从头开始实现llama3
都说大模型是黑箱玄学,这次让我们打开黑箱,一起来探索它内部的世界。
在这个文件中,我从头开始实现了 llama3,一次一个张量和矩阵乘法。另外,我将直接从Meta为 llama3 提供的模型文件加载张量,您需要在运行此文件之前下载权重。这是下载权重的官方链接:https://llama.meta.com/llama-downloads/
1.分词器(tokenizer)
我不会实现 bpe tokenizer(但 andrej karpathy 有一个非常干净的实现) 他的实现链接:[https://github.com/karpathy/minbpe)
1 | |
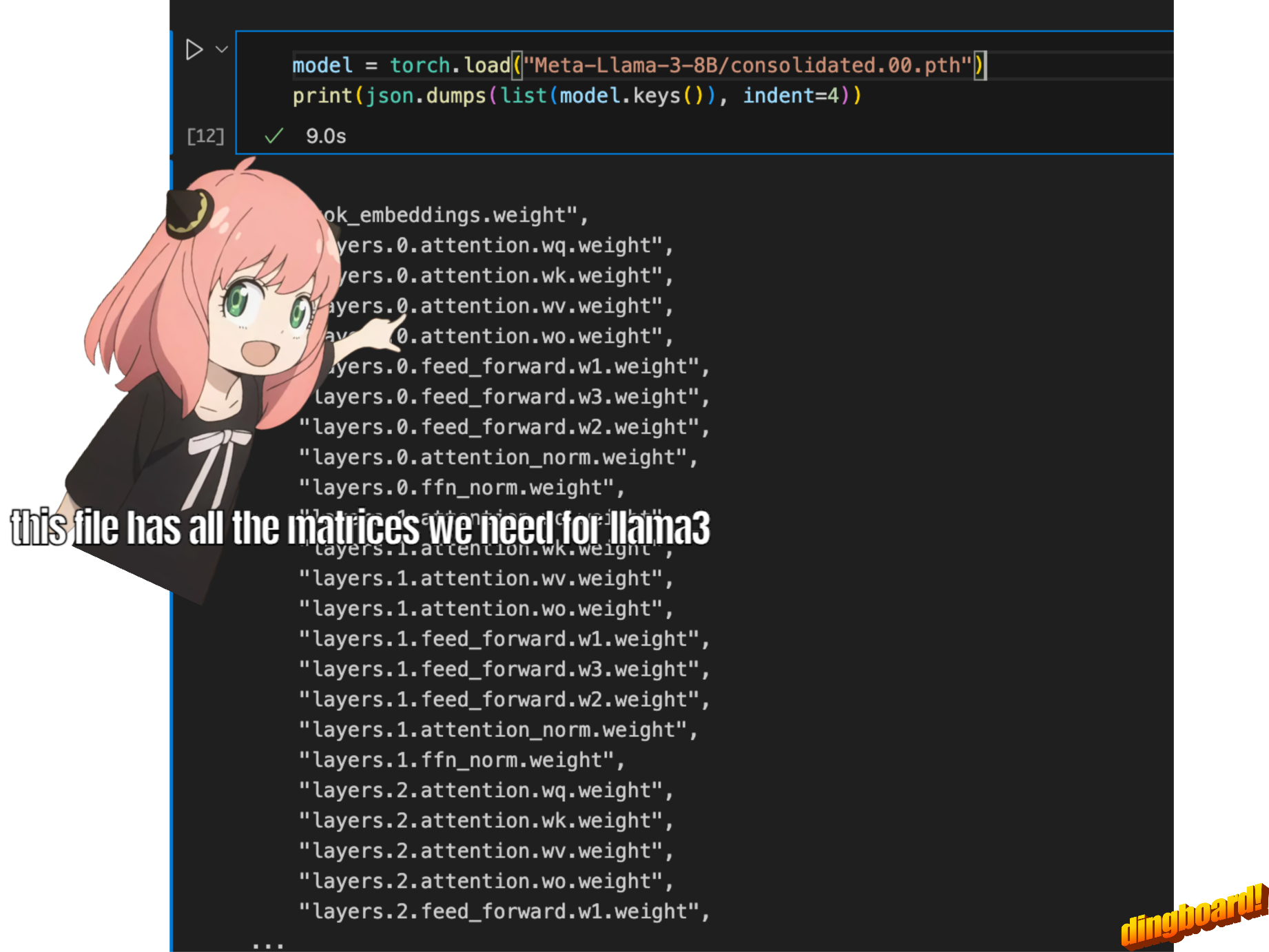
2.读取模型文件
通常,阅读本文取决于模型类的编写方式以及其中的变量名称。 但由于我们是从头开始实现 llama3,因此我们将一次读取一个张量文件。
1 | |
我们使用此配置来推断有关模型的详细信息,例如
- 该模型有 32 个transformer layers
- 每个多头注意力块有 32 个头
- 词汇大小等等
1 | |
