ollama部署常见问题解答
本文将分为以下章节对 Ollama 进行介绍:
- Ollama 基本介绍,它的作用是什么
- Ollama 软件安装、一些常用的系统参数设置
- Ollama 管理本地已有大模型(包括终端对话界面)
- Ollama 导入模型到本地的三种方式:直接从 Ollama 远程仓库拉取、通过 GGUF 模型权重文件导入到本地、通过 safetensors 模型权限文件导入到本地
- 基于 WebUI 部署 Ollama 可视化对话界面
- Ollama 客户端 API 应用,包括 Python API 和 Java API 接口应用
Ollama 是什么,它与 Llama 有什么关系?
Ollama官网:https://ollama.com/,官方网站的介绍就一句话:Get up and running with large language models. (开始使用大语言模型。)
Ollama是一个开源的 LLM(大型语言模型)服务工具,用于简化在本地运行大语言模型、降低使用大语言模型的门槛,使得大模型的开发者、研究人员和爱好者能够在本地环境快速实验、管理和部署最新大语言模型,包括如Qwen2、Llama3、Phi3、Gemma2等开源的大型语言模型。
Ollama支持的大语言模型列表,可通过搜索模型名称查看:https://ollama.com/library
Ollama官方 GitHub 源代码仓库:https://github.com/ollama/ollama/
Llama是 Meta 公司开源的备受欢迎的一个通用大语言模型,和其他大模型一样,Llama可以通过Ollama进行管理部署和推理等。
因此,Ollama与Llama的关系:Llama是大语言模型,而Ollama是大语言模型(不限于Llama模型)便捷的管理和运维工具,它们只是名字后面部分恰巧相同而已!
Ollama 安装和常用系统参数设置
在官网首页,我们可以直接下载Ollama安装程序(支持 Windows/MacOS/Linux):https://ollama.com/
Ollama的安装过程,与安装其他普通软件并没有什么两样,安装完成之后,有几个常用的系统环境变量参数建议进行设置:
- OLLAMA_MODELS:模型文件存放目录,默认目录为当前用户目录(Windows
目录:
C:\Users%username%.ollama\models,MacOS 目录:~/.ollama/models,Linux 目录:/usr/share/ollama/.ollama/models),如果是 Windows 系统建议修改(如:D:),避免 C 盘空间吃紧 - OLLAMA_HOST:Ollama 服务监听的网络地址,默认为127.0.0.1,如果允许其他电脑访问 Ollama(如:局域网中的其他电脑),建议设置成0.0.0.0,从而允许其他网络访问
- OLLAMA_PORT:Ollama 服务监听的默认端口,默认为11434,如果端口有冲突,可以修改设置成其他端口(如:8080等)
- OLLAMA_ORIGINS:HTTP 客户端请求来源,半角逗号分隔列表,若本地使用无严格要求,可以设置成星号,代表不受限制
