大型语言模型LLM训练流程详解
更新内容
这里是近期(2024年8月1日)更新的LLaMA3.1的模型后训练(Post-training)策略和流程
在预训练的基础上,通过几轮后训练对模型进行微调,使其更好地与人类反馈对齐。
每轮后训练包括监督微调(SFT)和直接偏好优化(DPO),后者使用了人工注释和合成的数据样本。
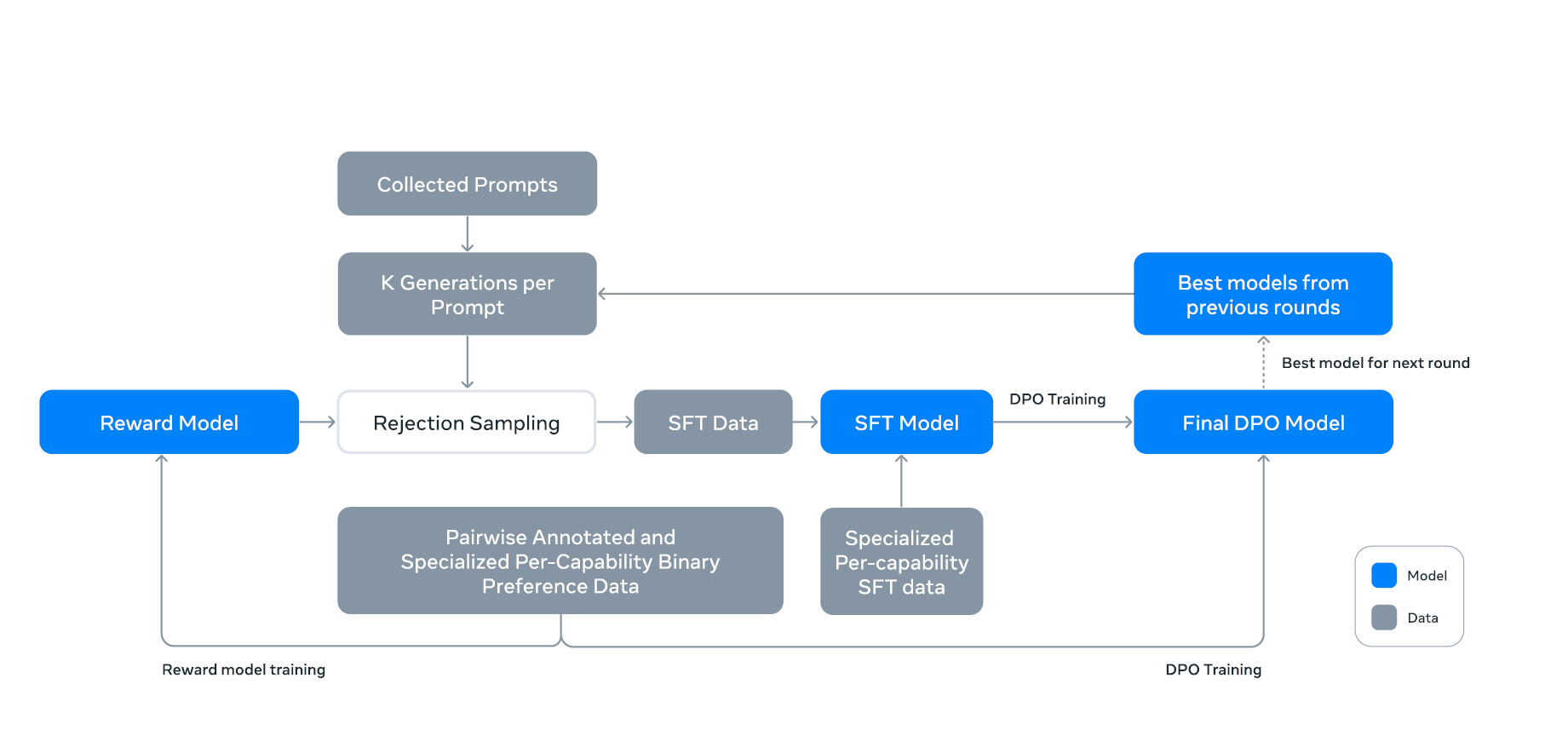
1.提示收集
- Collected Prompts(收集的提示):开始于收集各种输入提示。
2. 响应生成
- K Generations per Prompt(每个提示生成K个响应):每个提示生成多个响应(K个),以供后续选择和优化。
3. 响应筛选
- Rejection Sampling(拒绝采样)
- 使用奖励模型对生成的响应进行评分
- 通过拒绝采样来选择质量较高的响应
- 有助于筛选出最优的生成结果
4. 奖励模型
在预训练检查点的基础上训练奖励模型(Reward Model, RM),利用人类标注的偏好数据进行训练,主要目标是根据偏好数据进行排序和选择。
- 奖励模型使用(选择的、被拒绝的)响应对进行训练,此外,还可以通过对选择的响应进行编辑以创建第三种“编辑响应”。
- 将提示和多个响应连接为单行进行训练,响应随机打乱,以提高训练效率。
5. 监督微调
使用奖励模型对人类注释的提示进行拒绝采样,再结合合成数据进行监督微调。微调时使用交叉熵损失,采用的学习率和训练步数在实验中取得了良好的效果。
- SFT Data(监督微调数据):从拒绝采样中选出的高质量数据
- Specialized Per-Capability
Data(专门化的每项能力数据):
- 这些数据专注于特定能力的提升,比如推理、编码、事实性、多语言支持、工具使用、长上下文理解以及精准指令执行等。
- SFT Model(监督微调模型)
- 利用SFT数据进行监督微调训练
- 提高模型在特定任务上的表现
- 使用Specialized Per-capability SFT data,针对特定能力进行微调
使用交叉熵损失对目标标记进行训练,并对提示标记进行损失掩码。
大模型采用1e-5的学习率,训练步数为8500至9000步。
6. 直接偏好优化
DPO是在人类偏好数据上对齐模型的进一步优化步骤,旨在提高模型生成结果的满意度。
通过调整DPO的超参数(如学习率和正则化项)优化模型表现。使用DPO进行训练时,采用1e-5的学习率,并设定超参数β。
- Final DPO Model(最终直接偏好优化模型)
- 在SFT模型基础上进行直接偏好优化(DPO)训练
- 进一步对齐模型的输出与人类偏好
7. 模型迭代
- Best models from previous rounds(来自前几轮的最佳模型)
- 每轮训练后,选择表现最好的模型进入下一轮训练
LLM经典训练流程
1. 数据准备和预处理
- 大规模数据收集(网络爬虫、数据库购买等)