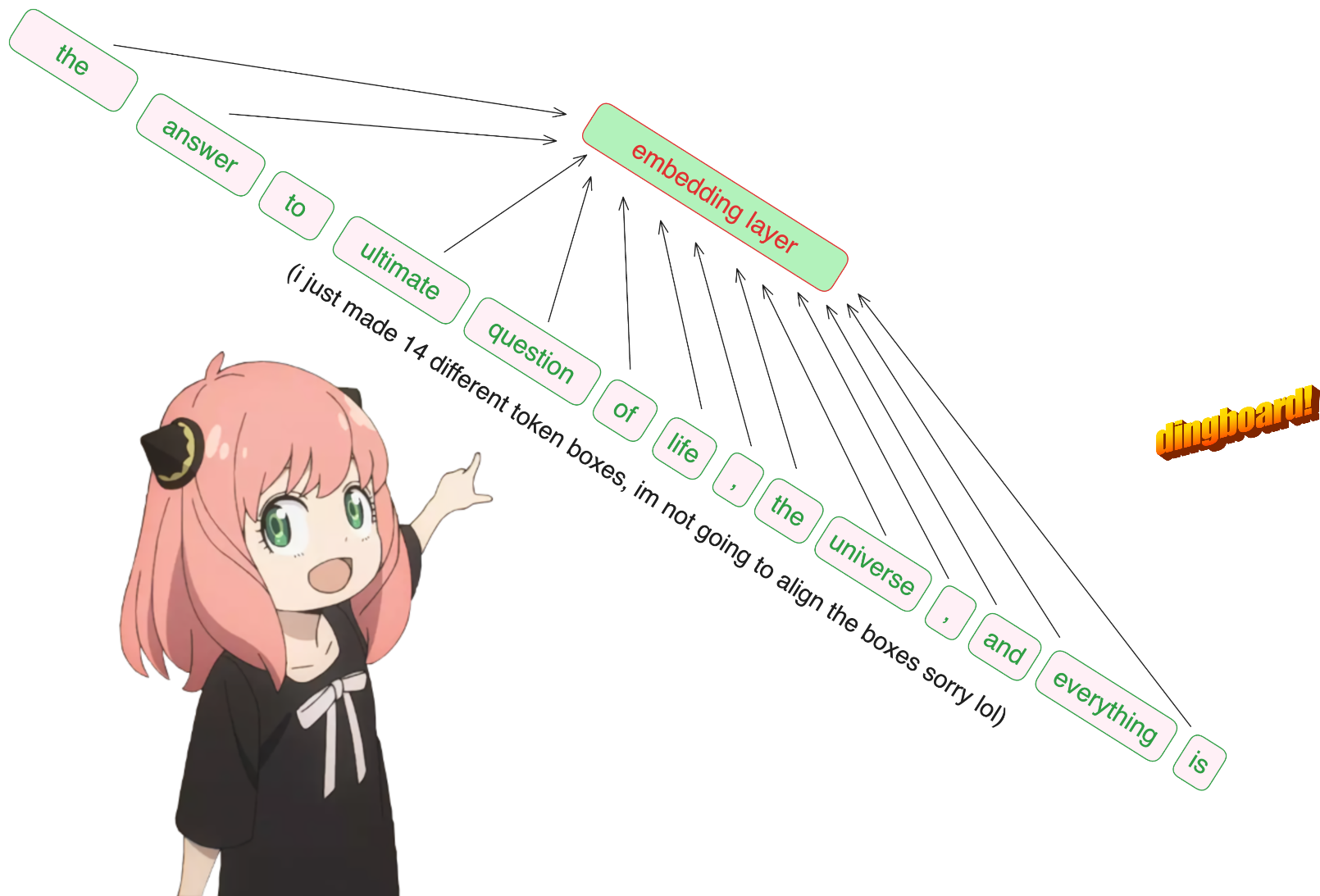
将文本转换为标记(tokens)
这里我们使用 tiktoken (我认为是一个 openai 库)作为 tokenizer
1 | |
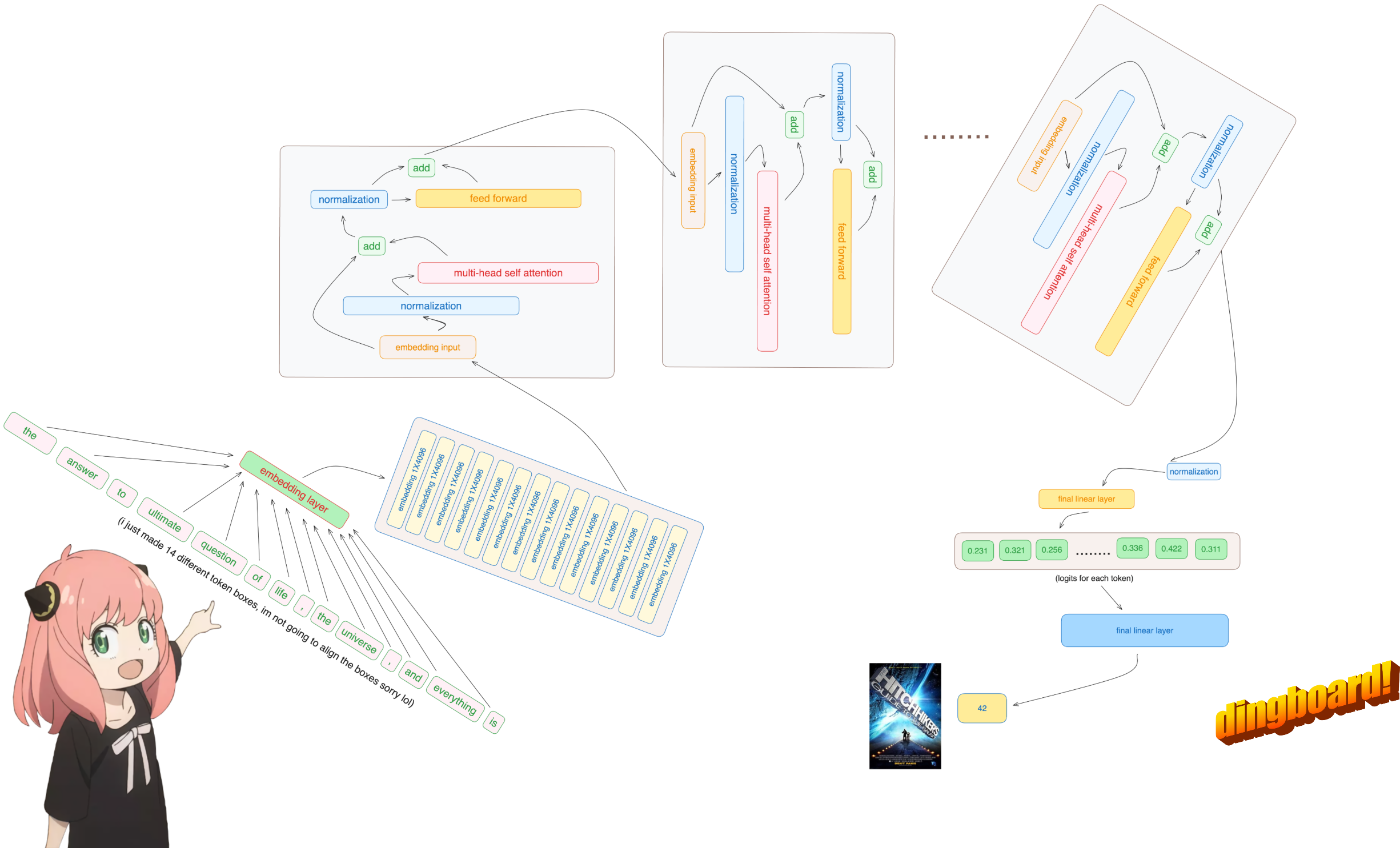
将标记转换为嵌入(embedding)
抱歉,但无论如何,这是代码库中我使用内置神经网络模块的唯一部分,因此我们的 [17x1] 标记现在是 [17x4096],即长度为 4096 的 17 个嵌入(每个标记一个) 注意:跟踪形状,它让你更容易理解一切

1 | |
然后我们使用 rms 归一化对嵌入进行归一化
请注意,在这一步之后,形状不会改变,这些值只是需要记住的标准化内容,我们需要一个norm_eps(来自配置),因为我们不想意外地将rms设置为0并除以0,这里是公式:

1 | |
3.构建transformer的第一层
正常化
无论如何,你会看到我从模型字典访问layer.0(这是第一层),所以在标准化之后我们的形状仍然[17x4096]与嵌入相同但标准化

1 | |
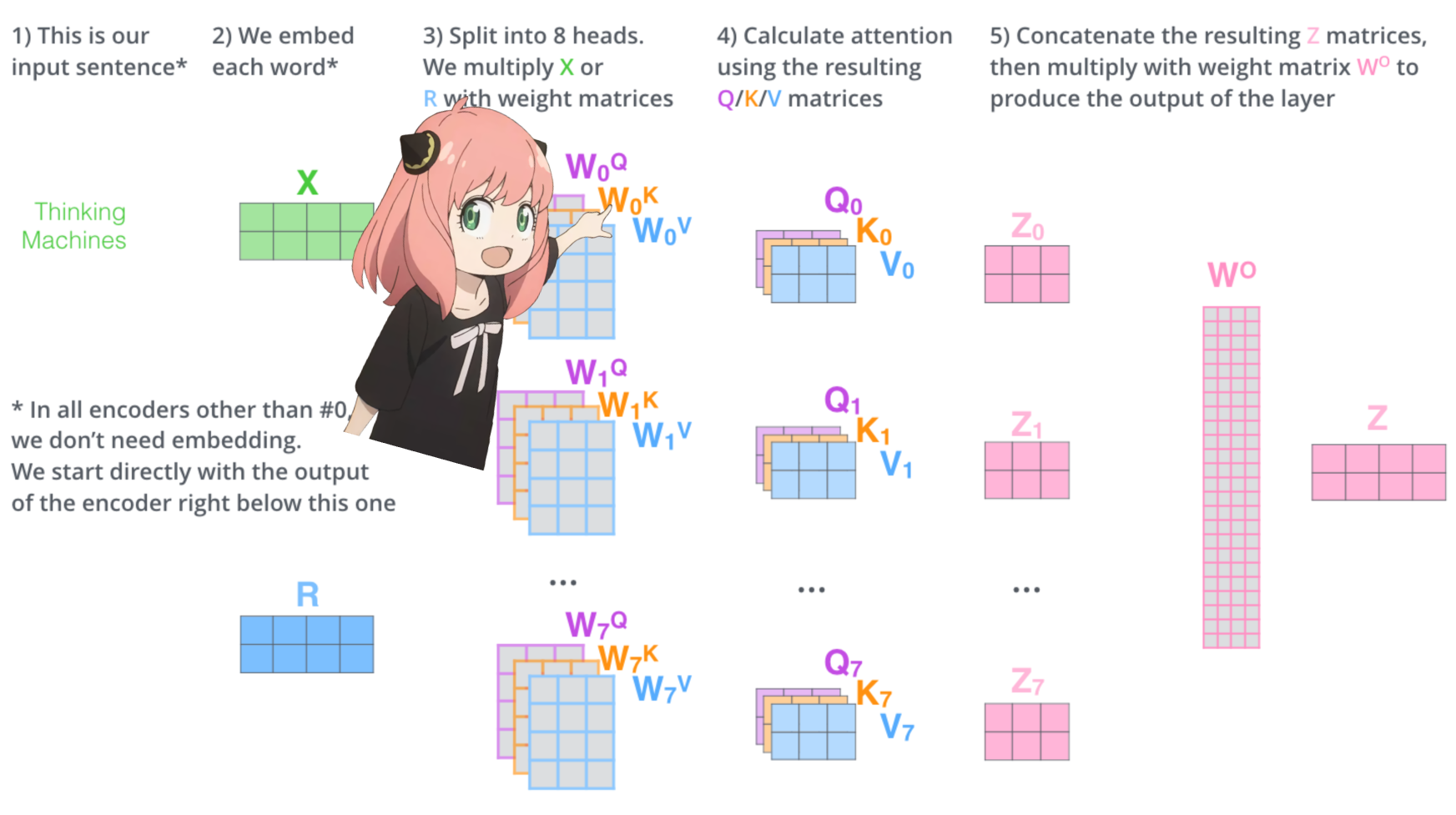
