NER与关系抽取任务——关系三元组抽取问题中常用的模型
文本关系抽取的研究工作本身可以划分为很多类别,根据抽取的文本范围以划分为句子级关系抽取、文档级关系抽取和语料级关系抽取;数据集中样本的多少可以划分为正常关系抽取、少样本关系抽取和零样本关系抽取;根据是否定义关系类别和抽取领域可以划分为限定域关系抽取和开放域关系抽取;本文中的关系抽取方法内容仅关注限定域关系抽取中的句子级关系抽取。
本文关注的工作主要是关系三元组抽取(Relational Triple Extraction,RTE)问题,即从文本中同时抽取两个实体及其对应的关系,三元组可以表示为 ( Subject, Relation, Object)或 (Subject, Prodicate, Object),其中 Subject 和 Object 为两个实体,也可以分别叫头实体(Head Entity)和尾实体(Tail Entity), Relation 和 Prodicate 表示关系类别。
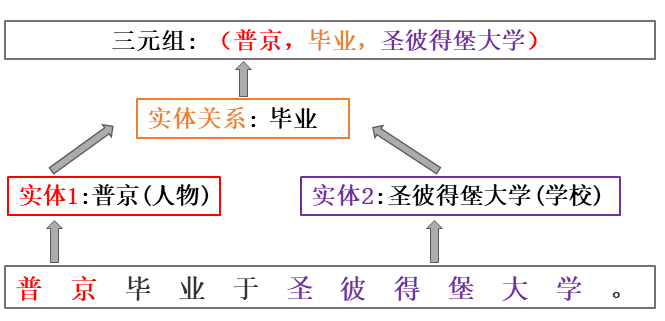
关系三元组抽取示意图
一. RTE常见问题
1. Pipeline & Joint
- Pipeline管道模型
早期,RTE任务被分解成两个独立任务的级联,也就是Pipeline模式:首先是命名实体识别(Named Entity Recognition, NER),即提取出文本中所有的实体;然后是关系分类(Relation Classifification, RC),即预测判断提取的实体之间是否存在某种关系。
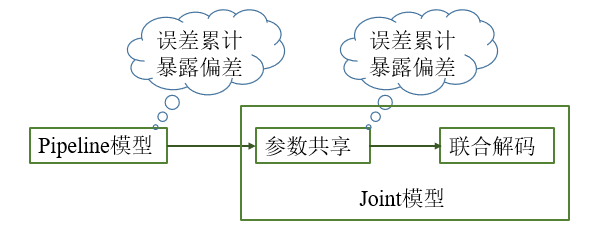
Pipeline模型明显的一个缺点是存在误差传递问题(Error Propagation Problem),这是由于实体抽取和关系分类两个模型相互独立,不存在依赖,实体抽取阶段的识别错误、遗漏等误差无法被纠正和改变,会直接传递影响到关系分类阶段的效果。
- Joint联合模型
不同于Pipeline模型,Joint模型以减少误差传递为目的将实体抽取和关系分类通过一定的方式进行整合,联合学习两个任务,构建端到端的关系抽取模型,当前的Joint模型主要有以下两类:
① 参数共享:本质上是多任务学习,实体识别和关系抽取共享encoder,使用不同的decoder, 并构建联合loss训练优化。
② 联合解码:这一类也可称为Structured prediction,将实体识别和关系抽取两个任务映射在统一的框架结构下,进行全局的优化以及联合解码,即解码不存在多步(multi-steps),而是一步(one-step)完成。
- Pipeline VS Joint
最早的Pipeline模型存在明显的误差累积问题,为了解决实体和关系两个任务模型独立和误差累计问题,许多研究提出了基于参数共享的联合模型,虽然通过多任务学习和联合优化的方式增加了两个任务的关联,但本质还是multi-steps的模型,仍然没有解决误差传递的问题。另一方面,这些模型还存在一个问题,就是暴露偏差(Exposure Bias Problem)。为了解决误差传递和暴露偏差问题,许多研究提出了基于联合解码的联合模型,特别是以TPLinker为代表的一系列Table filling方法。
暴露偏差: 在训练时使用标注好真实的实体件进行最终的关系提取和推断,而在测试推理时,则需要从头开始识别实体,即上一阶段的实体是由构建的模型预测的并且存在错误和噪声,但训练使用的是标注的正确的,这就造成了训练和推理阶段之间的gap
研究从Pipeline到Joint模型,2021年PURE模型的提出打破了许多研究长期认为的联合模型能够更好的捕捉实体和关系间的交互并缓解误差传播问题的观念,在PURE之前大多数研究都关注于联合模型,但是PURE证明了联合模型不一定真的比Pipeline模型性能好。因此,Pipeline和Joint哪个更好肯定要看实际的任务和数据。
2. 关系重叠
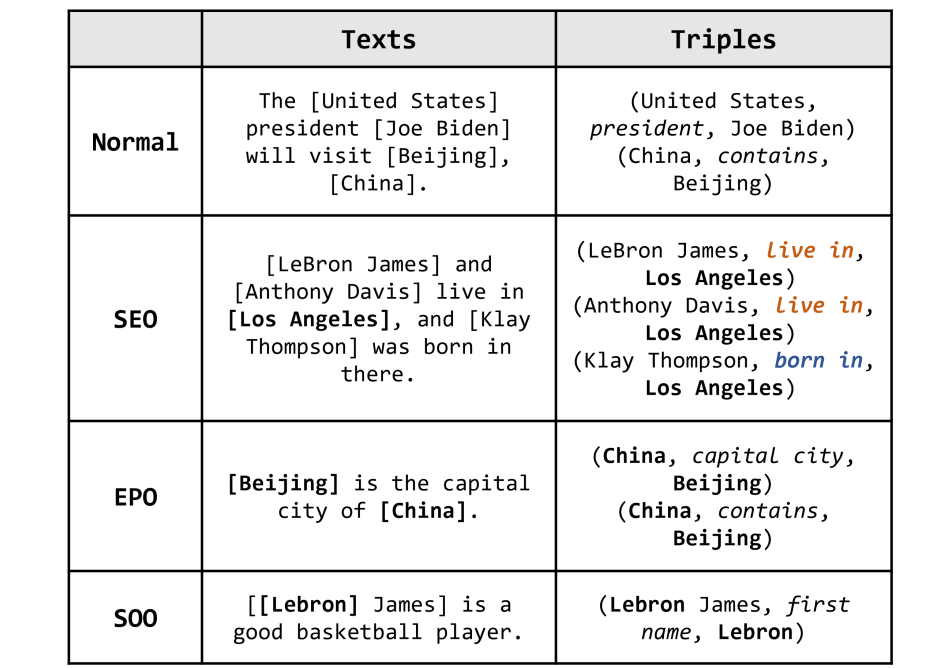
关系抽取过程中除了模型本身存在的误差传递和暴露偏差问题外,还面临着文本中复杂的关系重叠问题,文本中的复杂关系重叠可以分为以下三类,许多模型设计来解决以下问题。
- SEO (Single Entity Overlap) :多个实体与同一实体存在关联关系
- EPO (Entity Pair Overlap) :同一对实体存在多种关系
- SOO (Subject Object Overlap) : 主体和客体实体重叠
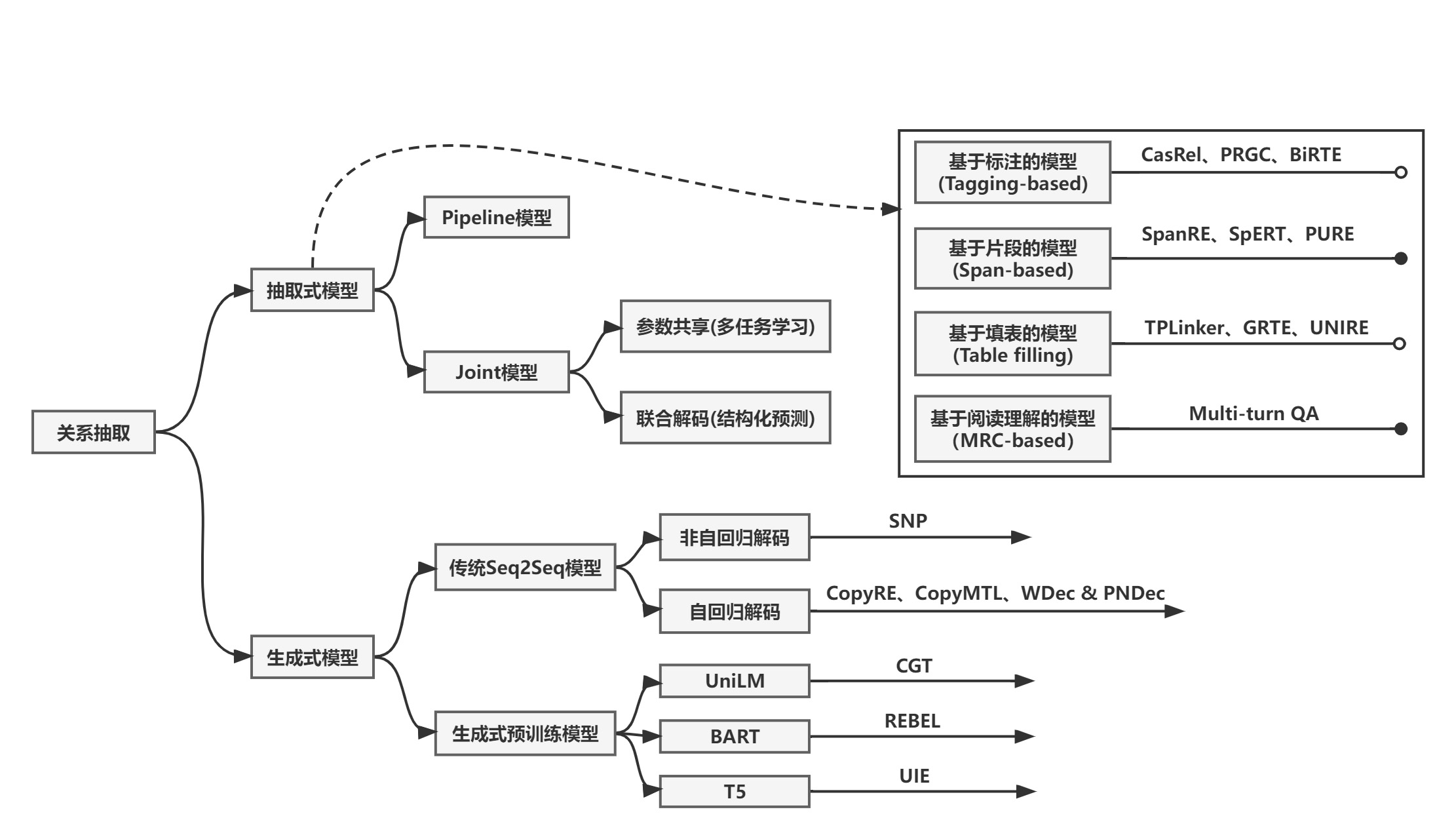
二. RTE方法总结
在该部分总结归纳了几个关系抽取的模型范式,关系抽取的算法模型非常多,在这里主要关注最近几年的基于预训练模型的研究工作,本文列举的模型都是一些有代表性的工作,还有的许多相关的研究并未列出。
现有的关系抽取工作中可以分为抽取式模型和生成式模型,抽取式模型中又可分为Pipeline模型和Joint模型,下面列出的工作是通过各种抽取方法范式归类的,包括基于标注、基于片段、基于填表、基于阅读理解的抽取式方法,以及生成式方法。
1. 基于标注的方法(Tagging based methods)
基于标注的方法通常使用二分标注序列(binary tagging sequences)来确定实体的起始位置,或者确定实体之间的关系。
1.1 CasRel
ETL-Span: Joint Extraction of Entities and Relations Based on a Novel Decomposition Strategy, ECAI 2020
CasRel: A Novel Cascade Binary Tagging Framework for Relational Triple Extraction, ACL 2020
常见的关系抽取模式是先抽取实体,然后在对实体对进行关系分类预测,可表示为𝑓(𝑠,𝑜)→𝑟;ETL-Span和CasRel两个模型采用了与之不同的模式:先抽取subject实体,然后在subject基础上同时抽取关系relation及其对应的object实体,即𝑓𝑟(𝑠)→𝑜 。
下图为CasRel的模型结构图,CasRel抽取三元组的具体流程如下:
① BERT编码:将输入的文本经过BERT编码获得文本token序列的隐层表示 ℎ∈𝑅𝑛×𝑑 ;
② Subject标注:该模块识别输入文本中所有可能的subjects,它利用两个独立的二分类器为每个token分配一个二分标签(0/1)来分别检测subject的开始和结束的位置,其中0和1标签分别表示当前token是否是一个subject的开始或结束的位置 ;
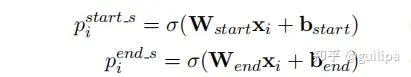
③ 关系特定的Object标注:该标注模块能够在subject实体基础上识别 object实体及两个实体间的关系,通过为每个关系 𝑟 学习特定的二分标注器𝑓𝑟(⋅)来识别subject在特定关系 𝑟 下可能对应的object起始位置,即𝑓𝑟(𝑠)→𝑜 ;
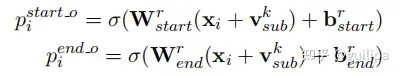
其中, 𝑣𝑠𝑢𝑏𝑘 为步骤②提取的subject的向量表示,通过将subject起止范围 [𝑝𝑖𝑠𝑡𝑎𝑟𝑡_𝑠,𝑝𝑖𝑒𝑛𝑑_𝑠] 内token表示进行mean pooling得到。
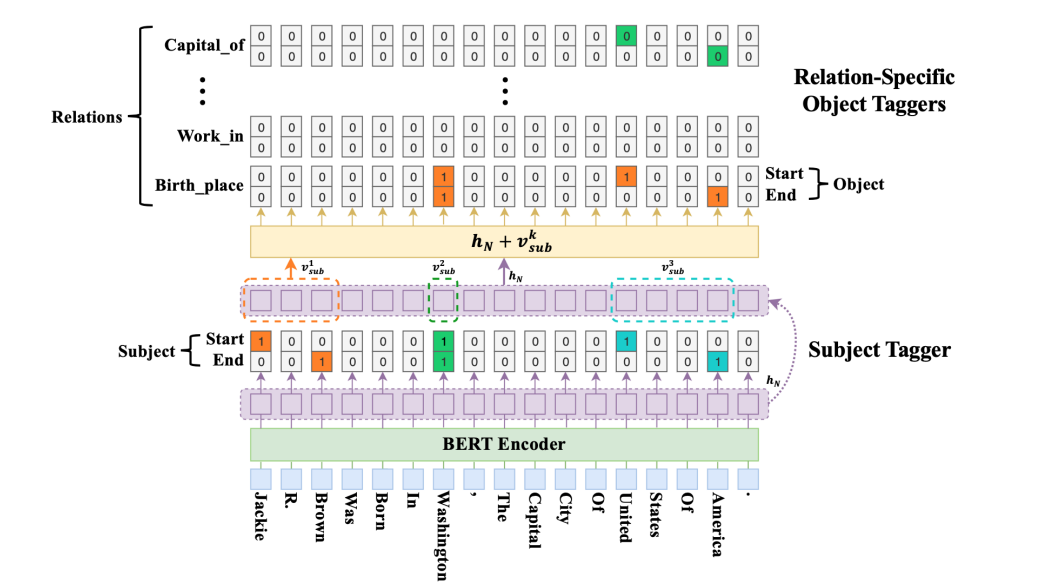
CasRel模型结构图
优点:
- CasRel原论文模型能够解决SEO和EPO三元组重叠问题,SOO问题理论上也是能够解决的,需要注意修改模型中subject和object的位置关系约束和判断部分代码。
缺点:
- 存在误差传递和暴露偏差问题,因为CasRel仍然是Pipeline的提取模式,subject提取存在的错误和遗漏直接影响后续的关系预测和object的提取。
- 存在关系冗余和计算效率低的问题,假设有N个关系类别,在获取subject之后,每个subject需要计算每个关系下可能对应的object,需要进行2*N次二分类计算,若关系类别较多,由于许多冗余的关系则会导致过多的计算,影响计算效率。
- 训练和测试过程也存在效率低的问题,在CasRel训练过程中每个文本即使有多个subjects也只随机取样其中的一个subject和其对应的三元组作为一个训练样本,这样训练过程中不能对同一文本中所有三元组进行一次性的学习,而且训练的epoch会很大,论文中作者表示通过充分的训练训练集中每个三元组样本均会被采样学习到;同时在测试过程中由于每个文本中的三元组数目是不固定的,CasRel这种抽取模式下batch size需要设置为1。
1.2 PRGC
PRGC: Potential Relation and Global Correspondence Based Joint Relational Triple Extraction, ACL 2021
PRGC是针对上面提到的CasRel模型和章节3.1中介绍的TPLinker模型存在的问题进行改进的,上面也提到了CasRel由于关系冗余使得很多操作无效,它的subject-object对齐提取机制使其一次只能处理一个subject,实际上效率低并难以部署应用;而TPLinker仍然存在关系冗余和扩展性差的问题,同时TPLinker使用了更复杂的解码部分导致解码的标签稀疏和收敛速度慢。针对这些问题,PRGC提出一个新的端到端的框架,将三元组联合抽取分解成了三个子任务:关系判断、实体抽取和subject-object对齐。
下图为PRGC的模型结构图,PRGC抽取三元组的具体流程如下:
① Potential Relation Prediction:给定一个文本经过BERT编码得到序列表示 ℎ∈𝑅𝑛×𝑑 ,首先判断预测句子中可能存在的关系集合, 这样可以过滤无关的关系,减少计算
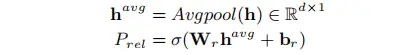
② Relation-Specifific Sequence Tagging:判断句子中潜在的关系后,针对每个关系进行两次独立的序列标注操作,分别提取subjects和objects,subjects和object独立提取能够subject和object重叠(*SOO*)问题,标注采用的是BIO标注方式;同时在标注过程中对每个token向量加入了关系向量,识别在特定关系下的实体
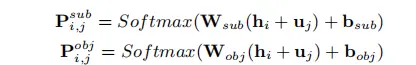
③ Global Correspondence:针对某一类关系提取除了句子中所有可能的subjects和objects后,使用一个全局关联矩阵 𝑀𝑛×𝑛 来确定正确的subject-object对
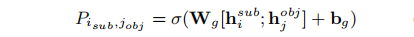
上式中 ℎ𝑖𝑠𝑢𝑏 和ℎ𝑗𝑜𝑏𝑗分别为两个第 𝑖 个和第 𝑗 个token经过BERT编码的向量表示
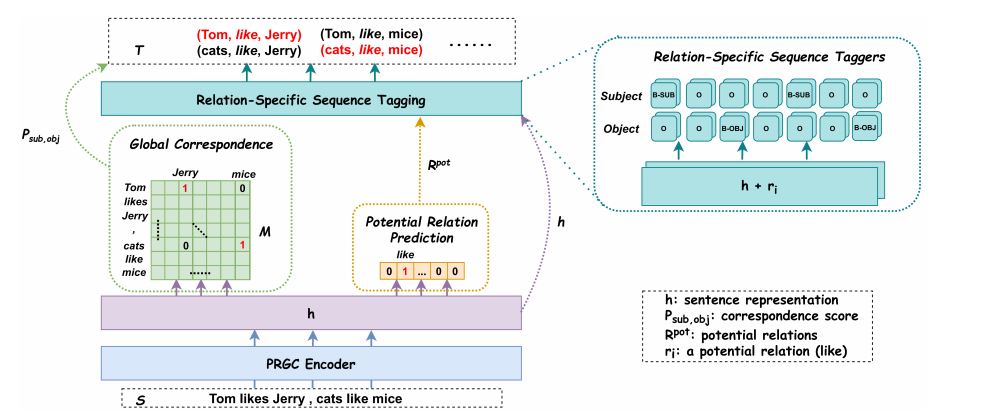
PRGC模型结构图
优点:
- PRGC模型能够解决SEO、EPO和SOO三元组重叠问题
- 模型计算效率以及模型训练测试效率较CasRel模型有了很大的提升,因为关系判断阶段可以过滤无关的关系,同时提取模式的改变,使得训练测试阶段能够批量进行
缺点:
- 存在误差传递和暴露偏差问题,因为PRGC也是Pipeline的提取模式,而且解码还是经过了三步,关系判断和实体提取两个部分的错误、遗漏等问题都会导致最终三元组提取的精度。
1.3 BiRTE
BiTE: A Simple but Effective Bidirectional Framework for Relational Triple Extraction, WSDM 2022
BiTE模型是针对CasRel改进的,CasRel将提取过程分为了两步,首先提取所有的subjects,然后同时抽取所有的objects和关系,即无向的抽取模式𝑠𝑢𝑏𝑗𝑒𝑐𝑡→𝑜𝑏𝑗𝑒𝑐𝑡→𝑟𝑒𝑙𝑎𝑡𝑖𝑜𝑛,但是这种模式存在的问题是误差传递,即一个subject抽取失败,那么与这个subject相关联的所有三元组都无法抽取成功。
BiTE设计了一个双向的提取框架,首先模型从 𝑠𝑢𝑏𝑗𝑒𝑐𝑡→𝑜𝑏𝑗𝑒𝑐𝑡→𝑟𝑒𝑙𝑎𝑡𝑖𝑜𝑛(𝑠2𝑜) 和 𝑜𝑏𝑗𝑒𝑐𝑡→𝑠𝑢𝑏𝑗𝑒𝑐𝑡→𝑟𝑒𝑙𝑎𝑡𝑖𝑜𝑛(𝑜2𝑠) 两个方向提取出所有可能的 (𝑠𝑢𝑏𝑗𝑒𝑡,𝑜𝑏𝑗𝑒𝑐𝑡) 对,这样两个方向可以相互提升与互补,减少实体抽取的遗漏;然后利用一个biaffine模型为每个(𝑠𝑢𝑏𝑗𝑒𝑡,𝑜𝑏𝑗𝑒𝑐𝑡) 对预测分配可能的关系类别。
下图为BiRTE模型结构图,模型具体的细节不再赘述,可见原论文。
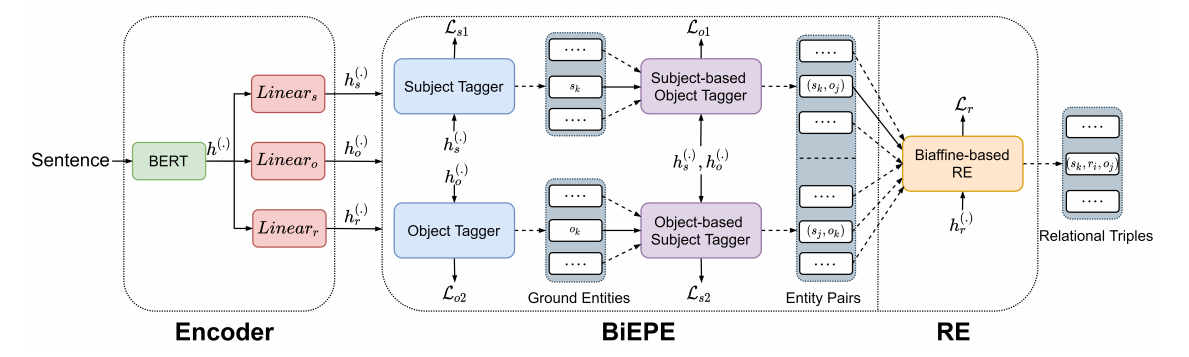
BiTE模型结构图
2. 基于片段的方法(Span based methods)
2.1 SpanRE
SpanRE中提出了标准的基于片段的抽取方法的流程,一般分为以下4个步骤:
① 文本所有可能的片段span列举,若输入文本有个 𝑇 tokens,那么存在 𝑁=𝑇(𝑇+1)2 个可能的片段, span 𝑖 由片段起始范围内的tokens组成, 即 xi=[xSTART(i),xEND(i)]
② 文本编码生成span的向量表示;如下公式,SpanRE将span范围内的token向量利用attention加权求和的 xi^ ,与span的起始token向量 、xSTART(i)、xEND(i) ,以及span的长度 𝜙(𝑖) 进行拼接作为span的表示
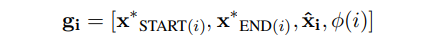
③ span实体标签分类预测:通过一个多分类模块预测每个span是否为实体以及实体类别,提取识别所有的实体
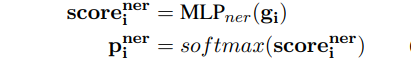
④ 实体关系提取:对提取的所有span实体两两配对,通过一个多分类模块判断实体对之间是否存在关系以及关系类别
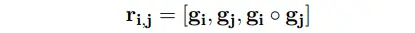
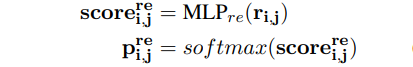
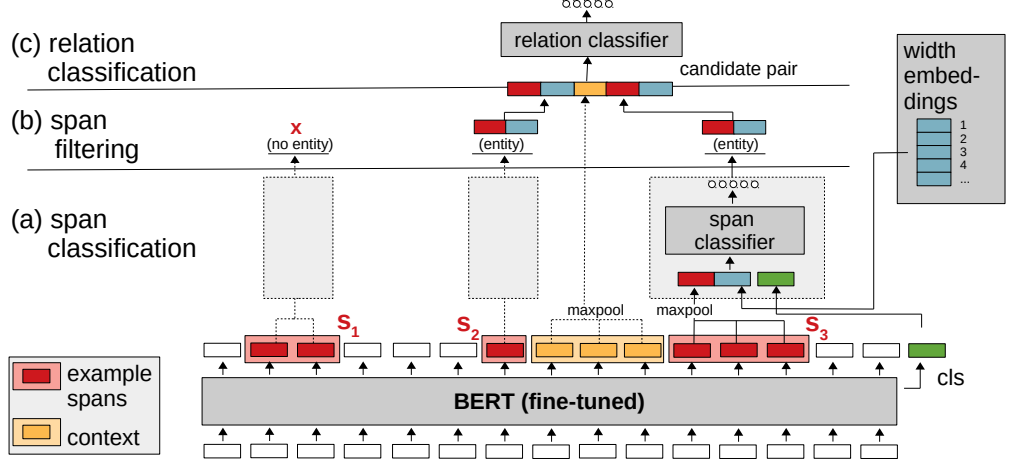
2.2 SpERT
SpERT: Span-based Joint Entity and Relation Extraction with Transformer Pre-training, ECAI 2020
SpERT模型和上述的SpanRE模型很是相似,基本流程也大致相似,不同点在于:
- SpERT使用了预训练模型BERT作为文本编码器,获得token更强大丰富的向量表征;
- SpERT获取span向量表征方式不同,SpERT学习了一个width embeddings表征span的长度,将span范围内的token进行max pooling,与BERT输出的[CLS] token向量以及长度向量进行拼接作为span的向量表示;
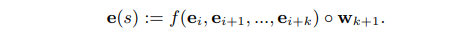
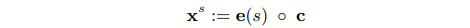
- SpERT在span实体分类阶段,过滤了被判断为none标签的span,同时过滤了多于10个tokens的span,因为实际总的片段过多会给模型带来冗余噪声并且影响计算效率,一般会限制span的长度在一个窗口范围 𝑤 内;
