知识蒸馏的原理与实现
1.什么是模型蒸馏
在工业级的应用中, 除了要求模型要有好的预测效果之外, 往往还希望它的"消耗"足够小. 也就是说一般希望部署在线上的应用模型消耗较小的资源. 这些资源包括存储空间, 包括算力.
在深度学习背景下, 如果希望模型的效果足够好, 通常会有两种方案: - 使用更大规模的参数. - 使用集成模型, 将多个弱模型集成起来.
注意: 上面两种方案往往需要较大的计算资源, 对部署非常不利. 由此产生了模型压缩的动机: 我们希望有一个小模型, 但又能达到大模型一样或相当的效果.
模型蒸馏是一种通过将一个复杂模型(教师模型)的知识转移给一个简单模型(学生模型)的方法,以提高学生模型的性能。在减小模型体积的同时,保持或提升模型性能。 - 知识蒸馏的概念最早由Hinton在2015年提出, 在2019年后火热起来. - 知识蒸馏在目前已经成为一种既前沿又常用的提高模型泛化能力和部署优势的方法.
2.知识蒸馏的原理和算法
2.1 教师模型
- 定义: 复杂的、高性能的模型,通常是大型深度神经网络。
- 特点: 参数量大,能够学习复杂的特征和关系。
2.2 学生模型
- 定义: 简化的、小型的模型,通常是教师模型的子集。
- 特点: 参数量较小,适用于资源受限的场景。
2.3 蒸馏过程
下图非常直观, 又经典的展示了知识蒸馏的架构图, 相当于有两部分的分支: * 一部分是大模型的softmax分布作为"知识标签", 让小模型去学习. * 一部分是真实label(ground truth)作为"真实标签", 让小模型去匹配.
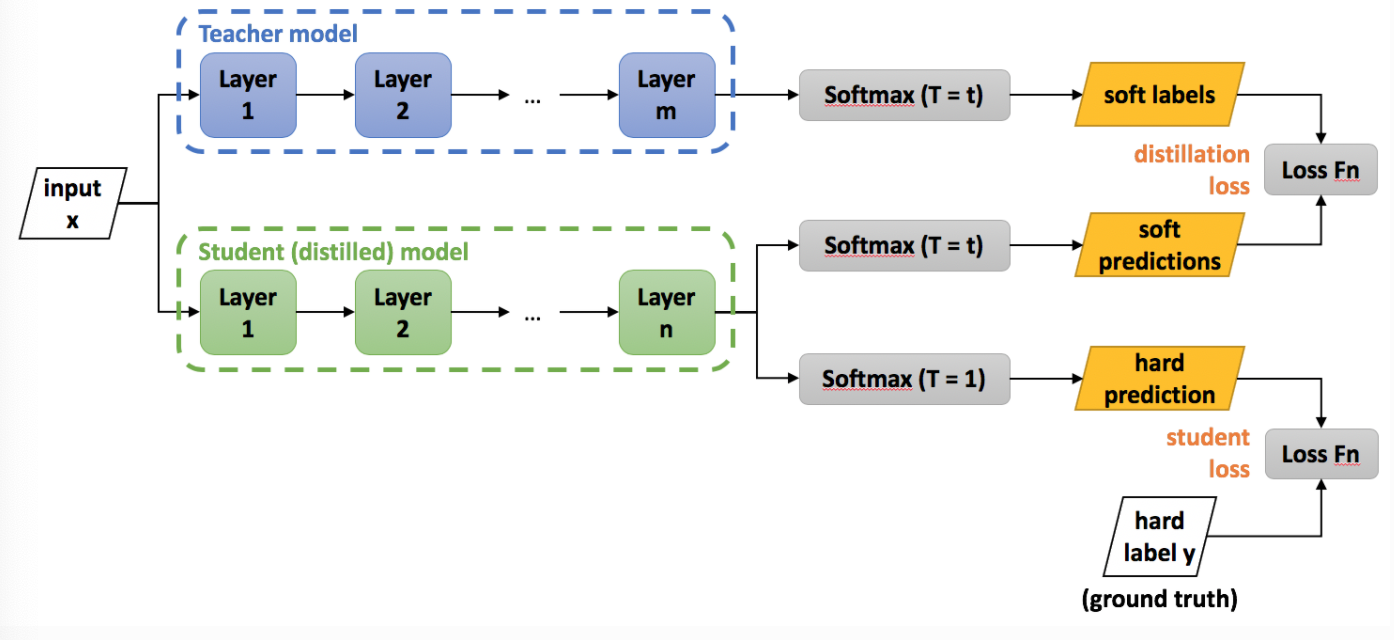
我们对知识蒸馏进行公式化处理: 先训练好一个精度较高的Teacher网络(一般是复杂度较高的大规模预训练模型), 然后将Teacher网络的预测结果q作为Student网络的"学习目标", 来训练Student网络(一般是速度较快的小规模模型), 最终使得Student网络的结果p接近于q. 损失函数如下:
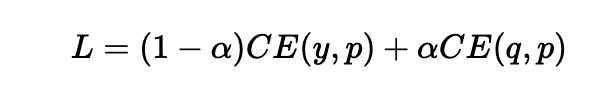
- 上式中CE是交叉熵(Cross Entropy), y是真实标签, q是Teacher网络的输出结果, p是Student网络的输出结果.
原始论文中提出了softmax-T公式来计算上图中的q:
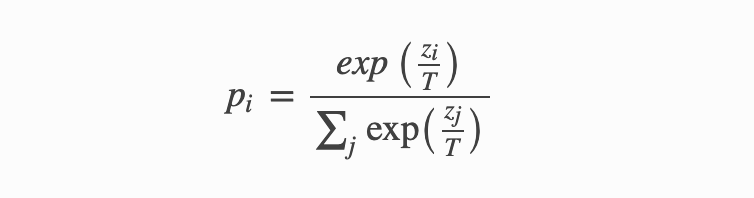
- 上式中pi是Student网络学习的对象, 也就是所谓的软目标(soft targets), zi是神经网络softmax前的输出logits.