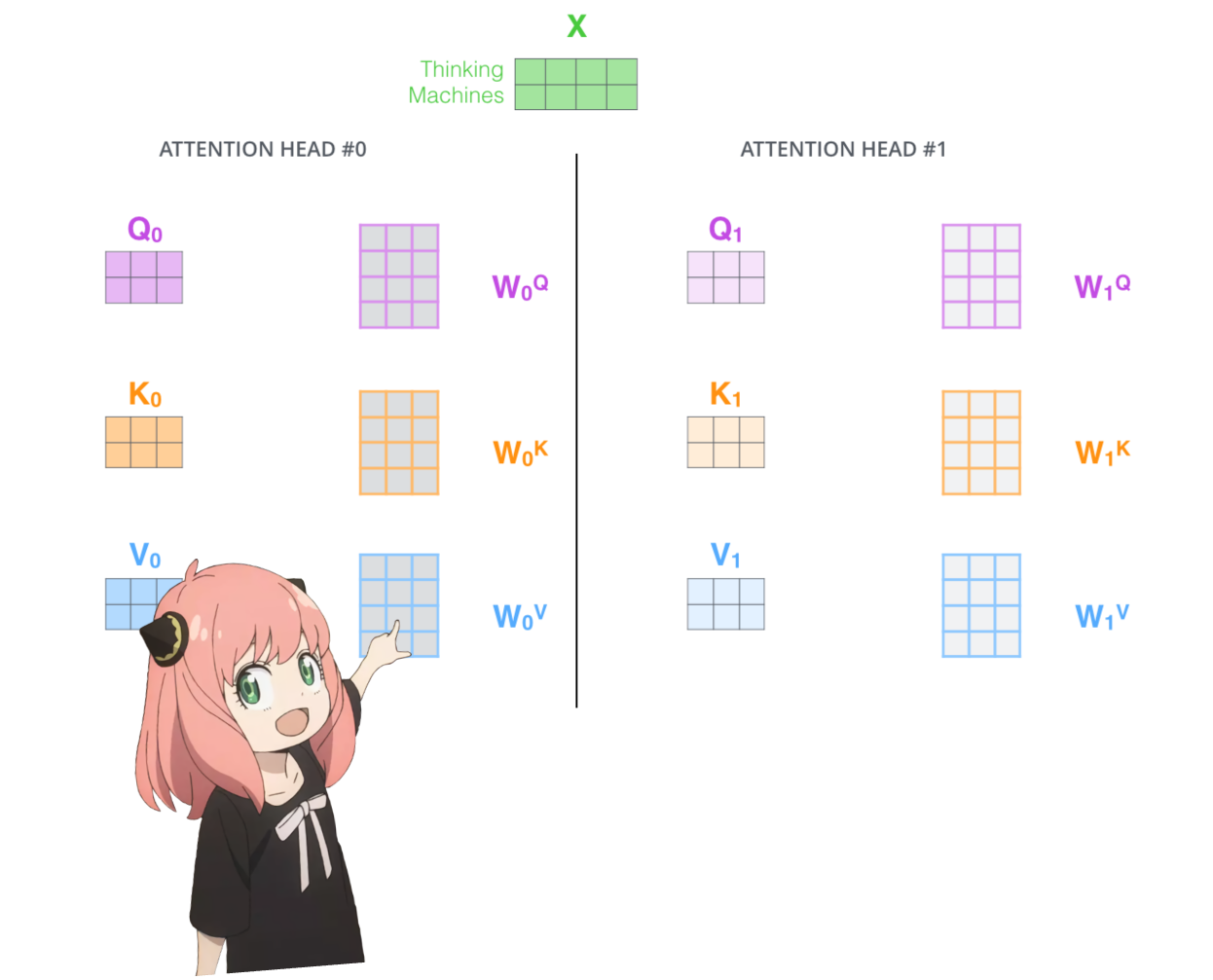
从头开始实施注意力
让我们加载transformer第一层的注意力头
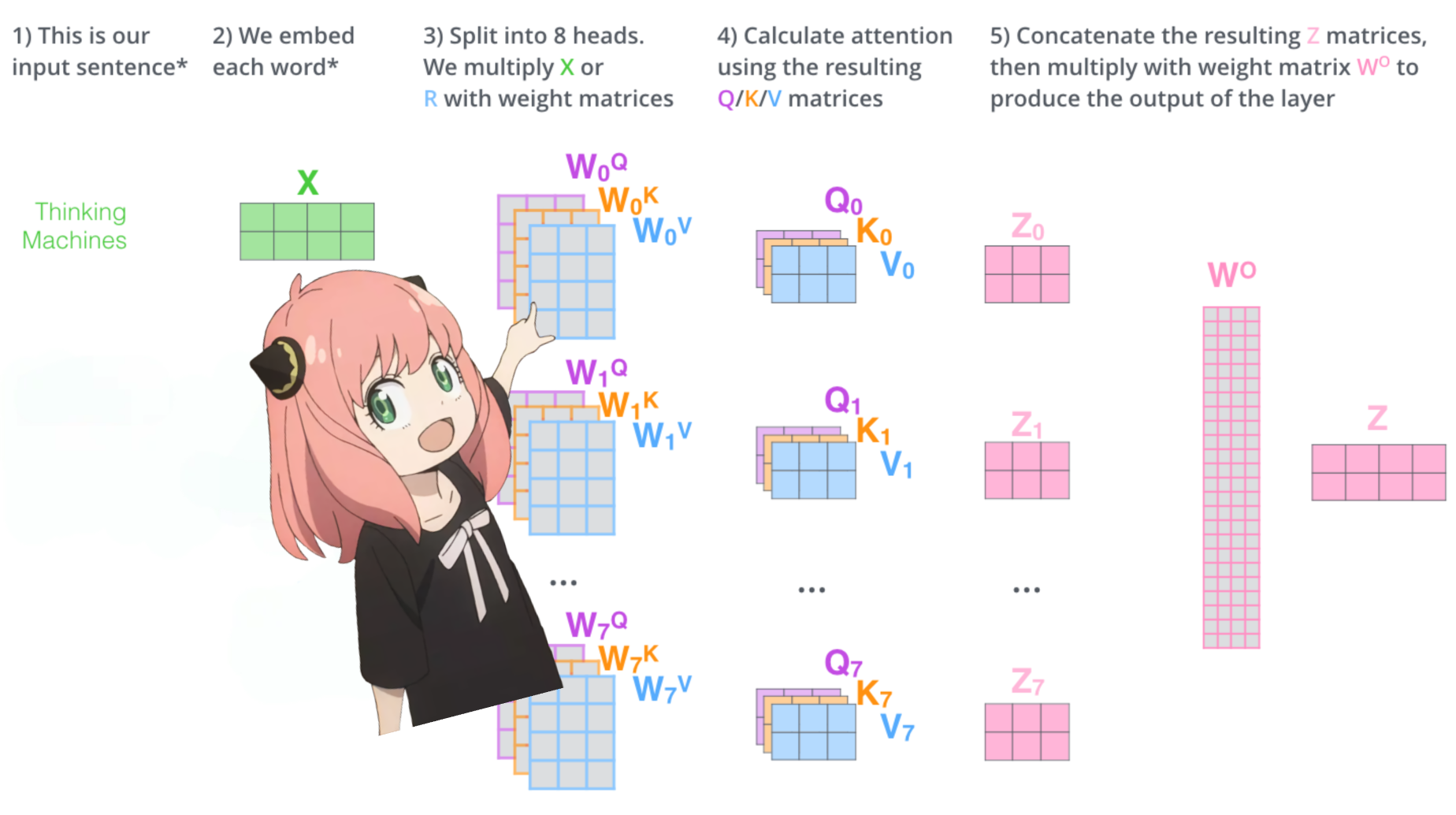
> 当我们从模型加载查询、键、值和输出向量时,我们注意到形状为 [4096x4096]、[1024x4096]、[1024x4096]、[4096x4096] > 乍一看这很奇怪,因为理想情况下我们想要每个 q ,k,v 和 o 分别代表每个头 > 代码的作者将它们捆绑在一起,因为它很容易,有助于并行化注意力头乘法。 > 我要打开所有东西...
1 | |
展开查询
在下一节中,我们将从多个注意力头中解开查询,生成的形状为 [32x128x4096],其中 32 是 llama3 中注意力头的数量,128 是查询向量的大小,4096 是令牌嵌入的大小
1 | |
我要实现第一层的第一个头
这里我访问第一层的查询权重矩阵第一个头,这个查询权重矩阵的大小是[128x4096]
1 | |
我们现在将查询权重与令牌嵌入相乘,以接收令牌的查询