- 最后在对实体对进行关系分类时,SpERT将两个span之间的token向量进行max pooling获得一个上下文表示 𝑐(𝑠1,𝑠2) , 将其与两个span实体的向量表示进行拼接传入分类器进行关系类别预测
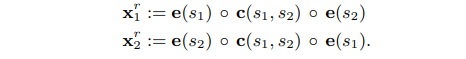
2.3 PURE
PURE: A Frustratingly Easy Approach for Entity and Relation Extraction, ACL 2021
不同于上述的两个基于span的模型,PURE是一个纯Pipeline模型,但是算法思想非常简单并且性能很好,超过了很多联合模型
[PURE提出的思路动机]:① 联合模型中实体和关系模型使用共享的编码器会影响抽取性能,因为实体和关系抽取两个任务需要关注捕捉的信息是不同的;② 关系抽取模型中在输入层(即文本编码之前)就融入实体相关信息(包括实体边界和实体类型)是非常重要的;③ 利用跨句的的上下文信息对提升实体和关系抽取两个任务的性能都非常有用
PURE模型结构流程:
针对动机①,PURE使用了Pipeline的抽取框架,分别设计训练实体抽取模型和关系抽取模型。
[Entity Model]:采用一个标准的基于span的实体抽取模型,将span起始的token向量 [XSTART(i),XEND(i)] 与span宽度特征向量 𝜙(𝑠𝑖) 拼接作为一个span的向量表示, 然后传入一个前馈神经网络预测实体类型
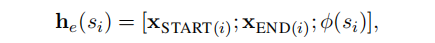
[Relation Model]:实体模型将输入文本中的所有实体全部抽取出来,对每一对实体片段 <𝑠𝑖,𝑠𝑗> 进行关系类型预测
- 关系模型用一个不同的PLM模型重新对文本进行编码,作者认为同一句子中不同的实体对的关系预测需要不同的上下文表示,因此关系模型单独处理预测每一对实体片段
- 针对动机②,模型在输入层对文本插入实体标识符(Typed markers)来突出文本中subject和object实体的位置和实体类型
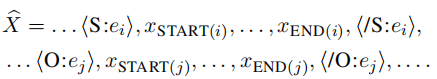
下图为在文本中插入typed markers的示例:

- 将两个实体span的起始标识符向量拼接,然后传入前馈神经网络进行关系预测

[Effificient Batch Computations]:论文还提出了一个高效的近似模型,通过较小的牺牲性能换来提高计算效率。原模型由于要插入typed makers无法实现一次文本编码抽取所有的三元组,论文的提高效率的做法是将所有实体对的typed makers拼接到文本后面,并对文本建模进行两个改变:
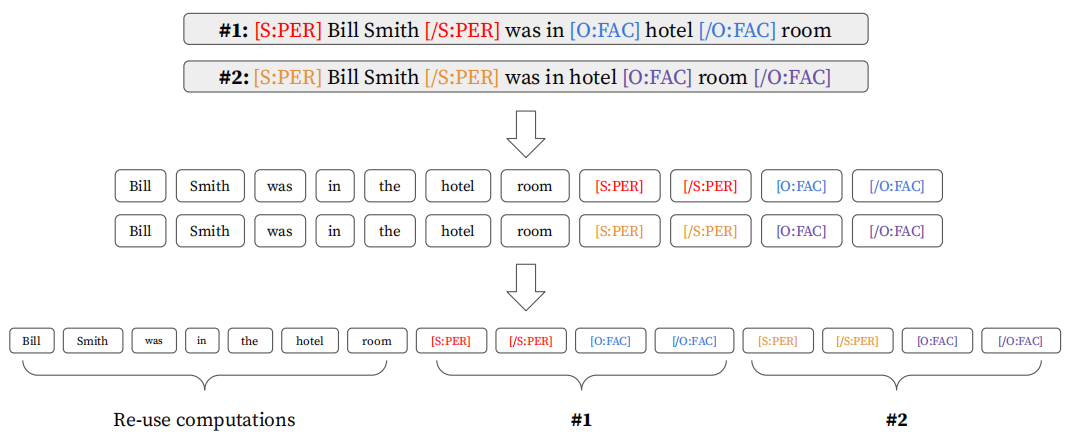
- 首先,将标识符的position id与其对应的span的起始和结束的token的poisition id对应,比如上图的第一个maker [S:PER] 与文本第一个token Bill 共享一个position id以及position embedding
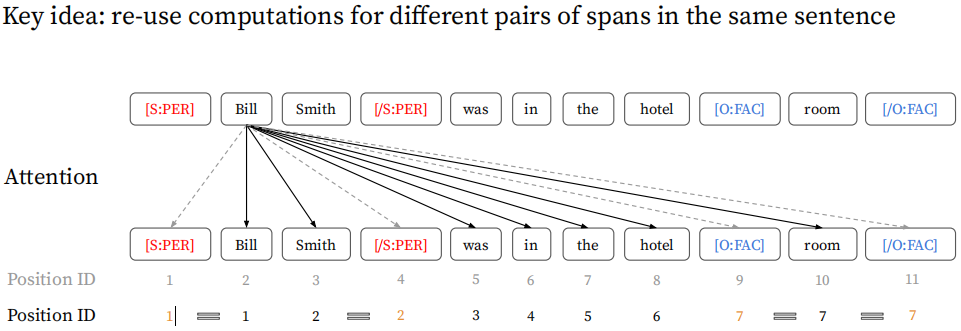
- 其次,在对拼接了makers的文本建模的attention layer做了一些限制,文本tokens只能与文本的tokens进行attention计算,不能与maker tokens进行交互,这也是近似模型的主要牺牲所在,即原文不能与makers进行交互计算;而maker tokens能够和文本tokens以及所属同一实体对的makers进行attention计算。
其他与原模型保持一致,将每个实体对对应的makers进行拼接传入前馈神经网络预测关系
PURE的优缺点:
- 优点:PURE模型是很简单,但性能很好,而且还有能够高效的计算模式,尤其是在输入层引入Typed Makers的做法很简单巧妙,整合实体位置和类型信息。其实在谷歌发表的论文Matching the Blanks: Distributional Similarity for Relation Learning, ACL 2019中也有提到使用Entity Makers的做法,但没融入实体类型。
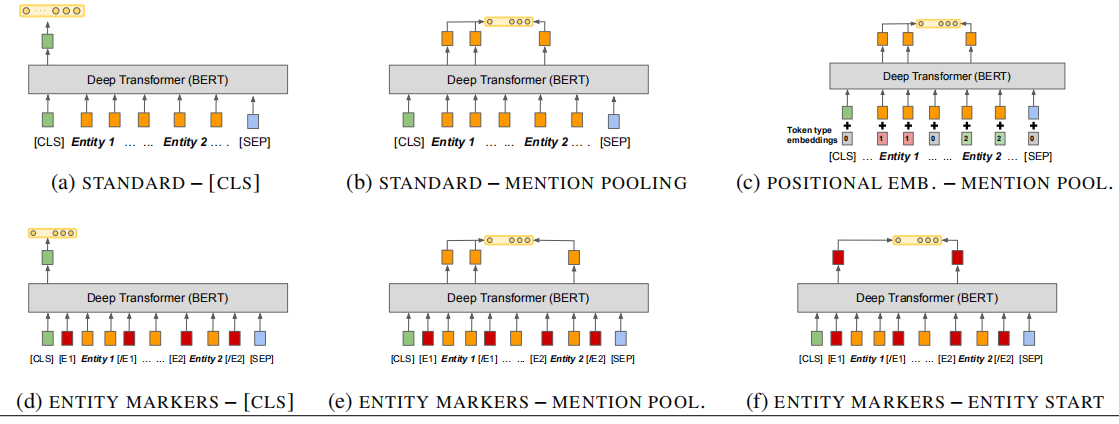
- 缺点:误差传递是Pileline模型的通病,实体识别的错误和遗漏影响后续关系分类性能。
- 还有一个是基于span方法的缺点:其实基于span的方法的流程基本是识别所有的实体,再对每个实体对进行关系预测,但是实际使用中这种方法的问题在于,若一个文本中包含多个实体,需要对每个实体对一一进行判断预测,若数据集关系复杂多样或者文本语境复杂,那么针对同一文本对很多对实体进行关系预测会很困难,因为会有很多噪声,关系分类预测模块又很简单, 而类似于CasRel这中模型首先会在诸多是中寻找subject,然后再去匹配object,会过滤许多噪声。
3. 基于填表的方法(Table filling based methods)
基于填表的方法通常为每一个关系维护一个表,这个表中的每一项都用来表示一个token pair是否具有此类关系,因此该类方法的关键是准确地填充关系表,然后可以根据填充的关系表提取三元组。
这种预测实体对在每类关系下的评分方式最早来自于multi-head selection模型,Joint entity recognition and relation extraction as a multi-head selection problem, 2018
3.1 TPLinker
TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking,ACL 2020
TPLinker主要是解决暴露偏差和误差累积问题,这是由于现有联合模型在解码时常常分为相互关联的多步,导致的训练和推理阶段不一致,同时上一步的提取误差会传递给下一步,导致最终的提取错误。
TPLinker是一个联合抽取实体和重叠关系的单步模型(one-stage),不存在任何相互依赖的步骤,因此避免了暴露偏差问题。它将联合抽取问题看做一个token对链接问题(Token Pair Linking Problem),并提出了一个握手标记方案(handshaking tagging scheme)在每中关系类别下对其实体对的tokens的边界。
① Handshaking Tagging Scheme
给定一个长度为 𝑛 的文本,将所有可能的token对列举构建一个 𝑛×𝑛 矩阵,对矩阵中每个token对进行链接标注,即填表。TPLinker定义了三种类型的token链接:
- entity head to entity tail(EH-to-ET):代表一个实体的开始和结束的token的位置,如下图紫色标签
- subjet head to object head(SH-to-OH):代表一对subject实体和object实体的开始的token的位置,如下图红色标签
- subject tail to object tail(ST-to-OT):代表一对subject实体和object实体的结束的token的位置,如下图蓝色标签
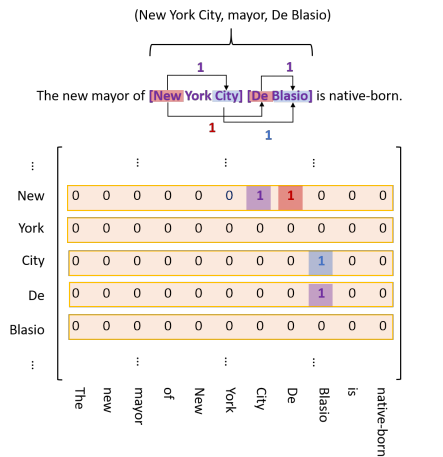
上图为某个关系的矩阵标注示例图,由于实体的tail token不可能出现在head token之前,所以对于矩阵的下三角区域均为零,导致矩阵非常稀疏,浪费了内存。但是又不能直接丢弃下三角区,因为object实体可能出现在对应的subject实体之前,因此论文将下三角区的标签1变为2,填充到上三角区,并丢弃下三角区,如下图所示。
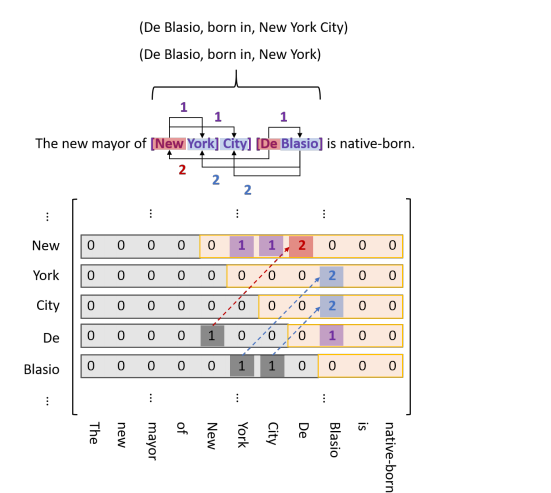
