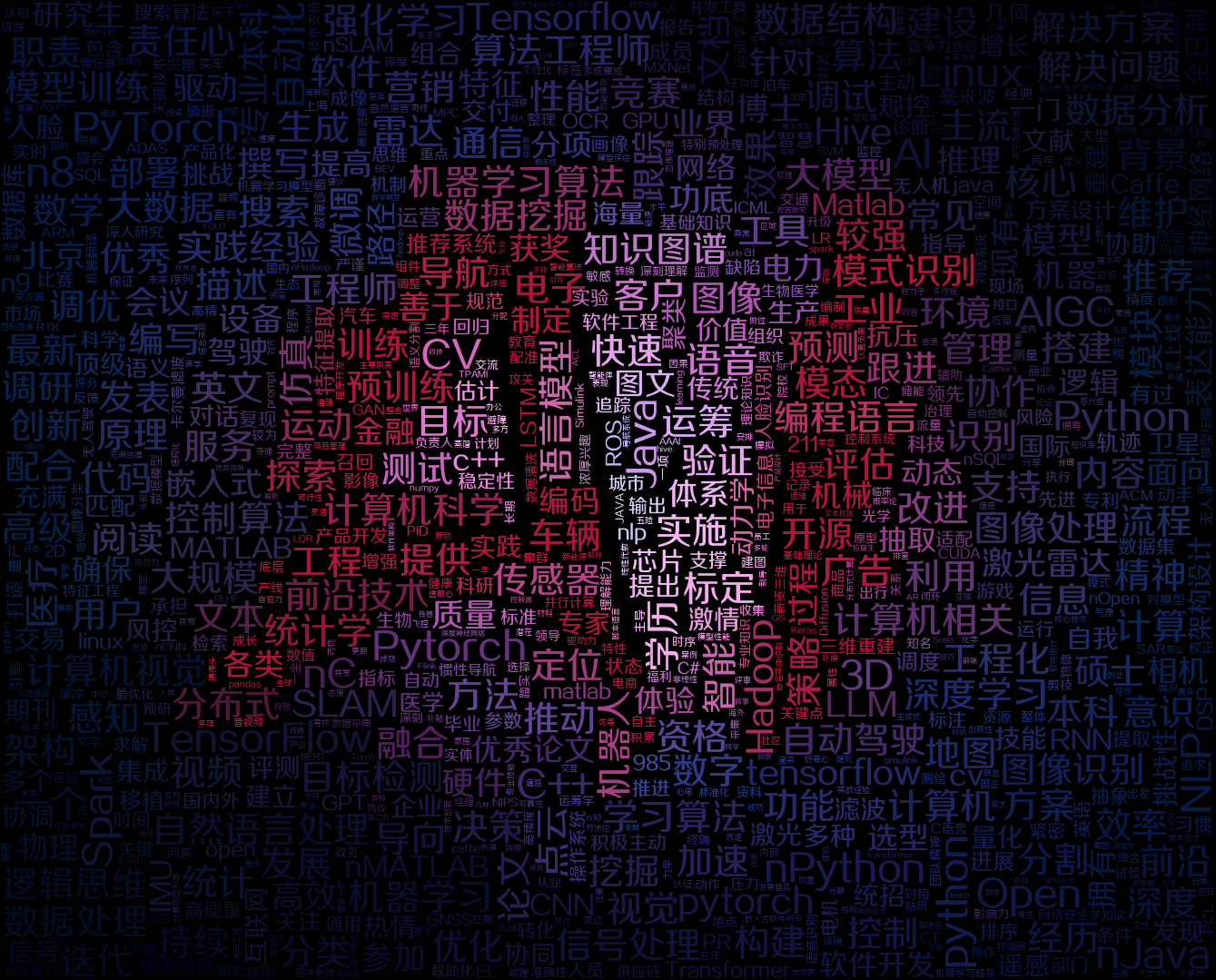用wordcoloud生成超炫酷的词云_内含python源码
使用jieba分词,wordcoloud词云可视化
 环境准备 pip 安装jieba库,wordcloud库与scipy库
资料准备
环境准备 pip 安装jieba库,wordcloud库与scipy库
资料准备
不废话,直接上码 ### 1.用结巴分词,生成字典对象 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import jieba
from collections import Counter
import wordcloud
# 读取文件
with open("词频统计_AIjob.csv", "r", encoding="utf-8") as f:
desc = f.read()
# 加载停用词列表
stop_words = []
with open("stopwords.txt", "r",encoding='utf-8') as f:
for line in f:
stop_words.append(line.strip())
jieba.load_userdict("人工智能词汇.txt")
# 分词
words = jieba.cut(desc, cut_all=False)
# 过滤停用词
filtered_words = []
for word in words:
if word not in stop_words and len(word) > 1:
filtered_words.append(word)
# 统计词频
word_counts = Counter(filtered_words)
w100=word_counts.most_common(500)
# 使用字典推导将列表转换为字典
dict_result = {key: value for key, value in w100} 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from scipy.ndimage import gaussian_gradient_magnitude
from wordcloud import WordCloud, ImageColorGenerator
def pic_wordcloud(dict_result,img_path,out_path):
# img_path=r"E:\jupyter\spyder\bosszhipin\词频统计\pic\T1.jpg"
parrot_color = np.array(Image.open(img_path))
parrot_color = parrot_color[::3, ::3]
# create mask white is "masked out"
parrot_mask = parrot_color.copy()
parrot_mask[parrot_mask.sum(axis=2) == 0] = 255
edges = np.mean([gaussian_gradient_magnitude(parrot_color[:, :, i] / 255., 2) for i in range(3)], axis=0)
parrot_mask[edges > .08] = 255
# acurately but it makes a better picture
wc = WordCloud(max_words=1000, mask=parrot_mask, max_font_size=40, random_state=42, font_path=r"C:\Users\10921\AppData\Local\Microsoft\Windows\Fonts\方正正准黑简体.ttf",relative_scaling=0,
#width=1920, height=1080
)
# generate word cloud
wc.generate_from_frequencies(dict_result)
# plt.imshow(wc)
# create coloring from image
image_colors = ImageColorGenerator(parrot_color)
wc.recolor(color_func=image_colors)
# plt.figure(figsize=(10, 10))
# plt.imshow(wc, interpolation="bilinear")
# wc.to_file("parrot_new.png")
wc.to_file(out_path)
img_path="mask.jpg"
out_path='output.png'
pic_wordcloud(dict_result,img_path,out_path)