- OLLAMA_KEEP_ALIVE:大模型加载到内存中后的存活时间,默认为5m即 5 分钟(如:纯数字如 300 代表 300 秒,0 代表处理请求响应后立即卸载模型,任何负数则表示一直存活);我们可设置成24h,即模型在内存中保持 24 小时,提高访问速度
- OLLAMA_NUM_PARALLEL:请求处理并发数量,默认为1,即单并发串行处理请求,可根据实际情况进行调整
- OLLAMA_MAX_QUEUE:请求队列长度,默认值为512,可以根据情况设置,超过队列长度请求被抛弃
- OLLAMA_DEBUG:输出 Debug 日志标识,应用研发阶段可以设置成1,即输出详细日志信息,便于排查问题
- OLLAMA_MAX_LOADED_MODELS:最多同时加载到内存中模型的数量,默认为1,即只能有 1 个模型在内存中
Ollama 管理本地已有大模型
【展示本地大模型列表:ollama list】
1 | |
可以看到,本地有 2 个大模型,它们的名称(NAME)分别为gemma2:9b和qwen2:7b。
【删除单个本地大模型:ollama rm 本地模型名称】
1 | |
通过rm命令删除了gemma2:9b大模型之后,再次通过list命令查看,本地只有qwen2:7b一个大模型了。
【设置模型下载目录:ollama run 本地模型名】
模型默认存储地址为:
macOS: ~/.ollama/models Linux: /usr/share/ollama/.ollama/models #作为系统服务启动时 Linux: /home/
/.ollama/models #当前用户启动时 Windows: C:<username>.ollama
Windows用户
- 设置 OLLAMA_MODELS
2
3
4
5
6# 只设置当前用户
setx OLLAMA_MODELS "D:\ollama_model"
# 为所有用户设置
setx OLLAMA_MODELS "D:\ollama_model" /M
TEXT
- 重启终端(setx命令在Windows中设置环境变量时,这个变量的更改只会在新打开的命令提示符窗口或终端会话中生效。)
- 重启ollama服务
Linux一般用户
2
3
4
5
6# 打开下面文件
nano ~/.bashrc
# 添加设置
export OLLAMA_MODELS="/path/to/ollama_model"
TEXT
- 重启终端
- 重启ollama服务: ollama serve
或者直接使用: OLLAMA_MODELS="/path/to/ollama_model" ollama serve 启动服务
Liunx root 服务模式 在服务文件中设置环境变量,并且要为新的目录设置ollama用户的读写权限
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21# 打开服务文件
sudo nano /etc/systemd/system/ollama.service
# 在文件中Service字段后添加
[Service]
Environment="OLLAMA_MODELS=/home/xxx/ollama/models"
Environment="http_proxy=xxxxxx"