为了方便计算,将上三角区的所有项平铺成一个序列,并用一个map记录每一项在原矩阵中的位置。同时,为了解决同一对实体可能具有多种关系,即EntityPairOverlap问题,对每种关系类型都进行各自的SH-to-OH和ST-to-OT矩阵标注,EH-to-ET标注是所有关系共享的,因为它仅关注整体的实体提取与关系无关,整体结构如下图所示。
通过这种方式,给定长度为 𝑛 的文本序列,联合抽取任务就被分解成了 2𝑁+1 个序列标注子任务, 𝑁 为关系的总数目,每个标注任务需要构建长度为 𝑛2+𝑛2 的标签序列,因此整体需要预测标注的标签数为(2𝑁+1)𝑛2+𝑛2
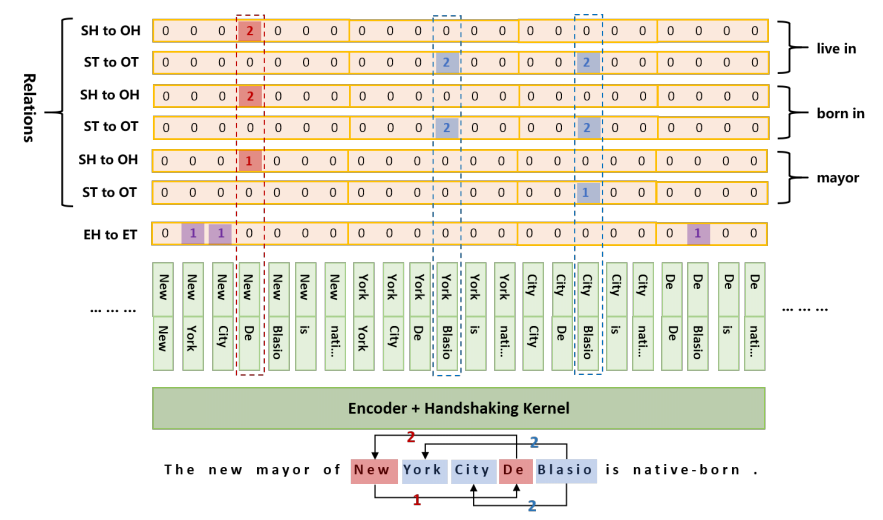
② 模型流程
TPLinker首先将输入的文本经过BERT模型进行编码获得token表示序列,然后通过以下公式获得一个token对 (𝑤𝑖,𝑤𝑗) 的关联特征表示
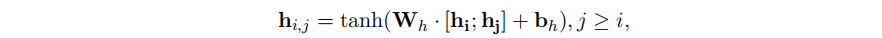
通过①中介绍的方式进行handshaking tagging得到所有的标注序列,标注序列中的每个token对的标签通过如下公式预测,最后通过标注的标签序列解码提取所有的三元组
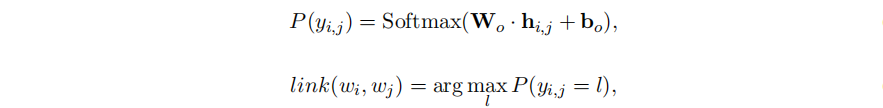
优点:
- TPLinker这种one-stage的联合抽取模型解决了暴露偏差和误差传递的问题,同时理论上能够解决SEO、EPO、SOO等关系重叠问题
缺点:
- TPLinker的标注复杂度高,存在很多冗余的操作和信息,若关系数目很大,需要标注 2𝑁+1 个标签表,就像1.2中PRGC提到的关系冗余,导致解码部分矩阵参数量很大,标签表会非常稀疏,训练收敛速度慢
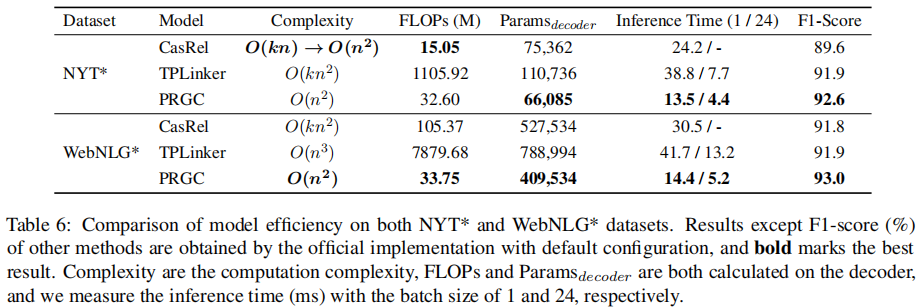
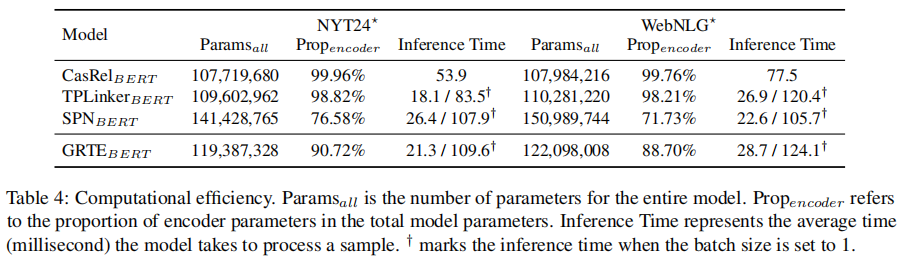
- TPLinker的解码效率并不是很高,下图为1.2中PRGC论文中的模型效率对比图,可以发现TPLinker的计算复杂度和解码效率并不是很高
- 实体和关系各自进行标注抽取,实体和关系没有进行很深的交互和关联
3.2 GRTE
A Novel Global Feature-Oriented Relational Triple Extraction Model based on Table Filling,ACL 2021
GPTE认为TPLinker这些现有方法在填充关系表时仅仅依赖于局部特征(local features),局部特征要么从单一的token pair或者从有限的token pairs的填充历史中提取得到,然而却忽略了两种有价值的全局特征(global features),即token pairs和各类关系的全局关联关系,现有的模型不能对这两类全局特征进行学习建模。
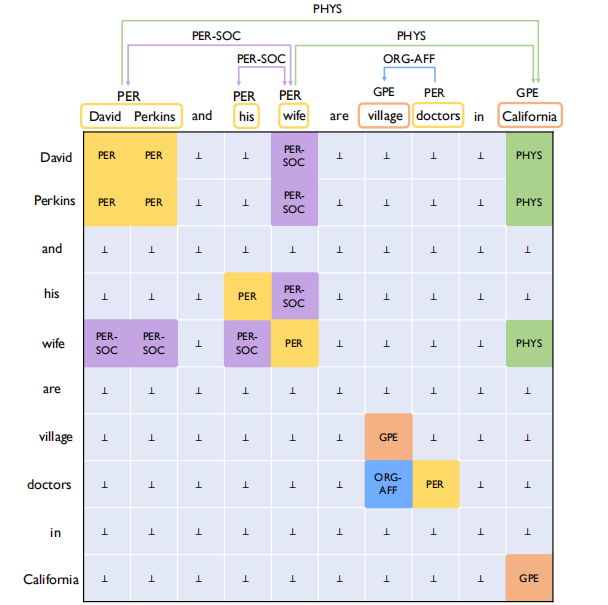
论文中所述的全局特征包括两个方面:token pairs之间的关联和关系之间的关联,以“Edward Thomas and John are from New York City, USA.”为例: ***** 同一文本中(Edward Thomas, live_in, New York) 和 (John, live_in, USA)两个三元组的提取是可以互相促进的,因为这两个三元组中的subject和object实体类型相同,高度相似的两个token pairs很可能具有相同的关系; ***** 上述live_in关系的两个元组可以帮助推断一个新的关系的三元组(New York, located_in, USA),因为located_in和live_in关系是语义相关的, located_in要求subject和object都为location实体,live_in要求object为location实体,因此两个live_in关系的三元组到一个新的located_in关系三元组之间能够形成很明显的推断路径
① GRTE的填表策略(Table Filling Strategy)
给定一个长度为 𝑛 的的文本序列,为每一个关系 𝑟∈𝑅 维持一个 𝑛×𝑛 大小的表 𝑡𝑎𝑏𝑙𝑒𝑟 ,模型的关键是为表中每个位置也就是token pair填充正确的标签。表第 𝑖 行和第 𝑗 列表示为 (𝑤𝑖,𝑤𝑗) , 这一个token pair的标签为 𝑙 ,GRTE的填表规则策略如下:
- 填充表的标签集合为:
𝐿={′N/A′,′MMH′,′MMT′,′MSH′,′MST′,′SMH′,′SMT′,′SS′}
- ′N/A′ 表示两个tokens没有任何关联关系,其他标签表示(𝑤𝑖,𝑤𝑗)和同一个 (𝑠𝑢𝑏𝑗𝑒𝑐𝑡,𝑜𝑏𝑗𝑒𝑐𝑡) 实体对相关联
- 标签第一个字符表示 𝑠𝑢𝑏𝑗𝑒𝑐𝑡 是一个多tokens实体( ′M′ )还是一个单token实体( ′S′ )
- 标签第二个字符表示 𝑜𝑏𝑗𝑒𝑐𝑡 是一个多tokens实体( ′M′ )还是一个单token实体( ′S′ )
- 标签第三个字符表示 𝑤𝑖 和 𝑤𝑗 均为 𝑠𝑢𝑏𝑗𝑒𝑐𝑡 和 𝑜𝑏𝑗𝑒𝑐𝑡 实体的head token( ′H′ )或者都是 𝑠𝑢𝑏𝑗𝑒𝑐𝑡 和 𝑜𝑏𝑗𝑒𝑐𝑡 的tail token( ′T′ )
- ′SS′ 表示(𝑤𝑖,𝑤𝑗)本身就是一个 (𝑠𝑢𝑏𝑗𝑒𝑐𝑡,𝑜𝑏𝑗𝑒𝑐𝑡) 实体对
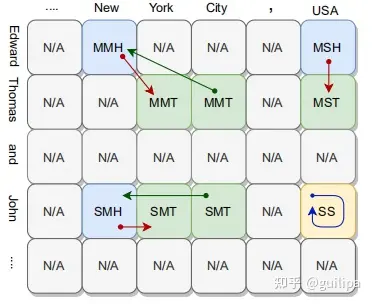
GRTE的填表策略需要填充的数目为: 𝑛2|𝑅| , 低于TPLinker需要填充的数目 (2𝑅+1)𝑛2+𝑛2 。
② 模型细节(Model Details)
模型结构图如下,主要包括四个部分:编码模块(Encoder)、表特征生成模块(Table Feature Generation,TFG)、全局特征挖掘模块(Global Feature Mining,GFM)和三元组生成模块(Triple Generation,TG)。其中,文本经过编码层一次编码,然后,经过TFG和GFM以迭代的方式进行多次的计算来一步步的更新并获得最终的表特征,最后利用TG模块提取三元组。
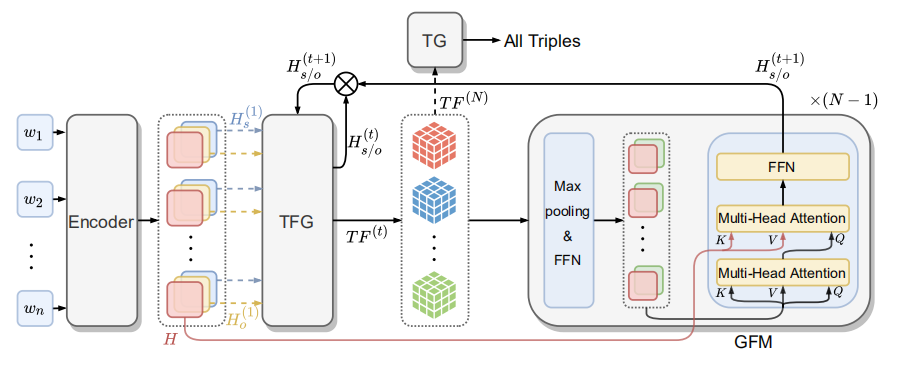
- Encoder Module
编码模块利用BERT对文本token序列进行编码获得token表示序列 𝐻∈𝑅𝑛×𝑑ℎ ,并利用两个独立的全连接模块FNN获得初始化的subjects特征 𝐻𝑠(1) 和objects特征𝐻𝑜(1)
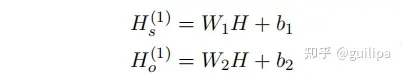
- TFG Module
由于TFG和GFM两个模块是需要进行多轮的迭代计算,令在第 𝑡 轮中,subjects和objects特征为 𝐻𝑠(𝑡) 和 𝐻𝑜(𝑡) ,关系 𝑟 的表特征为 𝑇𝐹𝑟(𝑡) ,其中的每一项特征𝑇𝐹𝑟(𝑡)(𝑖,𝑗)为(𝑤𝑖,𝑤𝑗)对应的特征值
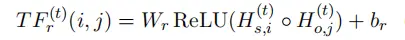
- GFM Module
TFG模块学习了token pairs之间的局部关联特征并生成每个关系的表特征,而GFM模块在此基础上挖掘建模两类全局特征,并产生新的subjects和objects特征,传入TFG模块进行下一轮的计算
Step 1:将所有关系的表特征进行拼接得到一个统一的表特征 𝑇𝐹(𝑡) ,然后用max pooling操作和FNN模块获得一个subjects相关的表特征𝑇𝐹𝑠(𝑡) 和一个objects相关的表特征𝑇𝐹𝑜(𝑡)
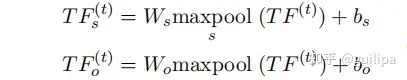