在这里你可以看到结果的形状是 [17x128],这是因为我们有 17 个标记,每个标记都有一个 128 长度的查询。

1 | |
定位编码
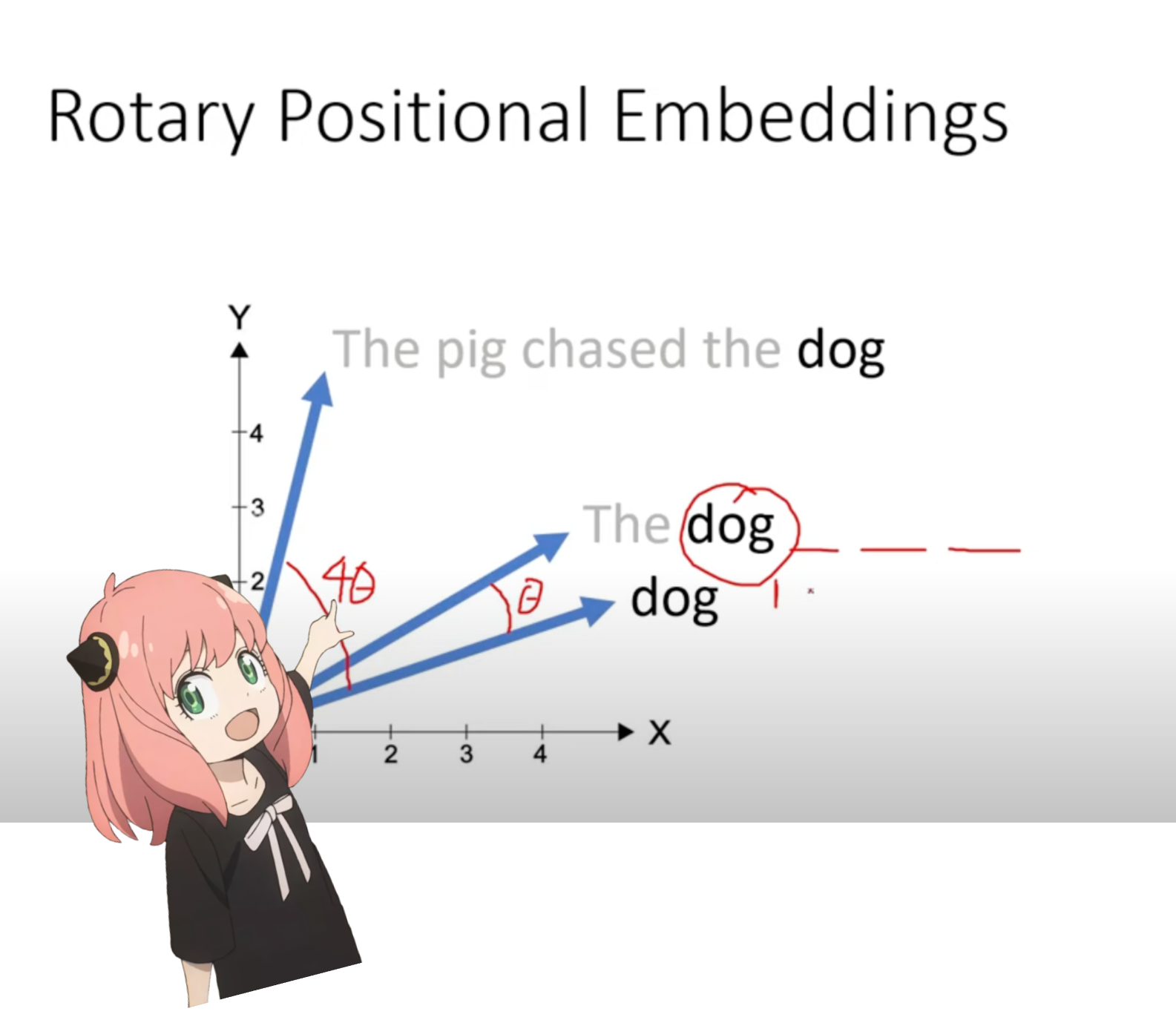
我们现在处于这样一个阶段:提示中的每个标记都有一个查询向量,但如果你仔细想想——单独的查询向量不知道提示中的位置。 查询:“生命、宇宙和一切的终极问题的答案是” 在我们的提示中我们已经使用了“the”三次,我们需要所有 3 个“the”标记的查询向量具有不同的查询向量(每个大小 [1x128])基于它们在查询中的位置。我们使用 RoPE(旋转位置嵌入)执行这些旋转。
RoPE
观看此视频(这就是我观看的)以理解数学。 https://www.youtube.com/watch?v=o29P0Kpobz0&t=530s
1 | |
在上面的步骤中,我们将查询向量分成对,我们对每对应用旋转角度偏移! 我们现在有一个大小为 [17x64x2] 的向量,这是针对提示中的每个标记将 128 个长度的查询分为 64 对!这 64 对中的每一对都将旋转 m*(theta),其中 m 是我们旋转查询的标记的位置!

