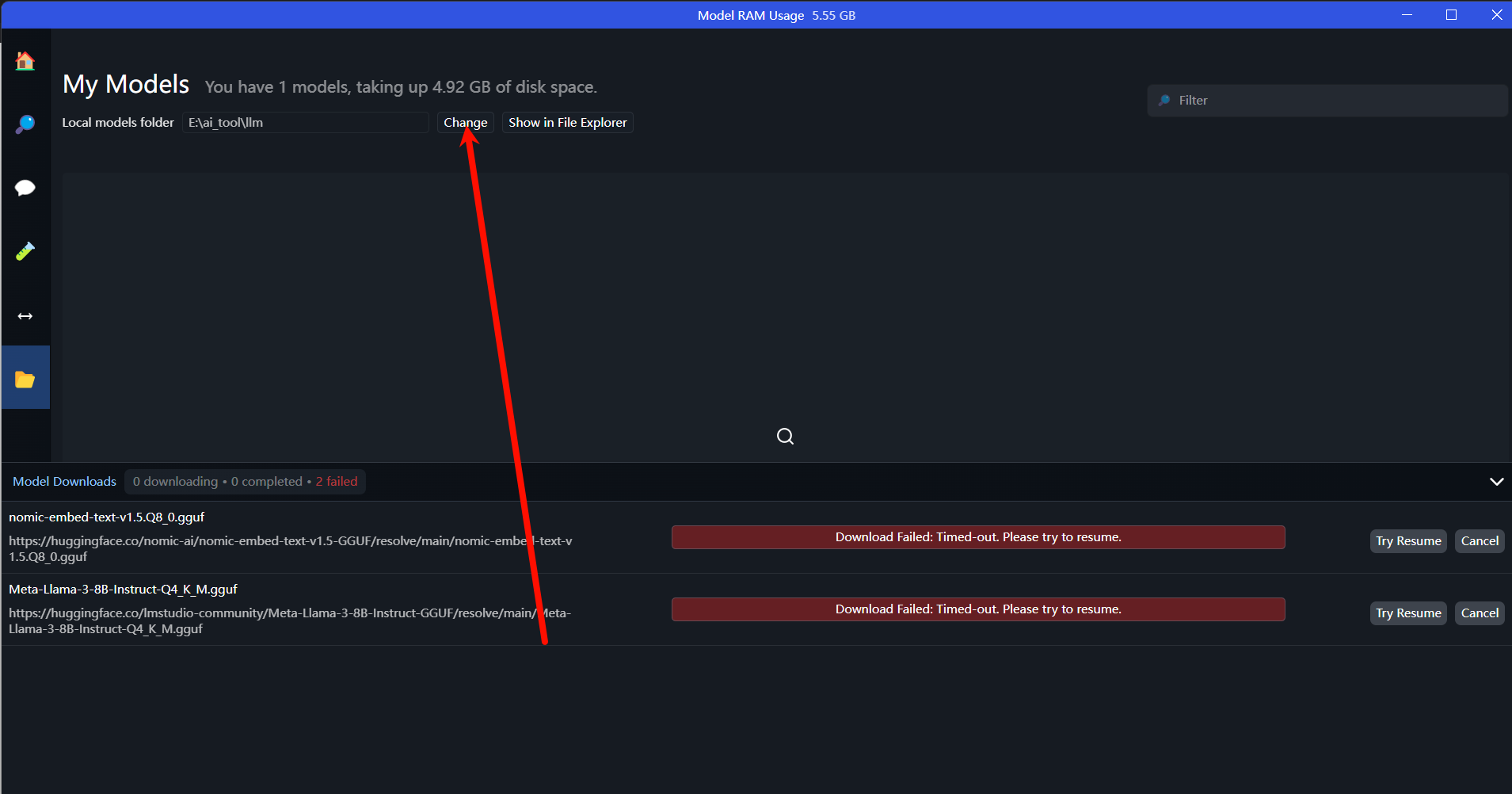
打开My models, 找到gguf文件位置,然后在系统文件管理器中管理好你下载的gguf文件路径,格式为models/A/B/xxx.gguf。再重启LM studio就能看到它。
4. 运行
1.CPU运行