# 设置目录访问权限 (根据反馈做了些调整)
sudo chown ollama:ollama /home/xxx/ollama
sudo chmod u+w /home/xxx/ollama
sudo chown ollama:ollama /home/xxx/ollama/models
sudo chmod u+w /home/xxx/ollama/models
# 重启服务
sudo systemctl daemon-reload
sudo systemctl restart ollama.service
# 确认状态
sudo systemctl status ollama.service
TEXT注:有小伙伴反馈,修改模型存储目录时,如果只设置 /home/xxx/ollama/models 目录的权限会出现 mkdir 没有权限的错误。所以,建议对目录 /home/xxx/ollama/models 和 /home/xxx/ollama 都为ollama用户赋予读写权限(2024)
【启动本地模型:ollama run 本地模型名】
1 | |
启动成功之后,就可以通过终端对话界面进行对话了(本命令下面也会讲到,其他详细暂且忽略)
【查看本地运行中模型列表:ollama ps】
1 | |
通过ps命名可以看到,本地qwen2:0.5b大模型正在运行中。
【复制本地大模型:ollama cp 本地存在的模型名 新复制模型名】
1 | |
上面cp命令,把本地qwen2:0.5b复制了一份,新模型名为Qwen2-0.5B
下面介绍三种通过 Ollama 下载到本地大模型方式:
- 方式一:直接通过 Ollama 远程仓库下载,这是最直接的方式,也是最推荐、最常用的方式
- 方式二:如果已经有 GGUF 模型权重文件了,不想重新下载,也可以通过 Ollama 把该文件直接导入到本地(不推荐、不常用)
- 方式三:如果已经有 safetensors 模型权重文件,也不想重新下载,也可以通过 Ollama 把该文件直接导入到本地(不推荐、不常用)
方式一:Ollama 从远程仓库下载大模型到本地
【下载或者更新本地大模型:ollama pull 本地/远程仓库模型名称】
本pull命令从 Ollama
远程仓库完整下载或增量更新模型文件,模型名称格式为:模型名称:参数规格;如ollama pull qwen2:0.5b
则代表从 Ollama
仓库下载qwen2大模型的0.5b参数规格大模型文件到本地磁盘:
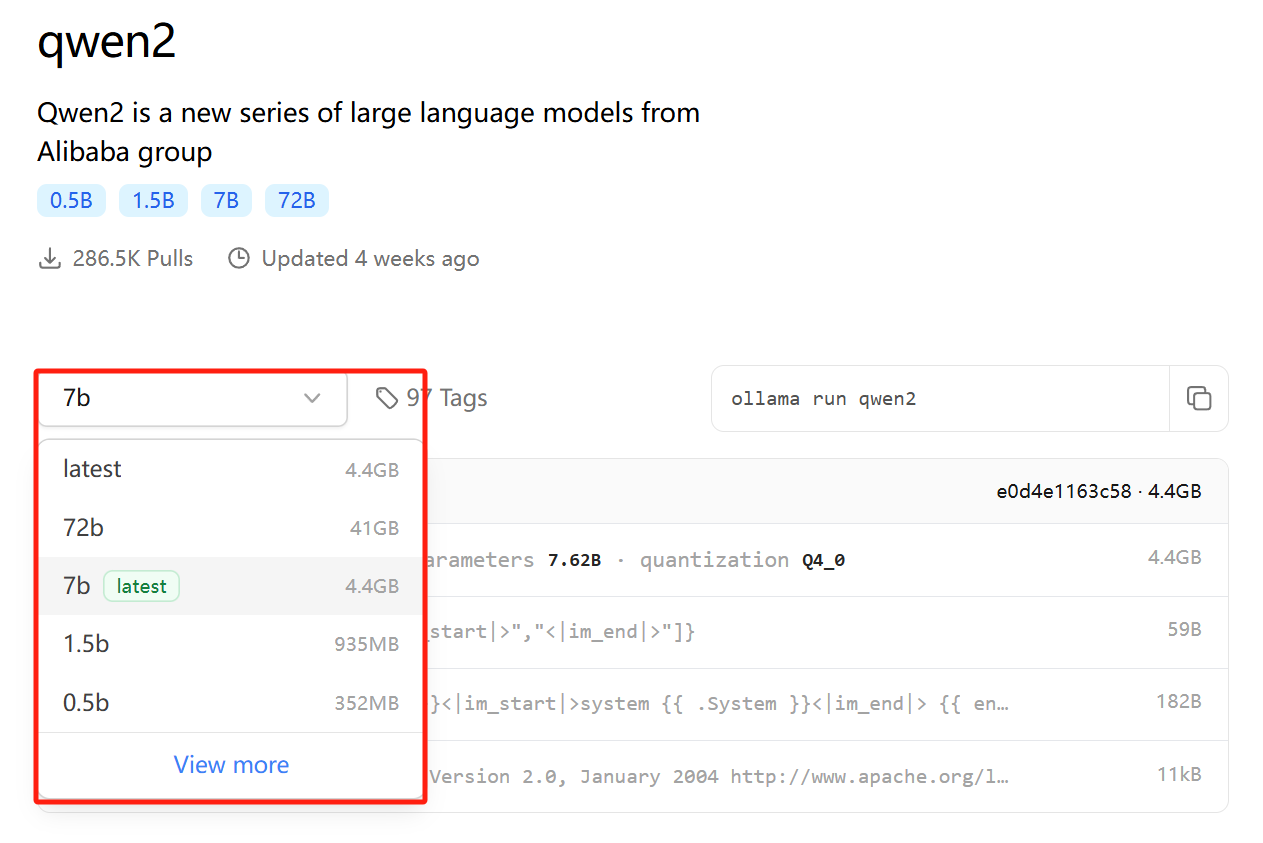
如果参数规格标记为latest则代表为默认参数规格,下载时可以不用指定,如Qwen2的7b被标记为latest,则ollama pull qwen2和ollama pull qwen2:7b这
2
个命令的意义是一样的,都下载的为7b参数规格模型。为了保证后续维护方便、避免误操作等,建议不管是否为默认参数规格,我们下载命令中均明确参数规格。
值得一提的是,今天开始GLM4支持 Ollama
部署和推理,特意列出它的下载命令:ollama pull glm4:9b(和其他模型相比,其实并没有特殊支出)。需要注意的是:Ollama
最低版本为0.2.0才能支持GLM4大模型!