使用复数的点积来旋转向量
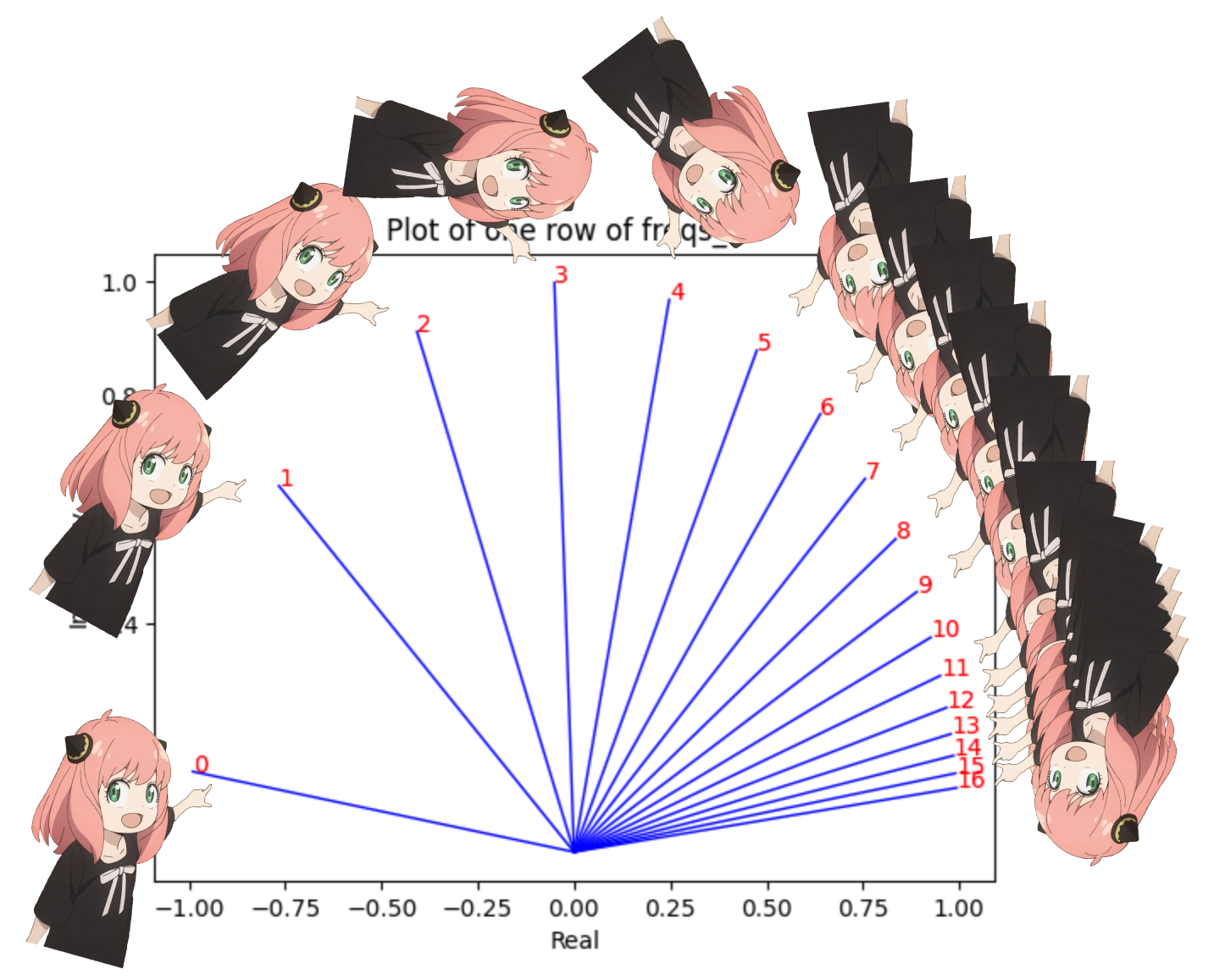
1 | |
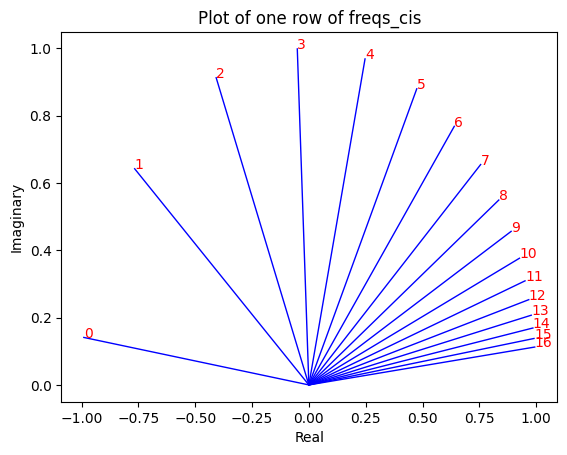
现在我们对每个标记(token)的查询元素都有一个复数(角度变化向量)
我们可以将查询(我们分成对的查询)转换为复数,然后进行点积以根据位置诚实旋转查询,这想想就很美好:)
1 | |
得到旋转向量后
我们可以通过再次将复数视为实数来返回成对的查询
1 | |
旋转的对现在被合并,我们现在有一个新的查询向量(旋转查询向量),其形状为 [17x128],其中 17 是标记的数量,128 是查询向量的暗度
1 | |
键(几乎与查询相同)