同GPU运行,但不用改settings 中的 GPU 参数。
2.GPU运行
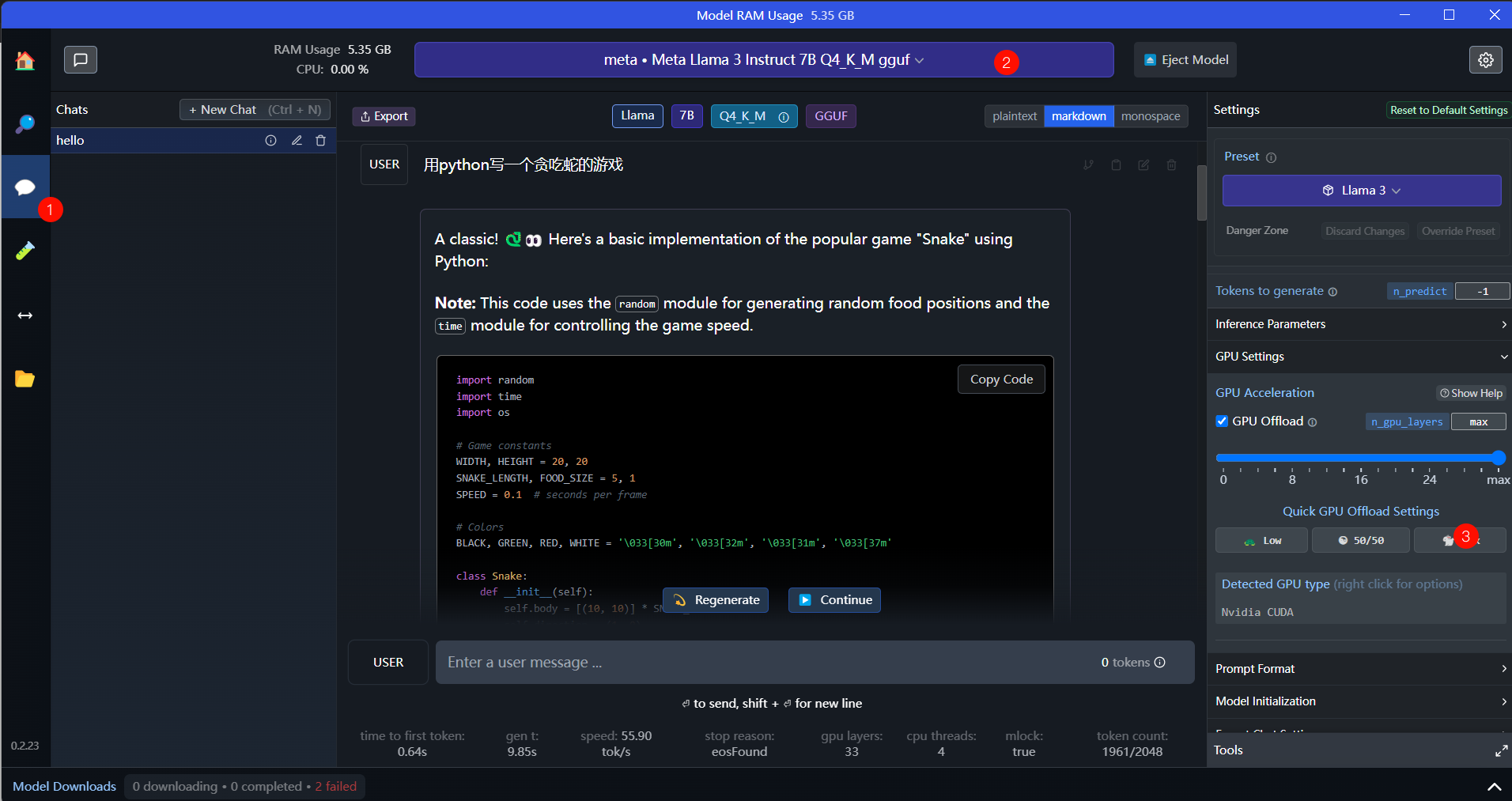
然后点击窗口上方的Select a model to load,加载上一步下载的模型就可以了。任务管理器中可以监视显存占用。
如果成功加载到显卡,就可以在下方与其对话了。