- 数据清洗和过滤(去重、去噪、内容审核等)
- 数据格式化和标准化
- 数据增强(如回译、同义词替换等)
2. 预训练(Pretraining)
- 数据集:来自互联网的原始数据,包含数万亿个单词,质量较低但数量庞大
- 算法:语言模型,通过预测下一个token进行训练(涉及其他自监督学习任务,如masked language modeling)
- 模型:基础模型(Base model),需要数千个GPU进行数月的大规模分布式训练
- 示例:GPT、LLaMA、PaLM等
- 备注:可以部署这个模型,过程涉及模型检查点保存和验证
以下阶段统称后训练
3. 监督微调(Supervised Finetuning)
- 数据集:由承包商编写的理想助手响应(包括提示和响应对),数量在1万到10万对之间,质量较高
- 特点:
- 数据集创建是关键挑战,需要精心设计提示和回答,以涵盖各种场景和任务
- 可能使用其他语言模型生成部分数据,然后人工筛选
- 可能引入特定领域的数据,以增强模型在某些领域的能力
- 算法:语言模型,通过预测下一个token进行训练
- 模型:SFT模型(Supervised Finetuning Model),从基础模型初始化,需要1到100个GPU,训练时间为数天
- 示例:Vicuna-13B
- 备注:可以部署这个模型
4. 奖励模型(Reward Modeling)
- 数据集:构建人类偏好数据集,由承包商编写的比较数据,数量在10万到100万之间,质量较高
比较对(pairwise comparisons)形式,即对于两个输出,标注出哪一个更符合人类偏好
输入 输出1 输出2 人类偏好 用户:天气怎么样? 答:今天晴天,温度25度。 答:今天天气不错,适合出门。 输出1 用户:今天天气如何? 答:温度大约20度,适合户外活动。 答:今天天气挺好的。 输出1
- 算法:二元分类或其它排序评分机制,通过预测一致性奖励来进行训练
- 模型:RM模型(Reward Model),从SFT模型初始化,需要1到100个GPU,训练时间为数天
- 备注:奖励模型可以独立部署,用于评估模型输出的质量。
5. 强化学习(Reinforcement Learning)
- 数据集:由承包商编写的提示数据,数量在1万到10万之间,质量较高
输入 目标输出 用户:天气怎么样? 答:今天晴天,气温在25度左右,非常适合户外活动。 用户:今天天气如何? 答:今天天气不错,气温大约20度,适合散步。
模型:RL模型(Reinforcement Learning Model),从SFT模型初始化并使用奖励模型,需要1到100个GPU,训练时间为数天
算法:强化学习,通过生成最大化奖励的token进行训练
常用强化学习算法包括Proximal Policy Optimization(PPO)等,使用奖励模型(RM)来提供反馈。
当模型生成的输出获得较高的奖励分数时,调整参数以增加生成此类输出的概率。