1 | |
若本地不存在大模型,则下载完整模型文件到本地磁盘;若本地磁盘存在该大模型,则增量下载大模型更新文件到本地磁盘。
从上面最后的list命令结果可以看到,本地存在了qwen2:0.5b这个名称的大模型。
【下载且运行本地大模型:ollama run 本地/远程仓库模型名称】
1 | |
若本地不存在大模型,则下载完整模型文件到本地磁盘(类似于pull命令),然后启动大模型;若本地存在大模型,则直接启动(不进行更新)。
启动成功后,默认为终端对客界面:

- 若需要输入多行文本,需要用三引号包裹,如:
"""这里是多行文本""" /clear清除对话上下文信息/bye则退出对话窗口/set parameter num_ctx 4096可设置窗口大小为 4096 个 Token,也可以通过请求设置,如:curl <http://localhost:11434/api/generate> -d '{ "model": "qwen2:7b", "prompt": "Why is the sky blue?", "options": { "num_ctx": 4096 }}'/show info可以查看当前模型详情: ,
1 | |
方式二:Ollama 导入 GGUF 模型文件到本地磁盘
若我们已经从 HF 或者 ModeScope 下载了 GGUF
文件(文件名为:Meta-Llama-3-8B-Instruct.Q4_K_M.gguf),在我们存放Llama3-8B的
GGUF
模型文件目录中,创建一个文件名为Modelfile的文件,该文件的内容如下:
1 | |
然后,打开终端,执行命令导入模型文件:ollama create 模型名称 -f ./Modelfile
1 | |
导入成功之后,我们就可以通过list命名,看到名为Llama-3-8B的本地模型了,后续可以和其他模型一样进行管理了。
方式三:Ollama 导入 safetensors 模型文件到到本地磁盘
官方操作文档:https://ollama.fan/getting-started/import/#importing-pytorch-safetensors
若我们已经从 HF 或者 ModeScope 下载了 safetensors 文件(文件目录为:Mistral-7B),
1 | |
然后,我们转换模型(结果:Mistral-7B-v0.3.bin):
1 | |
接下来,进行量化量化:
1 | |
最后,通过 Ollama
导入到本地磁盘,创建Modelfile模型文件:
1 | |
执行导入命令,导入模型文件:ollama create 模型名称 -f ./Modelfile
1 | |
导入成功之后,我们就可以通过list命名,看到名为Mistral-7B-v0.3的本地模型了,后续可以和其他模型一样进行管理了。
基于 WebUI 部署 Ollama 可视化对话界面
Ollama自带控制台对话界面体验总归是不太好,接下来部署 Web 可视化聊天界面:
- 下载并安装 Node.js 工具:https://nodejs.org/zh-cn
- 下载
ollama-webui工程代码:git clone https://github.com/ollama-webui/ollama-webui-lite ollama-webui - 切换