不同的温度系数T值, 对softmax-T算法有不同的影响, 总结如下: - 如果将T值取1, softmax-T公式就成为softmax公式, 根据logits输出各个类别的概率. - 如果T越接近于0, 则最大值会越接近1, 其他值会接近0, 类似于退化成one-hot编码. - 如果T越大, 则输出的结果分布越平缓, 相当于标签平滑的原理, 起到保留相似信息的作用. - 如果T趋于无穷大, 则演变成均匀分布.
3.模型蒸馏的代码实现----详细代码见github
工具类函数的路径为:
1 | |
导入工具包如下:
1 | |
3.1 工具类函数build_vocab()
build_vocab()是位于utils.py中的独立函数,用于将文本数据中的单词映射为索引。函数的主要步骤如下:
- 初始化:
函数开始时定义了三个特殊符号(
UNK,PAD,CLS),它们分别代表未知符号、填充符号和综合信息符号。这些符号在构建词汇表时将被添加。 - 遍历文本文件: 函数通过打开指定路径的文本文件,逐行遍历文件中的内容。每行通常包含一段文本,这里选择每行的第一个字段作为内容。
- 分词和构建词汇表: 对每个内容使用给定的分词器进行分词,然后更新词汇表字典。分词的结果是将文本划分为单词或子词,而词汇表字典则记录了每个单词出现的次数。
- 筛选高频词汇:
对词汇表字典根据词频进行排序,选择出现频率较高的词汇。这里根据参数
min_freq指定的最小出现频率进行筛选。 - 构建最终词汇表:
将选定的高频词汇构建为字典,将每个词汇映射到一个唯一的索引。此外,函数还将特殊符号(
UNK,PAD,CLS)添加到词汇表中,分别赋予它们额外的索引。 - 返回结果: 返回构建好的词汇表字典,其中每个词汇都与一个唯一的索引相关联。这个词汇表后续可用于将文本数据转换为模型可接受的输入形式,即将文本中的每个单词映射为对应的索引。
具体实现如下所示:
1 | |
3.2 工具类函数build_dataset_CNN()
build_dataset_CNN()是位于utils.py中的独立函数,用于创建专为text_cnn模型设计的数据集。以下是代码的主要作用:
d_dataset_CNN
的函数,用于创建专为卷积神经网络(CNN)模型设计的数据集。以下是代码的主要作用:
- 分词(Tokenization):定义了一个简单的字符级分词器,将每个输入文本转换为单个字符的列表。
- 构建词汇表(Vocabulary Building):
函数首先检查是否存在指定路径 config.vocab_path
下的词汇表文件。如果存在,则加载词汇表;否则,使用训练数据构建新的词汇表。
- 加载数据集(Dataset Loading):
load_dataset 是 build_dataset_CNN
内部的辅助函数,用于从给定文件(训练、验证、测试)加载数据集。
- 数据集拆分(Dataset Splitting):