当模型生成的输出获得较低的奖励分数时,调整参数以减少生成此类输出的概率。
- 示例:ChatGPT和Claude
- 备注:可以部署这个模型,训练时监控和防止模型退化
6. 领域适应(Domain Adaptation)
- 数据集:来自源领域和目标领域的数据,源领域数据较为丰富,目标领域数据稀缺或分布不同,数量因领域而异
输入 目标输出 源领域:猫的图片 猫(分类标签) 目标领域:新环境中的猫的图片 猫(分类标签),需要模型适应目标领域的视觉特征变化
- 模型:领域适应模型(Domain Adaptation Model),通常使用迁移学习技术,将预训练模型在源领域的知识迁移到目标领域。可使用1到10个GPU,训练时间从数小时到数天不等,具体取决于数据规模和复杂度。
- 算法:使用对抗性训练(如DANN:Domain-Adversarial Neural Networks)或重加权方法(如TCA:Transfer Component Analysis)来最小化源领域和目标领域的分布差异
领域适应通常涉及在源领域预训练模型,然后在目标领域进行微调或通过对抗性损失调整模型,使其在目标领域上表现良好。
主要思想是通过对抗性训练使模型对源领域和目标领域的数据分布差异不敏感。
通过减少源领域和目标领域特征空间的分布差异,提高模型在目标领域的性能。
7. 多任务学习(Multi-task Learning)
主要内容:设计多种下游任务 , 联合训练模型以提高泛化能力
- 数据集:多任务学习需要来自多个相关任务的数据集,各任务数据量可根据实际情况调整,通常任务间有某种程度的相关性
输入 目标输出 任务1:语法纠正 正确的句子(语言修正) 任务2:情感分析 情感标签(正面、负面、中性) 任务3:机器翻译 目标语言翻译(英语翻译为法语)
- 模型:多任务学习模型(Multi-task Learning Model),通过共享表示学习多个任务。可用1到100个GPU,训练时间因任务和数据量而异,从数小时到数天不等。
- 算法:使用共享参数架构(如共享编码器-解码器)或任务特定头,在多个相关任务间共享知识和表示
多任务学习通过共享网络的部分结构来共同训练多个任务。
共享部分捕获任务间的通用特征,而每个任务也有其特定的参数以捕获专门特性。
这种方法有助于利用相关任务的信息来增强模型的泛化能力和性能。
- 示例:QWEN的多任务学习应用,包括问答、文本分类和实体识别等任务
- 备注:多任务学习模型需注意任务间的权衡与平衡,可能需要调整不同任务的损失函数权重
8. 多模态扩展(如果适用)
- 数据集:构建多模态数据集,包括文本、图像、音频和视频等模态,规模可达数十亿样本,数据多样性高,标注质量优良。
数据集包含多模态的配对样本,例如文本与图像的对齐关系、音频与视频的关联信息等,数据应覆盖多种场景和领域,以支持模型的广泛应用。
- 模型:多模态大模型(如CLIP、DALL-E),基于Transformer架构,支持多模态信息的联合学习和表征,训练时需高性能计算资源。