我太懒了,所以我不会对键进行数学计算,你需要记住的唯一事情是: > 键也生成维度 128 的键向量 > 键的权重数量只有 1/4查询,这是因为键的权重一次在 4 个头之间共享,为了减少需要的计算数量 > 键也会旋转以添加位置信息,就像查询一样,原因相同
1 | |
在此阶段,现在每个标记都有查询和键的旋转值。
现在每个查询和键的形状都是 [17x128]。
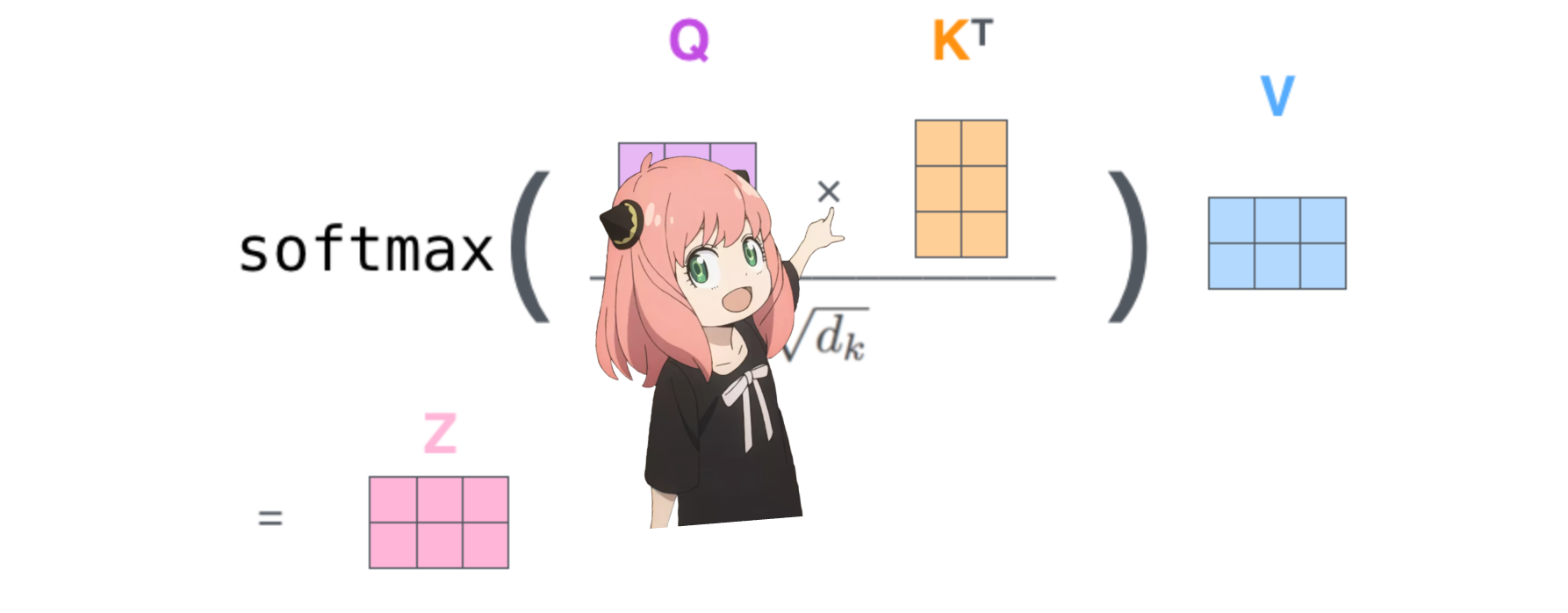
4.在下一步中,我们将乘以查询和关键矩阵
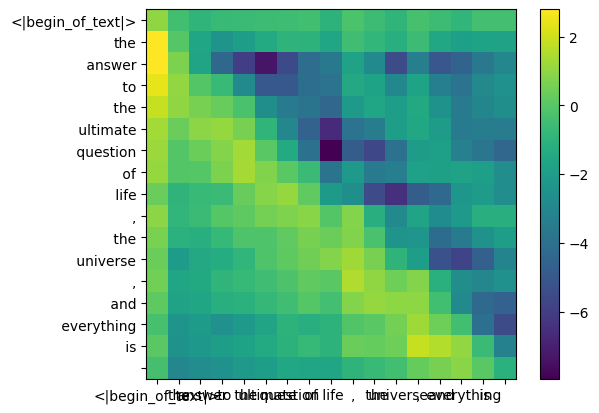
这样做将为我们提供一个将每个标记相互映射的分数,该分数描述了每个标记的查询与每个标记的密钥的相关程度。这是自我注意力 :) 注意力分数矩阵 (qk_per_token) 的形状是 [17x17],其中 17 是提示中的标记数量
1 | |