函数通过在相应文件路径上调用 load_dataset
来加载训练、验证和测试的数据集,并返回。
具体实现如下所示:
1 | |
3.3 其他工具类函数
其他工具类函数build_dataset(), build_iterator(),get_time_dif()都位于utils.py中的独立函数,这些函数与Bert模型章节是一样的,不再赘述。
4.模型类
4.1 Teacher模型
Teacher模型采用BERT,接下来实现一个基于BERT的文本分类模型,并包含了相关的配置信息。该部分代码在:
1 | |
主要内容包含:
配置类 Config:和模型类 Model:
首先导入工具包:
1 | |
1 实现Config类代码
配置类 Config中主要包含以下内容:
Config类包含了用于模型训练和数据处理的各种参数。- 定义了模型名称、数据集路径、训练集、验证集、测试集文件路径、类别名单等信息。
- 包含模型训练结果和量化模型存储结果的路径。
- 配置了训练设备(GPU或CPU)、类别数、epoch数、mini-batch大小、句子长度等。
- BERT预训练模型的路径、分词器、BERT模型配置、隐藏层大小等。
1 | |
2.实现Model类代码
模型类 Model主要实现以下内容:
Model类继承自nn.Module,实现了一个基于BERT的文本分类模型。- 在初始化方法中,加载预训练的BERT模型和配置,并定义了一个全连接层用于文本分类。
- 在前向传播方法中,通过BERT模型获取句子的表示,然后通过全连接层进行分类
1 | |
bert.py文件提供了一个简单而灵活的BERT文本分类模型,通过配置类可以方便地调整模型参数,适应不同的文本分类任务,通过model类构建整个网络结构。
4.2 Student模型
Student模型采用textCNN,接下来实现一个基于textCNN的文本分类模型,并包含了相关的配置信息。该部分代码在:
1 | |
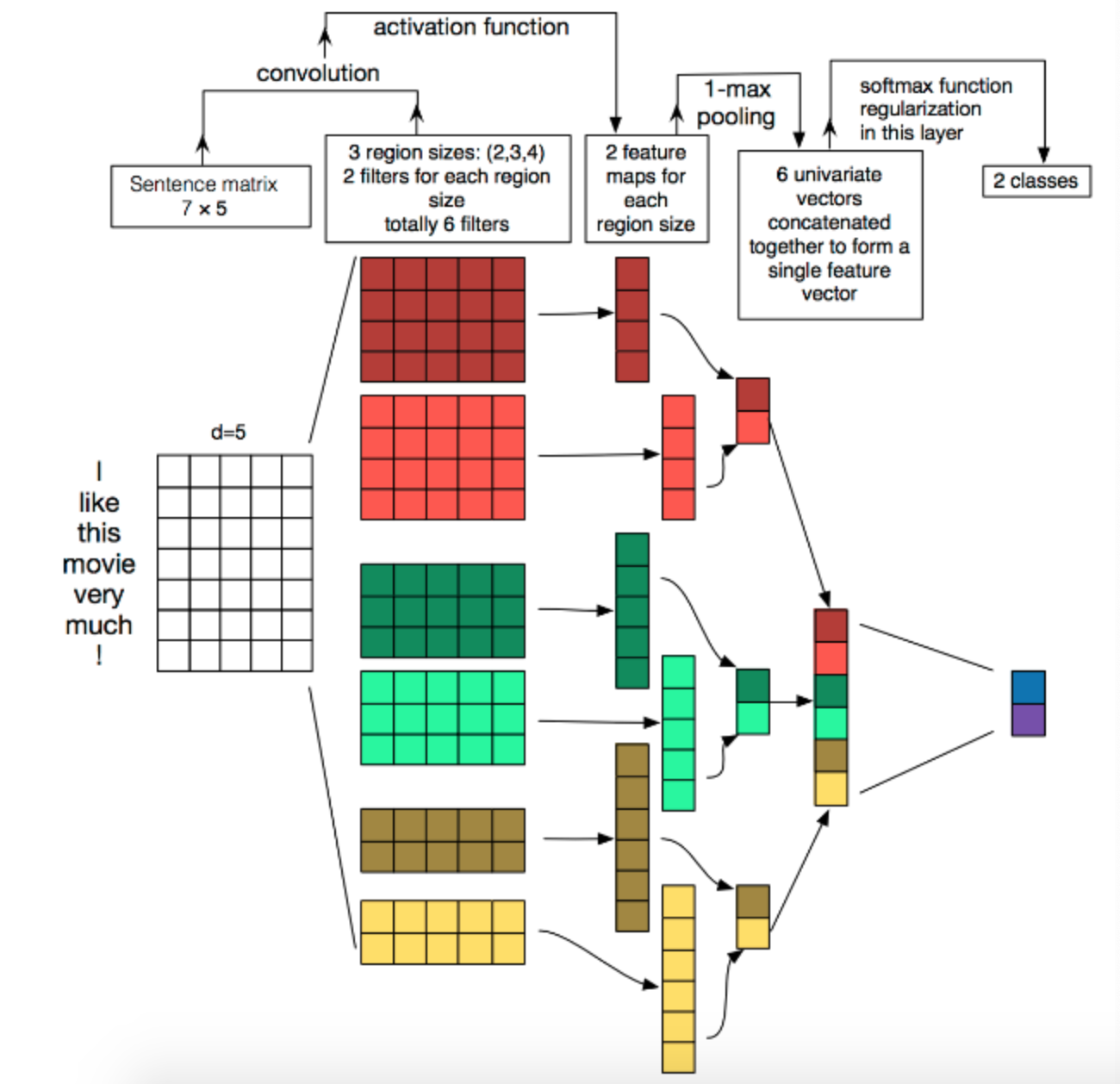
首先看textCNN模型的架构图:
导入相关的工具包:
1 | |
1.实现Config类代码
config配置类用于设置存储模型的各种参数和路径。包括数据集的路径、模型保存路径、设备选择、超参数等。
1 | |
2.实现Model类代码
TextCNN(卷积神经网络用于文本分类)模型包含词嵌入层、多个卷积核大小的卷积层、池化层、随机失活层和全连接层。其中,卷积层通过不同大小的卷积核捕捉不同范围的文本信息,随机失活层用于防止过拟合,全连接层用于输出最终的分类结果。包含以下三个方法:
__init__方法: 初始化模型。它包括词嵌入层,多个卷积层,池化层,随机失活层和全连接层。conv_and_pool方法: 定义卷积和池化的操作。ReLU激活函数应用于卷积输出,然后通过最大池化层进行池化。forward方法: 定义前向传播逻辑。通过词嵌入层将输入文本序列转换为嵌入表示,然后应用多个卷积核并进行池化。最后,通过全连接层生成最终的分类结果。
具体实现如下:
1 | |
5.编写训练函数,测试函数,评估函数
这几个函数共同编写在一个代码文件中:
1 | |
首先导入相关的工具包:
1 | |
在具体实现之前,我们先看下训练的架构图:
以下是模型蒸馏的基本训练步骤:
- 准备教师模型(bert大模型): 使用一个较大的模型进行训练, 这个模型在任务上表现很好。
- 使用教师模型生成软目标: 对训练数据集进行推理,得到教师模型的输出概率分布(软目标)。这些概率分布包含了模型对每个类别的置信度信息。
- 准备学生模型(textcnn小模型): 初始化一个较小的模型,这是我们要训练的目标模型。
- 使用软目标和硬标签进行训练: 使用原始的硬标签(实际标签)和教师模型生成的软目标来训练学生模型。损失函数由两部分组成:
- 硬标签损失(通常为交叉熵损失): 学生模型的输出与实际标签之间的差距。
- 软目标损失: 学生模型的输出与教师模型生成的软目标之间的差距。这通常使用 KL 散度(Kullback-Leibler Divergence)来度量。
- 调整温度参数: KL 散度的计算涉及一个温度参数,该参数可以调整软目标的分布。温度较高会使分布更加平滑。在训练过程中,可以逐渐降低温度以提高蒸馏效果。
通过这个过程,学生模型可以通过教师模型的知识进行训练,达到在小模型上获得类似大模型性能的目的。模型蒸馏在资源受限的环境中特别有用,例如移动设备或边缘设备上。
5.1 获取Teacher网络输出的函数
使用Bert作为Teacher模型, 需要用Bert对全部训练数据做预测, 并将结果预先存储进一个list中. 这些预测结果就是soft targets, 未来给Student模型做"学习标签"使用.具体步骤如下所示:
- 将教师模型设置为评估(推断)模式,通过
teacher_model.eval()实现。在评估模式下,模型不会计算梯度,这有助于提高推断速度并减少内存消耗。 - 创建一个空列表
teacher_outputs,用于存储教师模型对训练集每个批次的输出。 - 遍历训练集迭代器
train_iter,对每个批次的数据调用教师模型,获取模型的输出。 - 将每个批次的输出添加到
teacher_outputs列表中。 - 最后,返回包含教师模型对训练集所有批次输出的结果。
具体实现如下所示:
1 | |
需要注意的是Teacher模型和Student模型的DataLoader不是同一个, batch_size和顺序都要保持一致, 才能保证后续的训练样本与soft targets对齐!