ollama-webui代码的目录:cd ollama-webui - 设置 Node.js
工具包镜像源(下载提速):
npm config set registry http://mirrors.cloud.tencent.com/npm/ - 安装 Node.js 依赖的工具包:
npm install - 最后,启动 Web 可视化界面:
npm run dev
如果看到以上输出,代表 Web 可视化界面已经成功了!
浏览器打开 Web 可视化界面:http://localhost:3000/
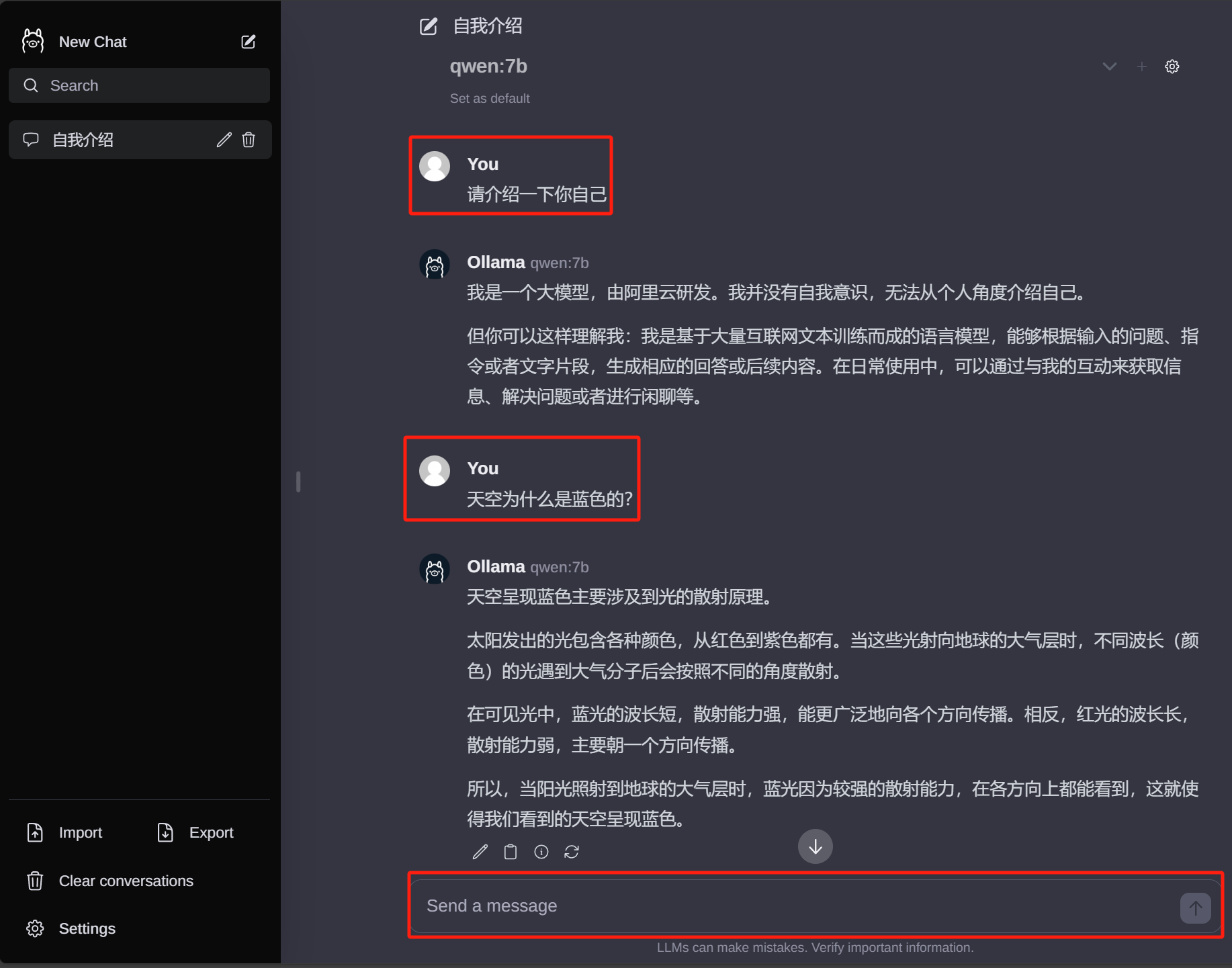
Ollama 客户端:HTTP 访问服务
Ollama 默认提供了generate和chat这 2
个原始的 API 接口,使用方式如下:
generate接口的使用样例:
1 | |
chat接口的使用样例:
1 | |
接下来的Python和Java客户端应用,都是对这 2 个接口的封装。
Ollama 客户端:Python API 应用
我们把 Ollama 集成到 Python 应用中,只需要以下简单 2 步即可:
第一步,安装 Python 依赖包:
1 | |
第二步,使用 Ollama
接口,stream=True代表按照流式输出:
1 | |
Ollama 客户端:Java API 应用(SpringBoot 应用)
我们也可以把 Ollama 集成到 SpringBoot 应用中,只需要以下简单 3 步即可:
第一步,在总pom.xml中新增 SpringBoot
Starter 依赖:
1 | |
第二步,在 SpringBoot
配置文件application.properties中增加 Ollama 配置信息:
1 | |
配置文件指定了 Ollama API 地址和端口,同时指定了默认模型qwen:0.5b(注意:模型需要在本地已经存在)
第三步,使用OllamaChatClient进行文字生成或者对话:
1 | |
以上是 Java
客户端的简单样例,我们可以通过OllamaChatClient访问 Ollama
接口,既可以使用默认大模型,也可以在参数指定模型名称!
Ollama部署常见问题解答
1 如何修改下载模型的默认存放目录?
Windows用户
- 设置 OLLAMA_MODELS
1 | |
- 重启终端(setx命令在Windows中设置环境变量时,这个变量的更改只会在新打开的命令提示符窗口或终端会话中生效。)
- 重启ollama服务
Linux一般用户
1 | |
- 重启终端
- 重启ollama服务: ollama serve
或者直接使用: OLLAMA_MODELS="/path/to/ollama_model" ollama serve 启动服务
Liunx root 服务模式 在服务文件中设置环境变量,并且要为新的目录设置ollama用户的读写权限
1 | |
注:有小伙伴反馈,修改模型存储目录时,如果只设置 /home/xxx/ollama/models 目录的权限会出现 mkdir 没有权限的错误。所以,建议对目录 /home/xxx/ollama/models 和 /home/xxx/ollama 都为ollama用户赋予读写权限(2024.04.28)。
2 ollama下载的模型与huggingface上的模型有什么区别?