模型能够处理和融合来自多种模态的信息,使用跨模态对齐机制学习不同模态之间的关系。初始模型可能需要在大规模数据上进行预训练,并通过微调适应特定任务。
- 算法:使用跨模态对齐算法,如对比学习和自监督学习,通过优化不同模态表示之间的一致性来提高模型性能。
对比学习可以用于学习文本和图像的共同表示空间,通过最小化相似模态的距离和最大化不相似模态的距离,实现模态对齐和信息融合。
- 备注:多模态模型需要大量计算资源,训练时应注意数据隐私和伦理问题,未来发展方向包括提高模型的泛化能力和降低计算成本。
9. 模型压缩和优化
- 知识蒸馏(Knowledge Distillation)
- 模型量化(Quantization)
- 模型剪枝(Pruning)
- 模型结构搜索(Neural Architecture Search)
10. 安全性和伦理性强化
- 偏见检测和缓解
- 有害内容过滤训练
- 隐私保护机制实现(如联邦学习)
11. 模型评估和基准测试
- 在各种NLP任务上进行评估
- 与其他模型比较性能
- 进行人类评估
12. 部署准备
- 模型服务化(如ONNX转换、TensorRT优化等)
- API设计和实现
- 性能优化(如推理加速)
13. 持续学习和更新
- 收集用户反馈
- 增量训练或定期重训练
- A/B测试新版本
14. 模型解释性和可视化
- 注意力可视化
- 决策树提取
- 概念激活向量分析
额外说明
流程说明
- 整个流程可能是迭代的,而不是严格的线性过程。例如,可能在RL后再进行SFT。
- 多模态模型(如GPT-4)的训练可能涉及更复杂的流程和数据处理。
大模型对齐(Large Language Model Alignment)与RLHF
大模型对齐指的是在预训练的基础上,进一步将大模型的输出与任务场景和人类的价值观相统一,大模型对齐分为SFT,RLHF两个阶段,RLHF(Reinforcement
Learning from Human
Feedback)指的是人类反馈强化学习的方法,它一般涵盖奖励模型和强化学习两个步骤。
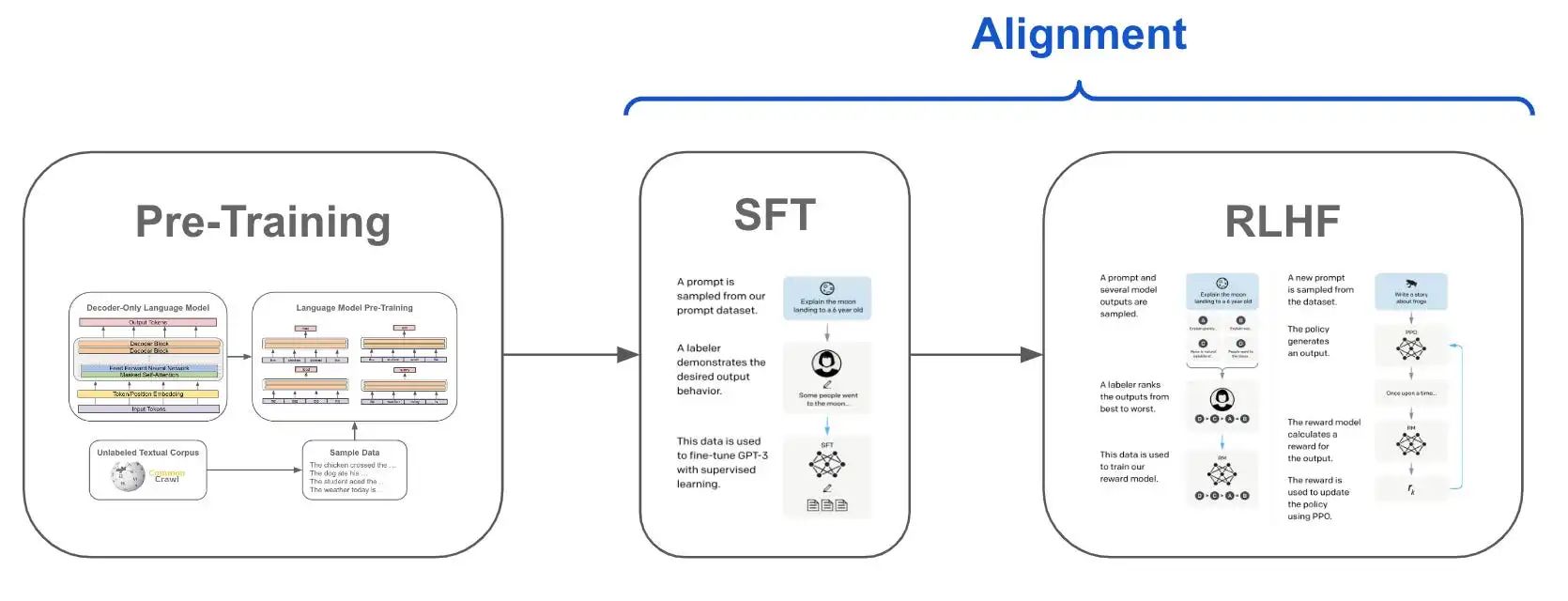
监督微调(SFT)
定义:在新任务的小规模标注数据集上,使用有监督学习的方法对预训练模型进行微调,以使其适应新任务。
步骤:加载预训练模型 → 准备新任务的数据集 → 调整模型输出层 → 在新任务数据集上训练模型。
应用:适用于那些有明确标注数据集的任务,如文本分类、命名实体识别等。
基于人类反馈的强化学习微调(RLHF)
定义:在SFT的基础上,通过强化学习和人类反馈来进一步微调模型,使其输出更加符合人类的偏好或期望。
步骤:首先进行SFT → 收集人类反馈数据 → 训练奖励模型 → 使用奖励模型指导强化学习过程来微调模型。
应用:适用于那些需要高度人类判断或创造力的任务,如对话生成、文本摘要等。