5.2 损失函数

通常采用的交叉熵损失函数, 有一点需要注意, F.cross_entropy()对输入有限制, 要求label必须是one-hot格式的. 但Teacher网络的输出soft targets是概率分布的形式, 不匹配,因此采用KL散度作为soft targets的loss, 注意: Pytorch中的KL散度函数可以接收概率分布形式的label.包含的步骤是:
loss_fn是用于一般的交叉熵损失函数,适用于训练 BERT 模型。criterion是定义 KL 散度损失的 PyTorch 损失类。loss_fn_kd是蒸馏损失函数,用于蒸馏训练。它接受三个参数:outputs(学生模型的输出),labels(真实标签),teacher_outputs(教师模型的输出)。- 设置两个超参数:
alpha控制软损失和硬损失的权重,T是温度参数,影响软化的程度。 - 计算学生模型(Student)的输出分布值和教师模型(Teacher)的输出分布值。对学生模型的输出进行 log_softmax 处理,对教师模型的输出进行 softmax 处理。
- 计算软损失,即学生模型和教师模型的输出分布之间的 KL 散度损失。
- 计算硬损失,即学生模型和真实标签的交叉熵损失。
- 计算总损失,通过加权软损失和硬损失得到。
具体实现如下所示:
1 | |
5.3 Teacher模型训练函数
该部分的内容与Bert模型章节的训练函数是类似的,具体步骤包含以下内容:
- 初始化训练开始时间,将模型设置为训练模式。
- 对模型参数进行优化,使用AdamW优化器,同时设置不同参数组的权重衰减。
- 迭代训练,每个epoch内遍历训练集。在每个batch内,进行前向传播、损失计算、反向传播和参数更新。
- 每400个batch,打印一次训练信息,并在验证集上进行评估。判断当前模型是否是最佳模型,如果是则保存。
- 训练完成后,在测试集上进行最终测试。
具体实现如下所示:
1 | |
5.4 知识蒸馏训练函数
使用知识蒸馏(Knowledge Distillation)的方式训练深度学习模型的训练函数完成的任务如下所示:
- 初始化优化器和其他训练参数,将CNN模型设置为训练模式,BERT模型设置为评估模式。
- 获取BERT模型的输出,作为教师模型的预测结果。
- 遍历每个epoch,对CNN模型进行训练。计算蒸馏损失(软损失)和交叉熵损失(硬损失)的组合,并进行反向传播和优化。
- 在训练过程中输出训练信息,包括训练损失、准确率以及在验证集上的表现。保存在验证集上表现最好的CNN模型。
- 在训练结束后,使用测试集对最终的CNN模型进行测试。
具体的实现如下所示:
1 | |
5.5 评估函数和测试函数
评估函数和测试函数的实现与bert章节是一样的,这里不再赘述。