Step 2: 利用基于Transformer的模型来挖掘关系之间以及token pairs之间的全局关联。1)对于关系之间的全局关联,作者在𝑇𝐹𝑠/𝑜(𝑡)上进行多头自注意力计算;2)对于token pairs之间的全局关联,在token序列 𝐻 和𝑇𝐹𝑠/𝑜(𝑡)^上进行多头自注意力计算; 3) 然后利用FFN模块产生新的subjects特征和objects特征

Step 3:为了缓解梯度消失问题,使用残差连接生成最终的subjects和objects特征表示
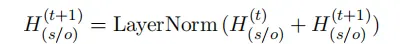
- TG Module
TG模块对经过 𝑁 轮计算得到的填充表 𝑇𝐹(𝑁)进行解码并推断出所有的三元组,即针对每一个关系 𝑟 ,预测其关系表中每一项的标签,最后基于标签表进行三元组推断。
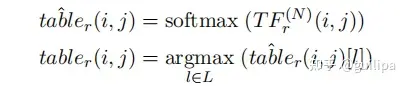
在解码中为每个关系提取实体对时,作者设计了三个并行的搜索路径:一是前向搜索(forward search),即按顺序从head tokens到tail tokens生成实体对;二是逆向搜索(reverse search),即按从tail tokens到head tokens的顺序生成实体对,这一搜索方式是为了解决实体重叠的问题;三是由single token组成的实体对生成
优点:
- GRTE能够解决暴漏偏差和误差传递的问题,能够解决SEO、EPO、SOO关系重叠问题
- 相比TPLinker能够挖掘全局特征,对关系间和不同token pairs之间进行关联建模
- 相比TPLinker,GRTE的填表策略减少了填表数目,减少了冗余的信息,论文指出了相比其他模型训练epoches少、收敛速度快些
缺点:
- GRTE基于Transformer迭代的挖掘全局特征的GFM模块使得模型复杂度提升并且计算效率降低,并且值得注意的是GRTE去除GFM模块并不比TPLinker性能好
- 模型解码部分参数量变大,解码推断效率变低,下图为论文中的计算效率对比图,可以看出整体的参数量和推断时间要比TPLinker大
3.3 Others
基于填表的抽取方法的不同点多在于填表的方案策略以及基于填充表的解码算法,下面也是基于填表的方法,由于篇幅长度的问题,模型详细的细节可以见原论文。
1) UNIRE
UNIRE: A Unifified Label Space for Entity Relation Extraction,ACL 2021
UNIRE认为现有模型将实体检测和关系分类两个子任务设置在两个独立分开的标签空间,损害了实体和关系之间的信息交互。
- UNIRE将实体和关系两个任务标签整合,统一联合标签空间,将实体关系联合抽取看成一个填表问题,利用统一的分类器预测表中每个单元的标签
- 如下图,在填充的表中实体是正方形并且在对角线上,关系是长方形在对角线两侧
- 模型通过在损失函数结构正则化对表格施加两个结构约束
- Symmetry,即对称性,表格中实体对应的正方形是关于对角线对称的,而对称等价的两个关系三元组对应的长方形也是关于对角线对称的
- Implication,即蕴含性,如果一个关系存在,那么对应的两个实体也应该存在,也就是表中一个关系的概率应该小于其关联的每个实体的概率
- 模型设计了简单快速的解码方法,同时还增强了实体和关系的交互。解码分为三步:span解码、实体类型解码和关系类型解码
该论文在实验对比部分并没有和CasRel、PRGC和TPLinker等模型进行对比,主要是和PURE模型对比,性能和效率很难说明。
2)OneRel
OneRel: Joint Entity and Relation Extraction with One Module in One Step, AAAI 2022
这篇论文的方法和TPLinker非常相似,TPLinker需要标注 2𝑁+1 个标签矩阵,而OneRel减少了矩阵为 𝑁 个,即每个关系一个矩阵,因此减少了冗余的信息,提升了模型效率,也增加了实体和关系的交互,具体可见论文。
4. 基于阅读理解的方法(MRC based methods)
4.1 Multi-turn QA
Entity-Relation Extraction as Multi-turn Question Answering, ACL 2019
在论文中提出了一种新的关系抽取模式,将实体关系抽取看作多轮问答(Multi-turn Question Answering, QA)问题,进而将实体和关系的抽取转化成从文本中识别答案片段的任务。在该模式中,每个实体类别和关系类别都由一个查询模板(Query Template)来表征,同时实体和关系通过回答问题来提取,答案片段利用标准的机器阅读理解(Machine Reading Comprehension ,MRC)框架模型来提取。
模型整体包括两个阶段:
1)头实体抽取阶段(Head-entity Extraction)
利用实体查询模板 𝐸𝑛𝑡𝑖𝑡𝑦𝑄𝑢𝑒𝑠𝑇𝑒𝑚𝑝𝑙𝑎𝑡𝑒𝑠 将每个实体类型转化成一个问题,将问题与文本拼接来提取头实体 𝑒ℎ𝑒𝑎𝑑 。在这一阶段,输入和文本会和每个实体类型问题进行拼接并计算判断文本中是否有该类型的实体,有则提取实体,没有则输出 𝑁𝑂𝑁𝐸 token。
论文中利用模板生成实体问题的方式有两个,分别是自然语言问题(natural language question)和伪问题(pseudo question),实验证明自然语言问题性能效果会更好。以下图中的人名类型实体为例,可以构造以下两类问题查询语句: ①“句子中提到的人是谁?” ---> 自然语言问题 ②“人名” ---> 伪问题
2) 关系和尾实体抽取阶段(Relation and Tail-entity Extraction)
关系类型𝑟𝑒𝑙也定义了问题模板 𝐶ℎ𝑎𝑖𝑛𝑂𝑓𝑅𝑒𝑙𝑇𝑒𝑚𝑝𝑙𝑎𝑡𝑒𝑠 ,每个关系型𝑟𝑒𝑙对应的问题模板中都包含了一些槽位slots,需要利用将第一阶段提取的头实体𝑒ℎ𝑒𝑎𝑑进行填充,构建出关系问题。将关系问题与文本拼接,提取出头实体和关系对应的尾实体𝑒𝑡𝑎𝑖𝑙,进而获得提取的实体关系三元组 ()(𝑒ℎ𝑒𝑎𝑑,𝑟𝑒𝑙,𝑒𝑡𝑎𝑖𝑙) 。
以下图为例,第一阶段提取出了"人名"类型的实体"普京",预先定义好的"毕业"关系的问题模板为"___毕业于哪所学校?" , 将第一阶段提取的"普京"填入模板构造"毕业"关系的问题。
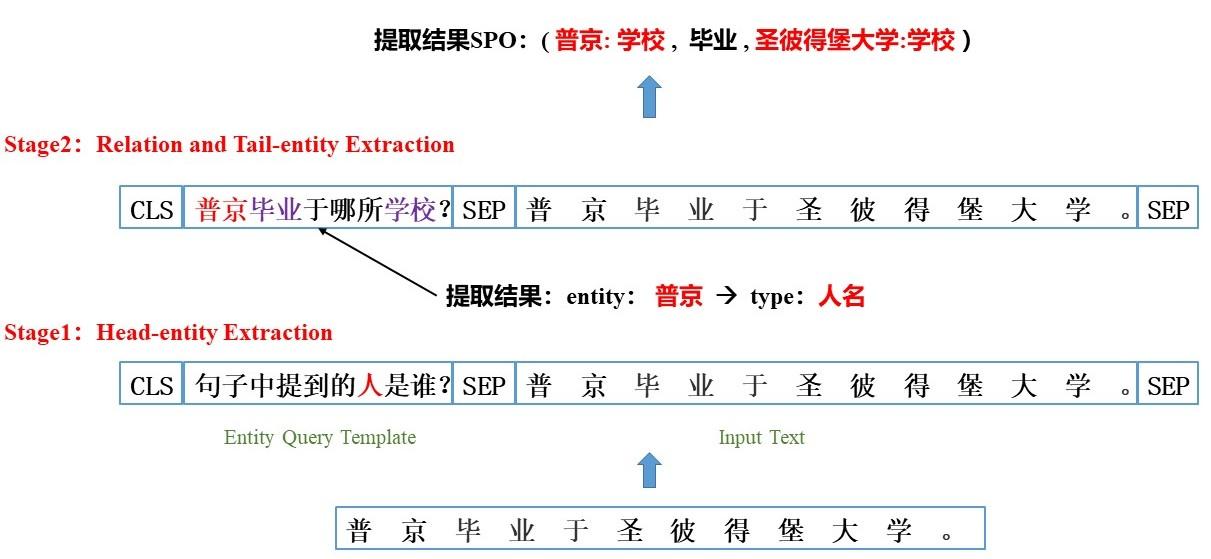
Two-Stage MRC实体关系抽取示意图
6. 基于生成的方法 (Generation based methods)
不同于上述的各类抽取方法,这部分是完全不同的抽取模式,文章[4]中将上述的各类方法归纳为“抽取范式”,而本章节的方法称为“生成范式”。其实,从2018年左右生成范式的抽取模型就有被陆续提出,这部分模型以RNN为基本的模型,采用传统Seq2Seq深度生成框架,但这些生成式的模型和抽取式模型相比并未有明显的优势。直到近年来UniLM、BART、T5和GPT等生成式预训练模型的广泛使用,使得构建有效的生成式信息抽取模型成为了可能。2022年各个平台上最火的信息抽取模型应该百度和中科院联合发表的UIE模型,它就是一个生成式的通用信息抽取模型,直接将生成式的信息抽取推向了最前沿的研究方向。
基于预训练模型的生成式抽取模型的优势在于:首先,生成式模型相比抽取式模型迁移性、扩展性更强,抽取式更容易受到schema的限制;其次,生成式模型使得统一不同场景、不同任务、不同schema的信息抽取成为可能,比如UIE,同时能够达到即插即用、使用方便的优点;最后,生成式抽取模型对zero-shot和few-shot这类低资源场景下的抽取任务更加有效。
6.1 Copy Model
(1) CopyRE
CopyRE: Extracting Relational Facts by an End-to-End Neural Model with Copy Mechanism, ACL 2018