通常情况下,Qwen 模型的表示方法为 Qwen1.5-4B-Chat。在
Ollama 中,Qwen 指代的是与 Hugging Face 上的
qwen1_5-4B-Chat-q4_0.gguf 模型相对应的版本,这是一个经过 4
位量化处理的模型。
ollama提供的qwen模型:默认为4B,4bit量化模型,大小为2.3G
3 什么是Modelfile? 它的作用是什么?
在创建自定义模型时,需要一个配置文件来指定模型推理相关的设置。
这个文件仅在创建自定义模型过程中是必需的。若需修改模型推理的参数,必须重新创建模型,可以通过在
modelfile 中调整参数来实现。
4 自定义模型:如何 create 自定义模型(基于GGUF格式)?
制作自定义模型的过程如下(GGUF格式),以qwen1.5 0.5B模型为例:
- 下载模型 qwen1_5-0_5b-chat-q4_0.gguf
1 | |
- 准备modelfile文件
1 | |
- 创建模型
1 | |
5 自定义模型:模型创建后去了哪里?
模型被创建后,会被存放在以下位置: 模型文本被存储在:
/home/<username>/.ollama/models/blobs
配置文件位于:/home/<username>/.ollama/models/manifests/registry.ollama.ai/library/qwen0_5b/latest
6 如何重新修改模型的 temperature 等参数?
模型被创建后,修改temperature等参数,需要重新create模型。
通过以下命令可以查看一个模型的 modelfile 设置
1 | |
可以看到这些数据都被存放到了 /home//.ollama/models/blobs/sha256:46a9de8316739892e2721fdc49f8353155e4c1bcfa0b17867cb590d2dfdf1d99 文件中(此文件是二进制文件)。通过重新create模型,可以修改里面的参数。
7 如何导入 PyTorch,Safetensors 格式的模型?
ollama只支持GGUF格式的模型进行导入。对于pytorch和safetensors的模型,需要转换为gguf格式之后再导入。 具体步骤,请参考:https://github.com/ollama/ollama/blob/main/docs/import.md
8 是否可以链接WebUI,有什么WebUI推荐?
ollama github首页中推荐了多种WebUI和终端访问方法的相关项目。 https://github.com/ollama/ollama (Community Integrations部分)
安装教程:Windows上如何安装Open WebUI B站:
油管:
Linux安装教程请访问: https://techdiylife.github.io/blog/blog.html?category1=c02&blogid=0036
9 如何对ollama进行速度评价?
当以普通用户身份启动服务时,可以在终端界面查看推理速度。比如 {"function":"print_timings","level":"INFO","line":257,"msg":"prompt eval time = 25.55 ms / 12 tokens ( 2.13 ms per token, 469.70 tokens per second)","n_prompt_tokens_processed":12,"n_tokens_second":469.70408642555196,"slot_id":0,"t_prompt_processing":25.548,"t_token":2.129,"task_id":111,"tid":"140543230871296","timestamp":1711096105}
可以看到有:2.13 ms per token, 469.70 tokens per second
在Windows或者Linux上以服务启动时,也可以在日志文件中找到这些数据。
1 | |
10 Ollama是否可以对模型精度评价?
在ollama工具中,没有直接的方式来评估模型性能。然而,在llama.cpp中,有提供测试数据集,以及使用Perplexity指标来进行模型评估的示例。
常见LLM大模型评估方法如下:
- 主观评价:通过人工审查模型的输出,评估其生成内容的质量和相关性。
- 测试集评价:利用特定的测试数据集,对模型性能进行量化评估。这种方法的细节可以参考相关模型的技术报告。
- 利用其他模型进行评价:例如,使用GPT-4对ollama模型的输出结果进行评估,以此来比较不同模型的性能。
11 Linux系统中以服务模式运行ollama,如何查看运行日志?
使用以下命令可以查看ollama的日志:
1 | |
12 Linux系统中如何卸载Ollama?
在Windows和MacOS上,卸载ollama的过程与卸载其他软件相同,支持一键卸载。
而在Linux上,卸载ollama需要执行更多步骤,包括关闭运行中的服务以及删除相关文件。具体操作步骤,请参考官方文档中的“Uninstall”部分: https://github.com/ollama/ollama/blob/main/docs/linux.md
13 上网需要使用代理时,模型无法下载怎么办?