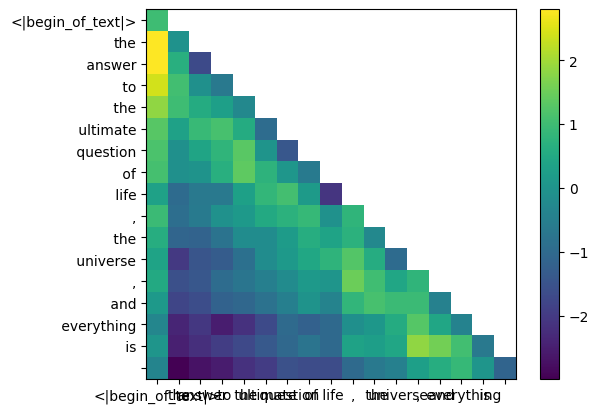
我们现在必须屏蔽查询关键分数
在 llama3 的训练过程中,未来的 token qk 分数被屏蔽。为什么?因为在训练期间我们只学习使用过去的标记来预测标记。 因此,在推理过程中,我们将未来的标记设置为零。
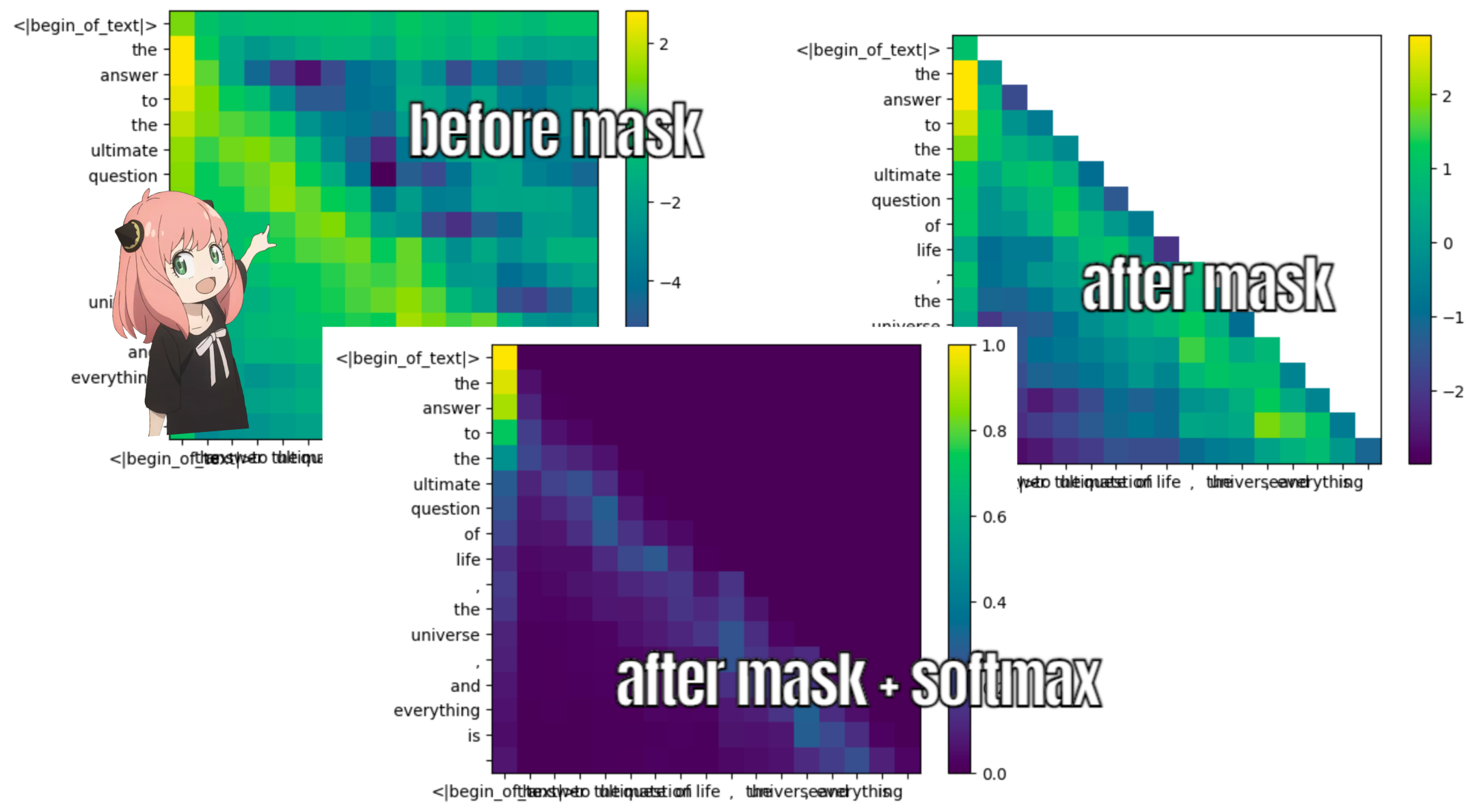
1 | |
1 | |
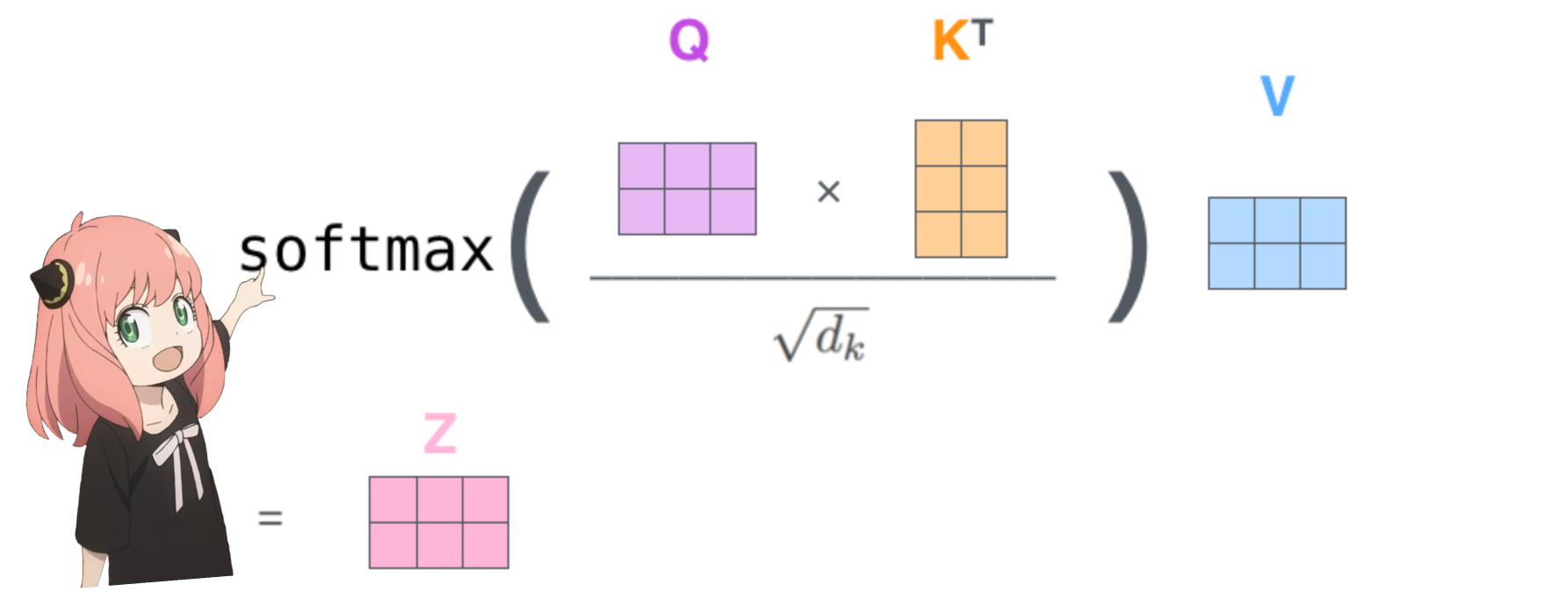
1 | |
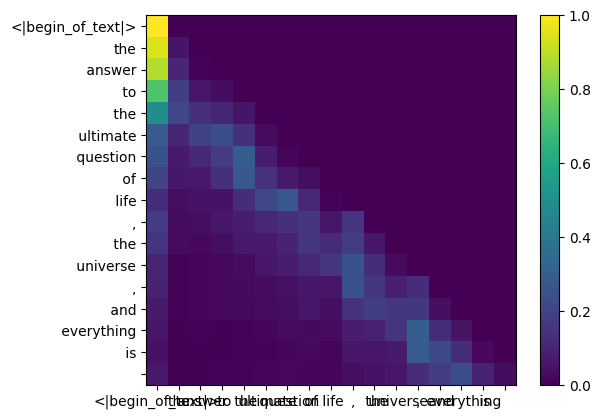
值(values)(注意力几乎结束)
这些分数(0-1)用于确定每个标记使用了多少值矩阵 >就像键一样,值权重也每4个注意力头共享(以节省计算) >因此,值的形状下面的权重矩阵是[8x128x4096]