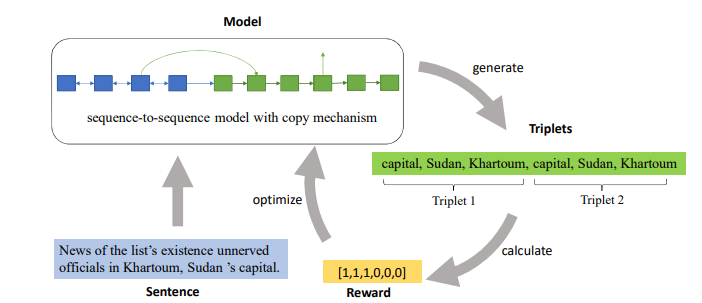
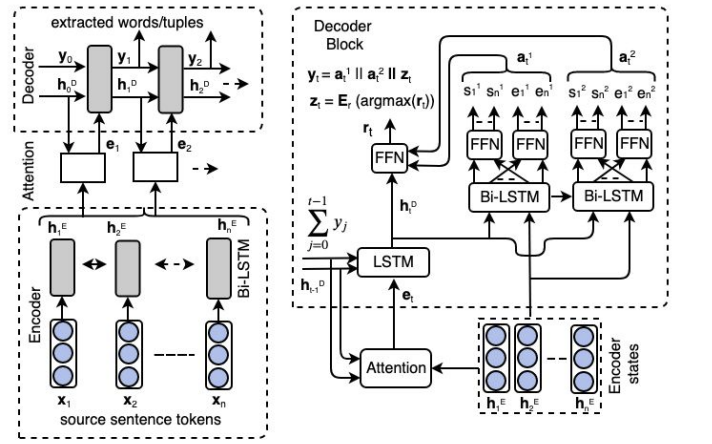
CopyRE是一个基于复制机制(Copy Mechanism)的序列到序列(Sequence-to-Sequence,Seq2Seq)学习的端到端联合抽取模型,能够解决SEO和EPO关系重叠问题。模型包括一个Encoder和一个Decoder, Encoder将文本序列编码,Decoder对文本进行一步步解码生成所有的三元组。
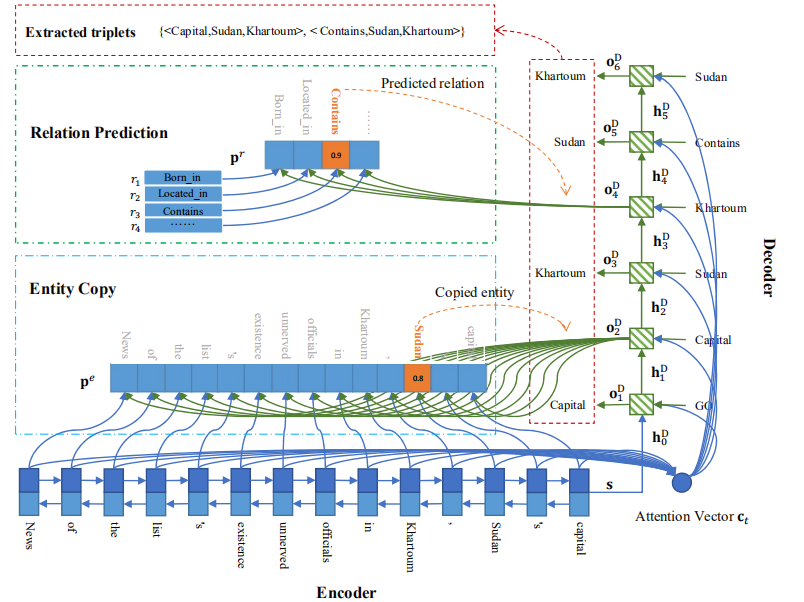
CopyRE模型结构图
① Encoder
模型利用双向RNN对输入文本进行编码,编码函数为: 𝑜𝑡𝐸,ℎ𝑡𝐸=𝐵𝑖𝑅𝑁𝑁𝐸(𝑥𝑡,ℎ𝑡−1𝐸)。编码后获得token序列表示 𝑂𝐸={𝑜1𝐸,...,𝑜𝑛𝐸} ,将前后的RNN隐层向量拼接作为文本表示 𝑠=[ℎ𝑛𝐸→;ℎ𝑛𝐸←] 编码函数为: 𝑜𝑡𝐸,ℎ𝑡𝐸=𝐵𝑖𝑅𝑁𝑁𝐸(𝑥𝑡,ℎ𝑡−1𝐸)
② Decoder
模型使用单向的RNN对文本序列从左向右进行一步步解码生成所有的三元组,解码函数为:𝑜𝑡𝐷,ℎ𝑡𝐷=𝑅𝑁𝑁𝐷(𝑢𝑡,ℎ𝑡−1𝐷)。 ℎ𝑡−1𝐷 为上一步 𝑡−1 的隐层状态,编码器的最后一个隐向量作为解码器的初始隐向量ℎ0𝐷; 𝑢𝑡 为编码器 𝑡 时刻的输入,计算公式为: 𝑢𝑡=[𝑣𝑡;𝑐𝑡]𝑊𝑢˙ 。 𝑣𝑡 表示 𝑡−1 时刻解码输出的实体或关系的嵌入向量; 𝑐𝑡 为解码器上一时刻隐层向量 ℎ𝑡−1𝐷 对经过编码的文本序列 𝑂𝐸 进行注意力求和得到的向量
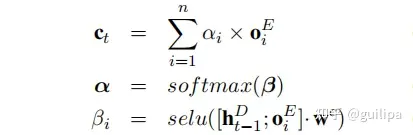
解码时,每三个时间步为一个循环提取一个三元组,依次生成三元组的关系relation、从原来的文本中复制三元组的第一个实体、从原来的文本中复制三元组的第二个实体,构成完整的三元组。解码器不断重复上面三步生成多个三元组。
- Relation Prediction
在 𝑡%3=1 时,模型使用 𝑡 时刻的输出来预测一个关系,及进行多分类模块。其中 𝑞𝑟 为各个关系类别的置信分数,𝑞𝑁𝐴为NA关系的置信分数。选择概率最高的位置对应的关系,并将该关系的嵌入向量作为下一时刻的输入𝑣𝑡+1
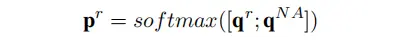
- Copy the First Entity
在𝑡%3=2时,模型使用 𝑡 时刻的输出与原文本序列进行关联计算,获得一个概率分布。选择概率最高的位置对应的token,并将该token的嵌入向量作为下一时刻的输入𝑣𝑡+1
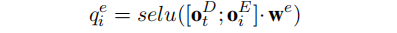
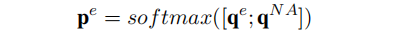
- Copy the Second Entity.
在t%3=0时,模型使用 t 时刻的输出与原文本序列进行关联计算,与上一步类似获得一个实体token,不同的是此时复制的实体与上一步的实体应该不相同,因此计算概率分布时使用了一个mask矩阵 M,其中上一步提取的token位置值为0,其余为1

同样,将概率最高的word作为预测的实体token,并将token的向量作为下一时刻的输入v_{t+1}
③ MultiDecoder Model
上述的是一个OneDecoder模型,一个解码器解码生成所有的三元组,论文还设计了MultiDecoder Model ,利用多个分开的解码器级联来解码生成多个三元组,论文实验也证明了MultiDecoder性能要好于OneDecoder
CopyRE应该是最早提出的Seq2Seq这一新范式的联合抽取模型,但它存在以下缺点使得它的性能还有很大的提升空间:
- 在copy两个实体时,模型只能copy实体的最后一个token,对于由多个token组成的实体是不能完整提取的
- 模型无法区分head实体和tail实体,容易将两个实体的位置顺序弄混
- MultiDecoder在训练时训练固定数目的Decoder,推断时三元组的数目超过Decoder数目时就无法完全提取
CopyRE提出之后,带来了Seq2Seq新的抽取模式,但它本身存在一些问题,后续有一些列工作提出了改进
(2) CopyRE + RL
这篇文章认为文本句子中多个三元组间的抽取顺序是很重要的,为了自动学习句子中多个三元组的抽取顺序,论文将强化学习(Reinforcement Learning,RL)应用在CopyRE模型上,将三元组的生成过程看做RL过程,并用REINFORCE算法优化模型
(3) CopyMTL
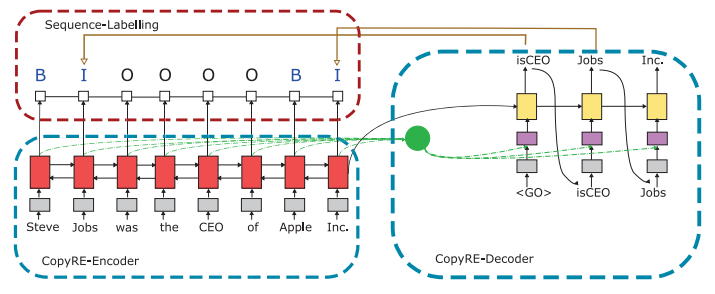
论文中作者经过试验分析发现CopyRE存在两个关键的问题:一方面,模型实体预测部分不稳定,常将head和tail实体顺序混淆;另一方面,模型无法提取多tokens组成的实体。未解决上述问题,提出CopyMTL模型,它是一个基于多任务学习的模型,同时改进了CopyRE的实体复制的结构能够预测多token实体
针对实体预测不稳定问题,在CopyRE复制实体部分增加非线性的全连接层,单独预测head和tail实体的概率分布,tail实体预测也能接收head实体预测的信息
针对无法copy多token实体,模型使用CRF对句子进行BIO序列标注完整的识别所有的实体,实体识别的结果用于后续的解码部分的实体预测,并将CRF实体识别损失函数与CopyRE解码损失函数联合,进行多任务学习
(4) WDec & PNDec
论文仍然是基于复制机制的Seq2Seq结构的取实体关系联合抽取模型,解码器生成提取的三元组,作者提出了一种新的三元组表示schema,如下图所示,'|'用于分割三元组,';'三元组内实体和关系,这使得解码器可以提取具有重叠实体的多个三元组,以及多token组成的实体关联的三元组。

作者提出了两种解码方法:WordDecoding (WDec) 和 PtrNetDecoding (PNDec)
- WDec:类似CopyRE利用LSTM对文本进行解码,按上图中的schema一步步生成三元组,同时利用mask机制控制生成的内容仅包括当前句子中的tokens、关系tokens、特殊分隔符tokens
- PNDec:作者提出了基于指针网络(Pointer Network)的解码方法,不同于WDec每一步生成一个token或word,PNDec每一不生成一个三元组。PNDec获得当前解码的隐层表示后,传入两个全连接层分别识别出两个实体的开始和结束位置,然后再利用两个实体表示判断关系。
6.2 SNP
SPN: Joint Entity and Relation Extraction with Set Prediction Networks, 2020
[动机]:上述的基于copy机制的Seq2Seq抽取模型均使用自回归的解码器(autoregressive),需要将预测的三元组集合转化成三元组序列,并用解码器一步一步的生成三元组。但是这些基于自回归解码的模型存在两个问题:首先,需要考虑多个三元组之间的抽取顺序,但是文本中包含的三元组本质上没有内在顺序,为了适应输出为序列的自回归解码器,无序的三元组在训练时必须按一定的顺序排序;其次,交叉熵是一个对序列排列敏感的损失函数,对每个位置预测错误的三元组都会产生惩罚。
论文将实体关系联合抽取看做一个集合预测问题,不用考虑多个三元组之间的顺序。SPN采用非自回归的并行解码方式,能够直接一次性输出最终预测的三元组集合。同时,提出了二分匹配损失bipartite matching loss,它通过忽略三元组顺序并专注于关系类型和实体,为模型提供更准确的训练信号。