出现错误: Error: pull model manifest: Get "https://registry.ollama.ai/v2/library/qwen/manifests/0.5b": dial tcp 34.120.132.20:443: i/o timeout
原因分析: 代理设置不正确。
- 服务文件中设置环境变量(sudo安装时):
在以服务启动后,默认以
ollama用户的身份运行。可以为ollama.service 服务设置环境变量。
1 | |
- 以当前用户身份启动服务(一般用户): 通过为当前用户设置代理,然后以当前用户的身份启动服务。这要求当前用户具有启动该服务所需的权限。
方法1:.bashrc中设置
1
2
3
4
5
6# 在本地账户 .bashrc 文件中加入
export HTTP_PROXY=xxxxxxxxxxx
export HTTPS_PROXY=xxxxxxxxxxx
# 启动服务
ollama serve 启动(不能使用 sudo systemctl start ollama.service)方法2:通过下面的方式启动服务
1
HTTPS_PROXY=xxxxxxxxxxx ollama serve
参考资料:https://github.com/ollama/ollama/issues/1859
14 有多个GPU时,如何指定使用单张GPU?
ollama默认会使用所有它可见的GPU,如果希望限制它只使用其中的某个GPU时,可以在环境变量中设置 CUDA_VISIBLE_DEVICES,比如: export CUDA_VISIBLE_DEVICES=0
15 ollama是否支持RAG?
ollama本身不支持RAG,但是可以结合langchain等工具来实现,比如: https://github.com/ollama/ollama/tree/main/examples/langchain-python-rag-websummary
16 补充:Ollama模型库中instruct,text等tag是指什么模型?
如下图所示的llama3模型有70b, 8b, instruct, text 都分别对应着什么模型呢?

可以在模型的说明中找到相关的解释。没有特殊标记的对应着chat版本,也就是经过指令微调的模型。 而text版本则对应着base model,也就是预训练模型。
17 补充:Open WebUI 与现有服务端口冲突,如何修改端口?
- 如果是使用docker安装运行,可以在docker命令中修改:
1 | |
- 如果是通过代码安装,启动
1 | |
18 补充:Ollama支持中文名用户名,或者目录吗?
从0.1.33版开始增加了对中文名目录的支持。 https://github.com/ollama/ollama/issues/3367 0.1.33之前的版本不支持。如果你使用的老版本,请检查:
- 你的windows用户名是否为中文名
- ollama的模型存放目录是否包含中文
如果存在以上情况,可以修改ollama模型默认存放目录。(修改方式参考,问题6)
19 补充:Ollama使用一段时间后,为什么会自动停止?
很大的原因是由于资源不足,比如GPU显存不足等。
- 查看ollama的日志看看是否有记录
- 尝试较小的模型,比如qwen 0.5B的模型看看是否出现同样的问题。
20 补充:windows上安装完后,在终端执行提示 ollama 不是内部或外部命令
【根据群里小伙伴的讨论整理】
- 设置环境变量 PATH: win+r打开运行,输入“control system”-高级系统设置-高级-环境变量-系统变量-编辑Path-新建-确定。
- 设置PATH后重新启动ollama服务,在ollama图标上点击右键,以管理员身份启动。 启动后,在右下角任务栏中确认是否有ollama的“小羊”图标
- 启动终端输入:ollama run qwen 确认是否可以运行(如果出错,可以尝试以管理员身份)
21 补充:Windows系统,提示错误 Error:Could not connect to ollama app, is it running
运行 ollama run xxx 出现此错误,说明ollama没有正确启动。 可以尝试:
- 关闭ollama程序
- 以管理员身份重新启动ollama。
参考资料
- Docker官网:https://www.docker.com/products/docker-desktop/
- Ollama官网:https://ollama.com/
- Open WebUI Github地址:https://github.com/open-webui/open-webui
- Ollama 官方QA:https://github.com/ollama/ollama/blob/main/docs/faq.md