1 | |
6.编写运行主函数
该部分代码在
1 | |
中,用于训练深度学习模型(BERT或使用知识蒸馏的TextCNN)。具体任务是通过命令行参数
--task
指定的方式进行,可以选择训练BERT模型(trainbert)或者训练使用知识蒸馏的TextCNN模型(train_kd)。
执行过程如下:
- 根据命令行参数选择任务,如果是
trainbert,则加载BERT模型进行训练;如果是train_kd,则加载BERT模型作为教师模型,加载TextCNN模型作为学生模型,进行知识蒸馏训练。 - 初始化相关配置,包括随机种子等。
- 加载数据集,对于
trainbert任务,加载BERT数据集;对于train_kd任务,加载TextCNN的数据集和BERT的训练数据集。 - 加载模型,对于
trainbert任务,加载BERT模型;对于train_kd任务,加载BERT和TextCNN模型。 - 执行训练,对于
trainbert任务,调用train函数;对于train_kd任务,调用train_kd函数。
此脚本的设计使得可以方便地选择不同的任务,并在一个脚本中完成相应模型的训练过程。
具体实现如下所示:
1 | |
6.1 训练Teacher模型
执行训练Teacher模型,如下所示:
1 | |
- 输出结果:
1 | |
- 结论: Teacher模型在测试集上的表现是Test Acc: 93.64%
6.2 训练Student模型
设定Config中的重要参数如下:
1 | |
执行run文件
1 | |
- 输出结果:
1 | |
- 结论: Student模型在测试集上的表现是Test Acc: 89.89%
6.3 调参训练Student模型
- 对Config类中的若干超参数做出重要修改:
1 | |
- 调参后再次训练Student模型:
1 | |
- 输出结果:
1 | |
结论: 调参后的Student模型在测试集上的表现是Test Acc: 91.25%
完成知识蒸馏后, 我们获得了两个模型, Teacher模型和Student模型:

从上述结果中可以看出:
Teacher模型大小为409.2MB, Student模型大小为11.3MB和23.1MB.
Teacher模型测试集准确率为93.64%, Student模型测试集准确率为89.89%和91.25%.
7.结论
模型进行知识蒸馏后模型大小和准确率的变化:
1、模型大小明显减少.
- BERT模型409.2MB, 最优的textCNN模型23.1MB.
- 模型大小压缩为原来的5.65%, 缩小了17.7倍.
2、模型在测试集上准确率仅有2.39%的下降.
- BERT模型准确率93.64%
- textCNN模型知识蒸馏后30个epochs准确率91.25%