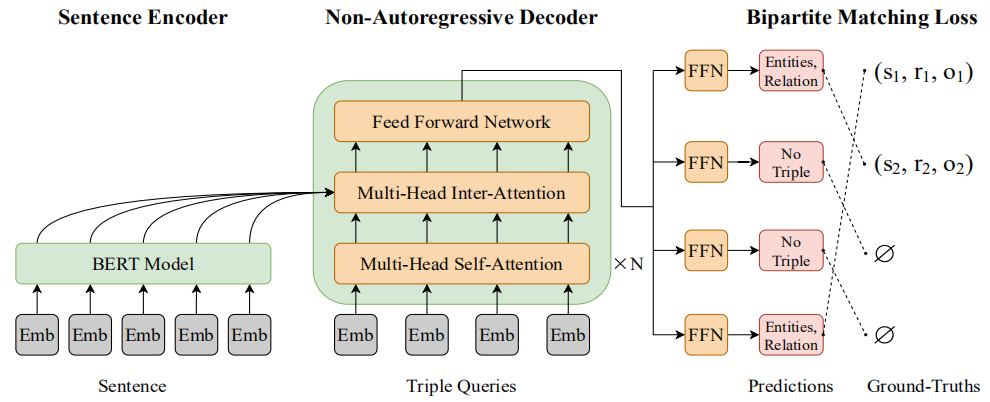
- 模型细节
[Sentence Encoder]: 利用BERT对输入的文本句子 𝑋 进行编码,获得token序列的隐层表示 𝐻𝑒
[Non-Autoregressive Decoder]: 下式为给定输入文本 𝑋 ,目标三元组集合 𝑌 的概率密度函数, 𝑝𝐿(𝑛|𝑋) 为目标三元组集合的大小。在解码之前,解码器需要知道生成目标集合的大小,论文将𝑝𝐿(𝑛|𝑋)设置为固定大小 𝑚 ,其中 𝑚 大于一个句子中常规的三元组数目。解码器的输入被初始化为 𝑚 个可学习的embeddings,且所有句子共享。
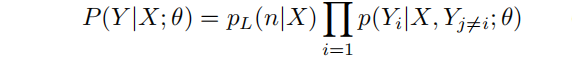
将 𝑚 个三元组queries的embeddings传入decoder,经过一个由 𝑁 个transformer层的模块对三元组之间的关系进行建模,并获得 𝑚 个输出embeddings,表示为 𝐻𝑑 。𝐻𝑑最后经过前馈神经网络FFN解码为关系类型和实体,最终组成 𝑚 个预测的三元组。
给定解码器输出的embedding向量 ℎ𝑑∈𝐻𝑑 ,通过下式获得预测的关系类型:
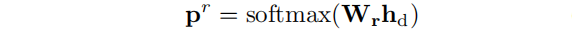
预测的实体通过分类器预测的实体开始和结束的索引解码得到:
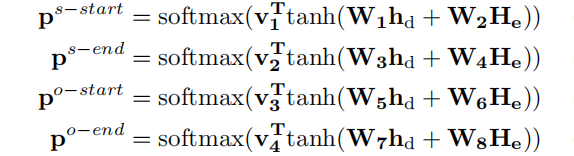
[Bipartite Matching Loss]: SPN预测的三元组并没有考虑顺序,而交叉熵对预测的三元组之间位置的置换非常敏感,因此提出了一个set prediction loss,它可以在预测的三元组和真实三元组之间进行最佳的二分匹配。
𝑌 表示真实的三元组集合,其中每个三元组表示为 𝑌𝑖=(𝑟𝑖,𝑠𝑖𝑠𝑡𝑎𝑟𝑡,𝑠𝑖𝑒𝑛𝑑,𝑜𝑖𝑠𝑡𝑎𝑟𝑡,𝑜𝑖𝑒𝑛𝑑) ;𝑌表示预测的三元组集合,其中每个预测的三元组表示为𝑌𝑖=(𝑝𝑖𝑟,𝑝𝑖𝑠−𝑠𝑡𝑎𝑟𝑡,𝑝𝑖𝑠−𝑒𝑛𝑑,𝑝𝑖𝑜−𝑠𝑡𝑎𝑟𝑡,𝑝𝑖𝑜−𝑒𝑛𝑑)。通过最小化如下的损失函数优化模型:
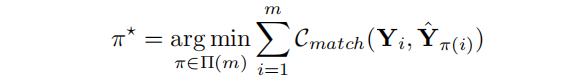
𝐶𝑚𝑎𝑡𝑐ℎ(.) 是一个pair-wise的匹配代价函数,通过考虑真实三元组和预测三元组的关系类别和实体的起始位置来计算得到:
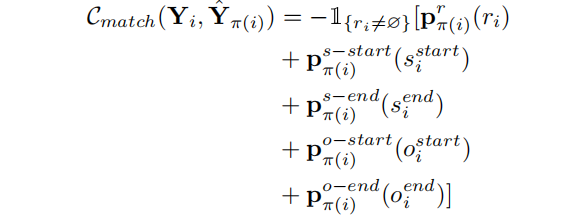
6.3 CGT
Contrastive Triple Extraction with Generative Transformer, AAAI 2021
[动机]:论文关注的是生成式三元组抽取,但是已有的CopyRE这一系列基于复制机制并以RNN作为编解码器的模型存在两个关键的问题:一是无法捕捉文本的长距离依赖关系,很难应用于长文本;二是很少关注生成可信的三元组,比如文本“ Obama was born in Honolulu”中正确的三元组是“(Obama, was born, Honolulu)”,而模型生成“(Obama, live in, Honolulu)” ,虽然逻辑上可能是对的,但是文本中却没有直接的证据来推断。
为解决以上的问题,将三元组抽取看做一个序列生成问题,并受到当前基于Transformer的自然语言生成研究的启发,提出一个基于生成式Transformer的对比三元组抽取模型(Contrastive triple extraction with Generative Transformer,CGT)。
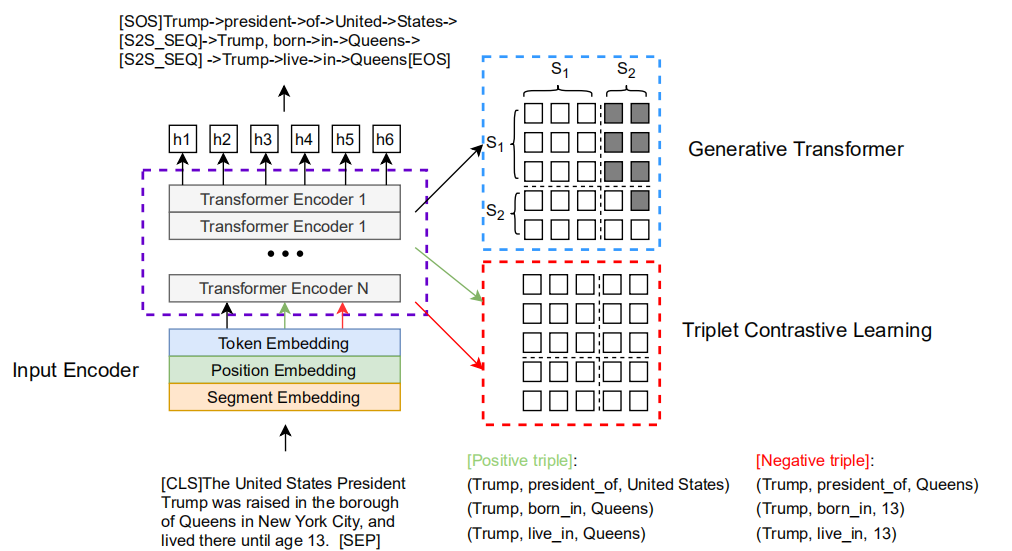
CGT模型结构图
- Input Encoder
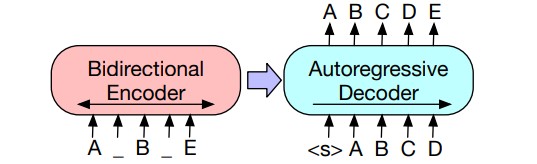
CGT的基本模型架构是参考微软提出的预训练模型UniLM中的Sequence-to-Sequence LM任务部分。输入句子的tokens组成source sequence,所有三元组的通过特殊标志[S2S_SEQ]拼接组成target source,如下所示:
Source Sequence: [CLS]The United States President Trump was raised in the borough of Queens in New York City, and lived there until age 13. [SEP] Target Sequence: [SOS]Trump->president->of->United->States->[S2S_SEQ]->Trump, born->in->Queens->[S2S_SEQ] ->Trump->live->in->Queens[EOS]
在训练时,encoder的输入由source sequence和target sequence,即 𝑥0,𝑥1,...,𝑥𝑚,[𝑆𝐸𝑃],𝑦0,𝑦1,𝑦𝑛 ,用生成式transformer对输入进行编码并生成输出,利用交叉熵损失函数优化生成过程:
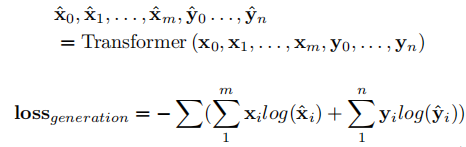
在测试推断时,encoder输入的是source sequence,模型生成target sequence。
生成式transformer在每一层的自注意力计算时使用了partial causal mask,source sequence中的tokens间可以自由交互,target sequence只能与左侧的tokens以及source sequence中的tokens进行交互
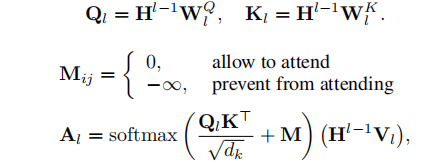
- Triplet Contrastive Learning
为了增强生成三元组的可信度并与原句语境保持一致,在上述模型基础上引出三元组对比学习。将正确的三元组作为正样例,将三元组中的一个实体随机替换为文本中tokens作为负样例。编码器输入时仅将文本与一个三元组拼接,编码后将[CLS]的隐层表示传入MLP进行二分类,并用交叉熵损失函数优化三元组对比过程:
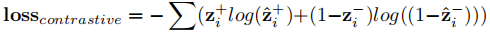
在三元组对比学习时,编码器Transformer的自注意力计算使用的是全0 mask,与三元组生成的partial causal mask不同
- Training and Inference Details
在训练优化时,针对三元组生成和三元组对比学习两个不同的任务的共同优化提出了批量动态注意力掩码(batch-wise dynamic attention masking)。作者利用Bernoulli分布抽取一部分样例用于三元组生成,剩余的用于三元组对比学习,用不同的样本训练两个任务,并进行联合优化。
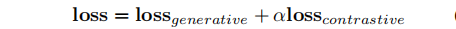
在推断时,模型先利用beam search生成所有的三元组序列,然后利用三元组校准算法过滤不可信的三元组。利用三元组对比分类模块计算文本三元组匹配分值,过滤小于一定阈值 𝜃 的三元组;同时还利用一些启发性规则生成三元组,比如头实体生成之后要生成关系等。
- 模型分析
实验结果表明CGT较CopyRE这类已有的生成式模型性能提升较大,和CasRel这类抽取式的模型相比获得了可比较的性能结果,这是由于生成式模型的搜索空间远大于抽取式模型。
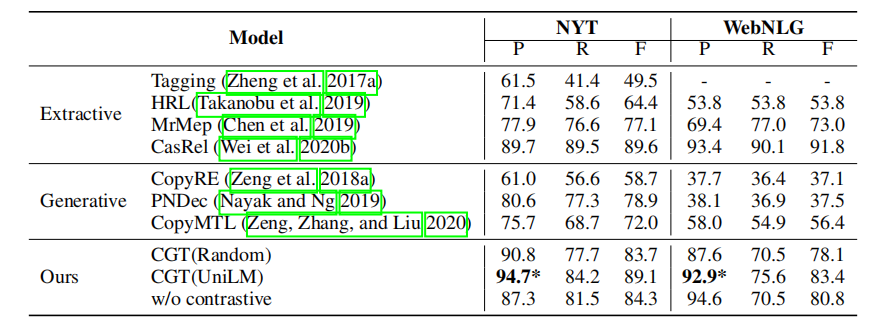
同时还进行了错误分析,展示了模型的生成三元组时的三个缺点:一是模糊的上下文难以处理,一些上下文相似的文本模型更倾向于预测高频的关系;二是边界错误,三元组生成时很难捕捉判断实体的边界;三是错误的三元组,这个是在说WeNLG数据集存在错误样例,属于无效分析......
6.4 REBEL
REBEL: Relation Extraction By End-to-end Language generation, EMNLP 2021
[动机]:现有模型往往涉及多步的层级模块且计算复杂度高,各个以任务为中心的模块(e.g., 实体识别和关系分类)需要训练适配不同的实体和关系数目,无法灵活的处理不同类型或不同领域的抽取任务,并且对于新的数据常常需要长时间的训练优化。
针对上述问题,论文将关系抽取看做Seq2Seq任务,基于 BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension 提出端到端语言生成的关系抽模型REBEL,并构建了一个大规模的远程监督数据集。利用构建的REBEL数据集对BART进行预训练,然后在下游的抽取任务上微调很少的epochs就能达到SOTA性能。REBEL模型能够灵活的适应新的领域和更长的文档数据,同时不需要从头训练特定的模块,使得训练更高效。
- Model Details
REBEL利用BART-large作为基础模型,采用如下图所示的encoder-decoder结构,将原始的文本句子作为输入,将生成的三元组集合作为输出,并利用交叉熵损失函数优化模型。
- Triplets linearization
作者设计了三元组线性化规则将解码器生成的三元组用token序列表示,如下图所示。三元组输出线性化表示一方面使得模型在解码过程中可以同时利用编码器的输入和解码器已经输出的信息,捕捉更长距离的依赖;另一方面能够最小化生成tokens的数目,使得解码和优化更高效。

解码生成的三元组按照头实体在文本中出现的顺序进行排序,头实体重叠的多个三元组不需要每次都将头实体列出以减少生成序列的长度。最后,利用解码器生成的token序列转化成三元组。
- REBEL dataset
BART模型需要大量的数据来训练,但是现有的关系抽取数据集很少并且通常很小,因此作者利用Wikipedia构建了一个大规模的实体关系数据集用于BART预训练。
作者使用 wikimapper 将文本中超链接对应的词作为实体链接到 Wikidata 的实体,提取了Wikidata 中这些实体之间存在的所有关系。为了滤除噪声,使用预训练的RoBERTa模型进行蕴含预测判断文本是否包含某个关系组,将文本与三元组拼接(i.e., text [sep] subject relation object)输入RoBERTa预测分数,高于一定阈值才保留,否则丢弃。
论文选取句子级的样例,并保留最多的220种关系构成句子级数据集,预训练BART-large作为 REBELpre−training
- 实验结果分析
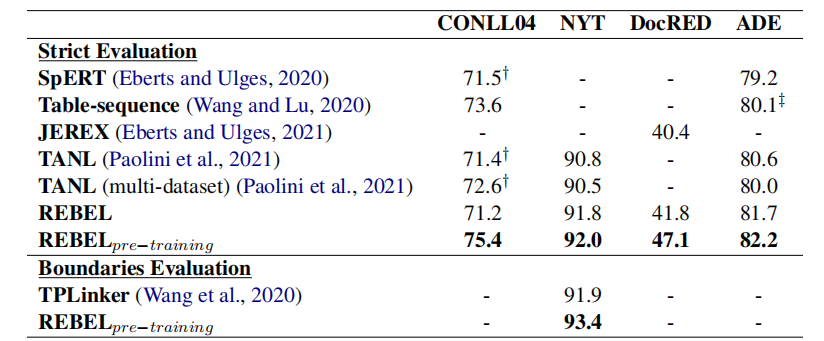
- REBELpre−training在所有数据集上都超过了SOTA模型性能,而没有进行预训练的REBEL模型性能有所下降,尤其是在规模更小或有更多实体类别的数据集上,但仍然达到了可比较的性能。
- REBELpre−training能够灵活的适应新的场景领域,REBEL在构建的数据集上与训练一次,在新的数据集上只需要训练微调很少的epoches就能快速收敛并获得较好的结果。
6.5 UIE
Unifified Structure Generation for Universal Information Extraction, ACL 2022
[动机]:当前信息抽取IE由于其不同的抽取目标(实体、关系、事件、情感)、异质的抽取结构(实体->span片段、关系->三元组、事件->记录)、不同的schema模式使其任务非常多样。当前IE方法都是任务特定的(Task-Specialized),针对不同的IE任务构建专用的架构、独立的模型和专用的知识源,导致了以下三个问题: ① 为大量不同的IE任务、配置、场景开发专用的模型架构时非常复杂的;② 学习独立的模型严重限制了相关任务和配置间的知识共享;③ 针对不同IE任务构建数据集和知识源是非常昂贵和耗时的。因此,开发一种通用的 IE 架构(Universal IE),可以对不同的 IE 任务进行统一建模,自适应地预测异构结构并有效地从各种资源中学习。
针对以上问题,作者提出了一个统一的文本到结构(text-to-structure)的生成式信息抽取模型-UIE,它能够对不同的IE任务进行统一的建模、自适应地生成目标结构、从不同的知识源协同学习通用的IE能力。
- 设计了一个结构化抽取语言 ( Structural Extraction Language, SEL ),有效地将不同的IE结构转化成一个统一的表示。因此,各种IE任务可以在同一个text-to-structure框架下进行统一建模。
- 提出了一个结构化模式指导器 ( Structural Schema Instructor, SSI ), 能够针对不同的IE任务自适应的生成目标结构。SSI是一种基于Schema的Prompt机制,控制着不同任务抽取生成的内容。
- 利用从网络上获取的大规模、异质的数据集对UIE进行预训练,学习通用的IE能力,大规模预训练的UIE模型能够快速适用于新的场景、任务、配置。
- Structured Extraction Language for Uniform Structure Encoding (输出机构化)
SEL将异质的信息抽取结构转化成统一输出表示,即实体识别、关系抽取、事件抽取等不同任务的输出经过统一的结构、规则、模型进行编码。IE的结构生成可以分解成两类原子操作:① Spotting:表示定位句子中的目标信息片段,如实体或事件触发词;② Associating:表示链接不同的信息片段Spotting,如实体间的关系或事件的论元的角色。
SEL就是基于Spotting-Associating结构的,SEL表达式包括三中类型的语义单元:① SPOTNAME:表示原文本中存在Spot Name类型的信息片段;② ASSONAME:表示源文本中存在一个特定的信息片段,它与结构中的上层 Spotted 信息具有 AssoName 关联;③ INFOSPAN:表示与文本中特定的Spotting或Associating信息片段相对应的文本片段。如下图为SEL的结构和编码示例:

使用SEL作为生成输出编码的好处有三点:首先,对不同的IE结构统一编码使得不同的IE任务可以建模为相同的text-to-structure生成过程;其次,将句子的所有提取结果高效地表示为相同结构可以自然地进行联合提取;最后,生成的输出结构非常紧凑,大大降低了解码的复杂度。
- Structural Schema Instructor for Controllable IE Structure Generation (输入结构化)
SSI是一种基于schema的prompt机制,它将不同任务的schema作为提示,在抽取过程中自适应地控制那种类型的信息需要被生成。将SSI序列 𝑠=[𝑠1,...,𝑠|𝑠|] 与文本序列 𝑥=[𝑥1,...,𝑥|𝑥|] 拼接作为UIE模型的输入,生成SEL序列𝑦=[𝑦1,...,𝑦|𝑦|]。即 𝑦=𝑈𝐼𝐸(𝑠⊕𝑥) ,UIE利用encoder-decoder的结构(比如BART或T5模型)完成text-to-SEL的生成过程,首先对输入编码获得输入的隐层表示 𝐻 ,然后UIE以自回归的方式对输入解码生成SEL序列,最后将预测的SEL表达式转化成提取的正常记录结构。
下式为输入的形式,SSI作为文本的前缀,其中包括三种类型的token段:① SPOTNAME,比如实体类别;② ASSONAME,比如关系类别;③ ) 特殊符号([spot], [asso], [text]),需要分别放置在 SPOTNAME、ASSONAME和文本的前面。

以实体识别和关系抽取任务为例,SSI如下表所示:

- Pre-training and Fine-tuning for UIE
[ Pre-training ] 作者和REBEL模型类似,利用Wikipedia、Wikidata dump和ConceptNet构建一个大规模预训练语料库对UIE模型进行预训练学习通用的IE能力。作者构建了三部分预训练数据利用三类序列生成任务对UIE进行预训练:
① 𝐷𝑃𝑎𝑖𝑟={(𝑥,𝑦)} 是text-structure并行数据,其中每个样例为<token序列 𝑥 ,结构化记录 𝑦 >。 𝐷𝑃𝑎𝑖𝑟用于学习模型基础的text-to-structure映射生成能力
② 𝐷𝑅𝑒𝑐𝑜𝑟𝑑 是只包含SEL表达式的数据,用于预训练UIE的解码器,学习生成由SEL和schema定义的结构的能力
③ 𝐷𝑇𝑒𝑥𝑡 是原始文本数据,通过T5模型中的掩码语言模型任务预训练UIE,增强模型的语义表示能力
论文将T5 ( Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer ) 作为基本的模型结构,使用T5-v1.1-base and T5-v1.1-large分别初始化UIE-base和UIE-large,并整合上述三个任务对UIE进行预训练,预训练目标函数为: 𝐿=𝐿𝑃𝑎𝑖𝑟+𝐿𝑅𝑒𝑐𝑜𝑟𝑑+𝐿𝑇𝑒𝑥𝑡
[ Fine-tuning ] 利用预训练好的模型 UIEpre_training 可以快速的在不同任务和配置上进行微调,给定新标注的语料库 𝐷𝑡𝑎𝑠𝑘={(𝑠,𝑥,𝑦)} ,通过teacher-forcing的交叉熵损失函数 𝐿𝐹𝑇 微调模型。
为了缓解暴露偏差问题,作者设计了一个Rejection 机制来有效微调模型。给定样例 (𝑠,𝑥,𝑦) ,对进行SEL编码,然后以一定的概率随机插入具有错误SPOTNAME和ASSONAME的[NULL]单元,即 (SPOTNAME, [NULL]) 和 (ASSONAME, [NULL])。这样,UIE 可以通过生成 [NULL] token来有效地拒绝错误的生成。
- 实验分析
[Experiments on Supervised Settings]: UIE模型在4个任务的13数据集上与SOTA模型相相比,大多数数据集上性能均有所提升,或者获得了可比较的性能。这说明UIE这种统一的生成式抽取方式是有效的,大规模的预训练模型确实为通用IE提供能较好的性能基础。最重要的是UIE通过统一的对不同IE任务进行建模并在大规模数据集上预训练,有效捕捉了共享、可迁移的信息抽取能力,这种能力十分重要和有效。
[** **Experiments on Low-resource Settings]: 从实验结果来看,UIE更重要的能力在于处理低资源的信息抽取任务,对于少样本任务性能提升很明显,这仍然是得益于大规模预训练模型、以及多IE任务统一建模预训练。