1 | |
下面给出第一层第一头值权重矩阵
1 | |
值向量(value vectors)
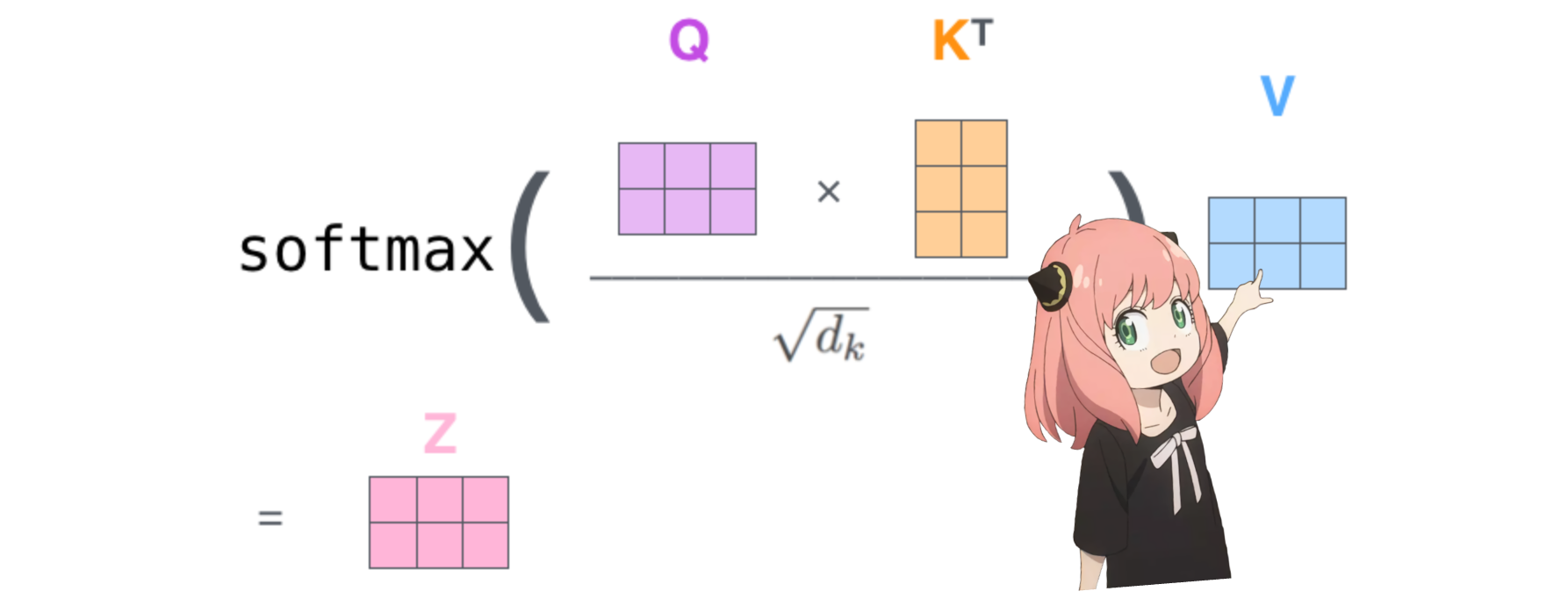
我们现在使用值权重来获取每个标记的注意力值,其大小为 [17x128],其中 17 是提示中标记的数量,128 是每个标记的值向量的暗度
1 | |
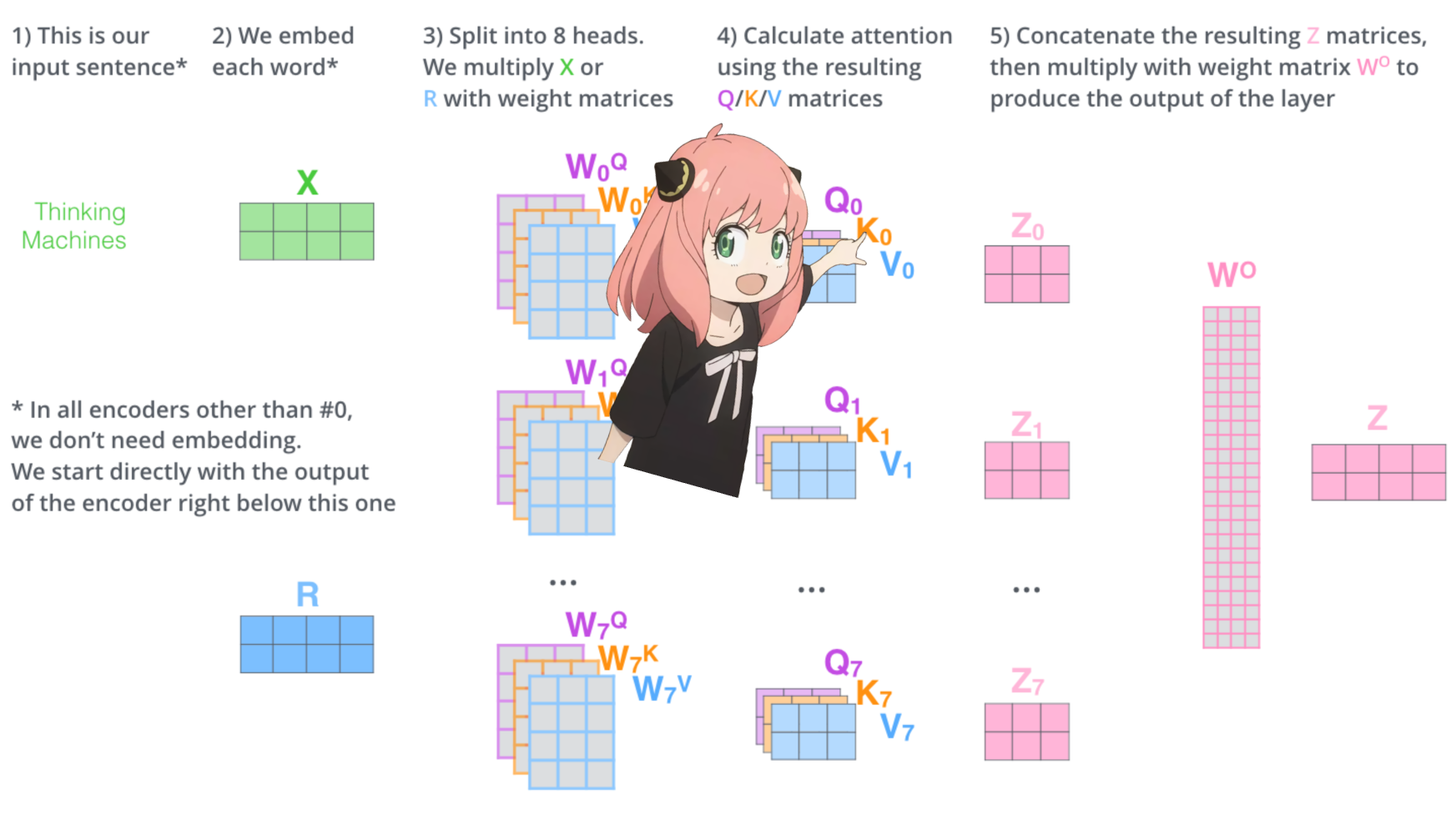
5.注意力
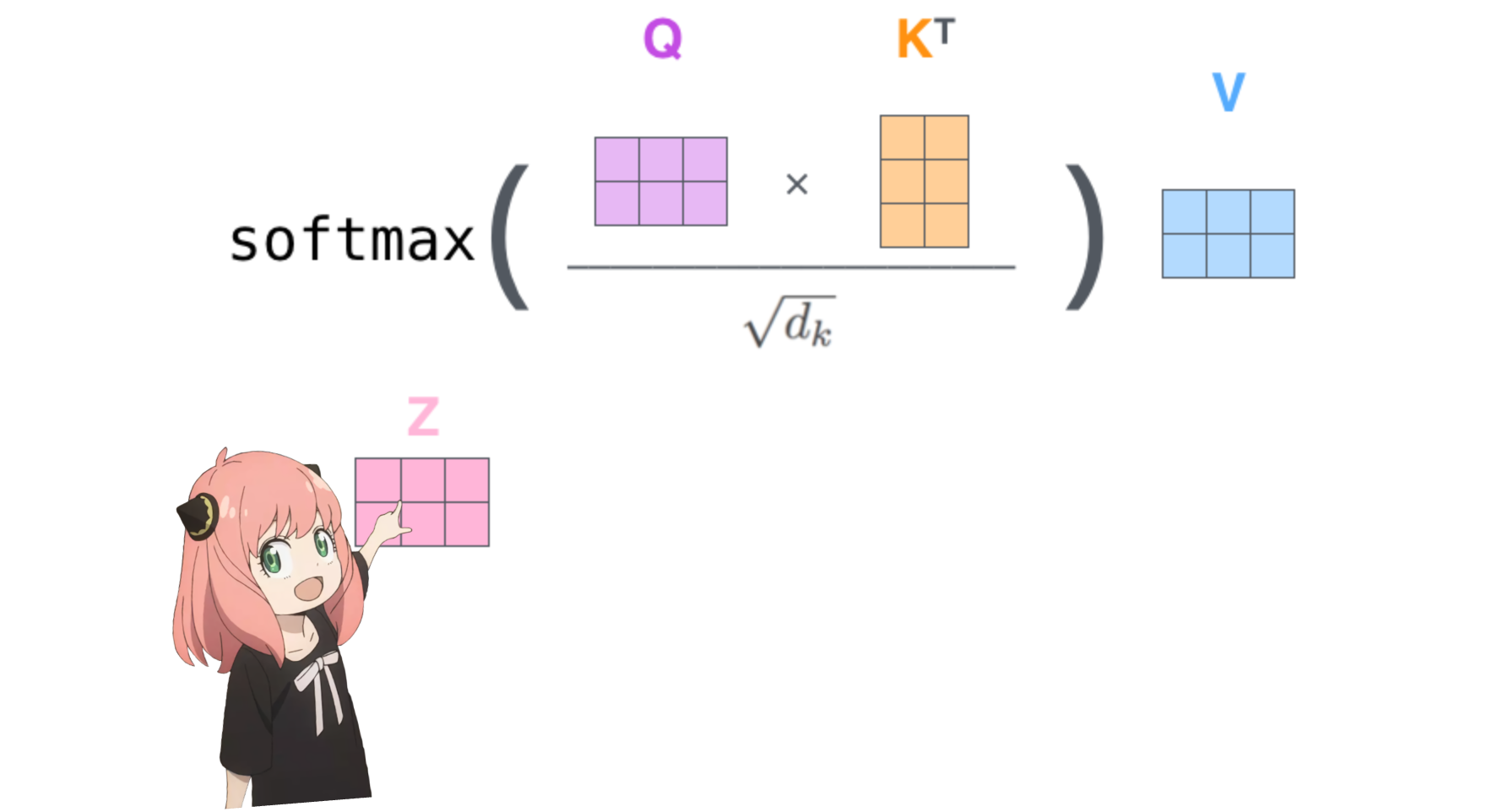
与每个标记的值相乘后得到的注意力向量的形状为 [17*128]
1 | |
多头注意力
我们现在有了第一层和第一个头的注意力值, 现在我将运行一个循环并执行与上面的单元完全相同的数学运算,但对于第一层中的每个头
1 | |
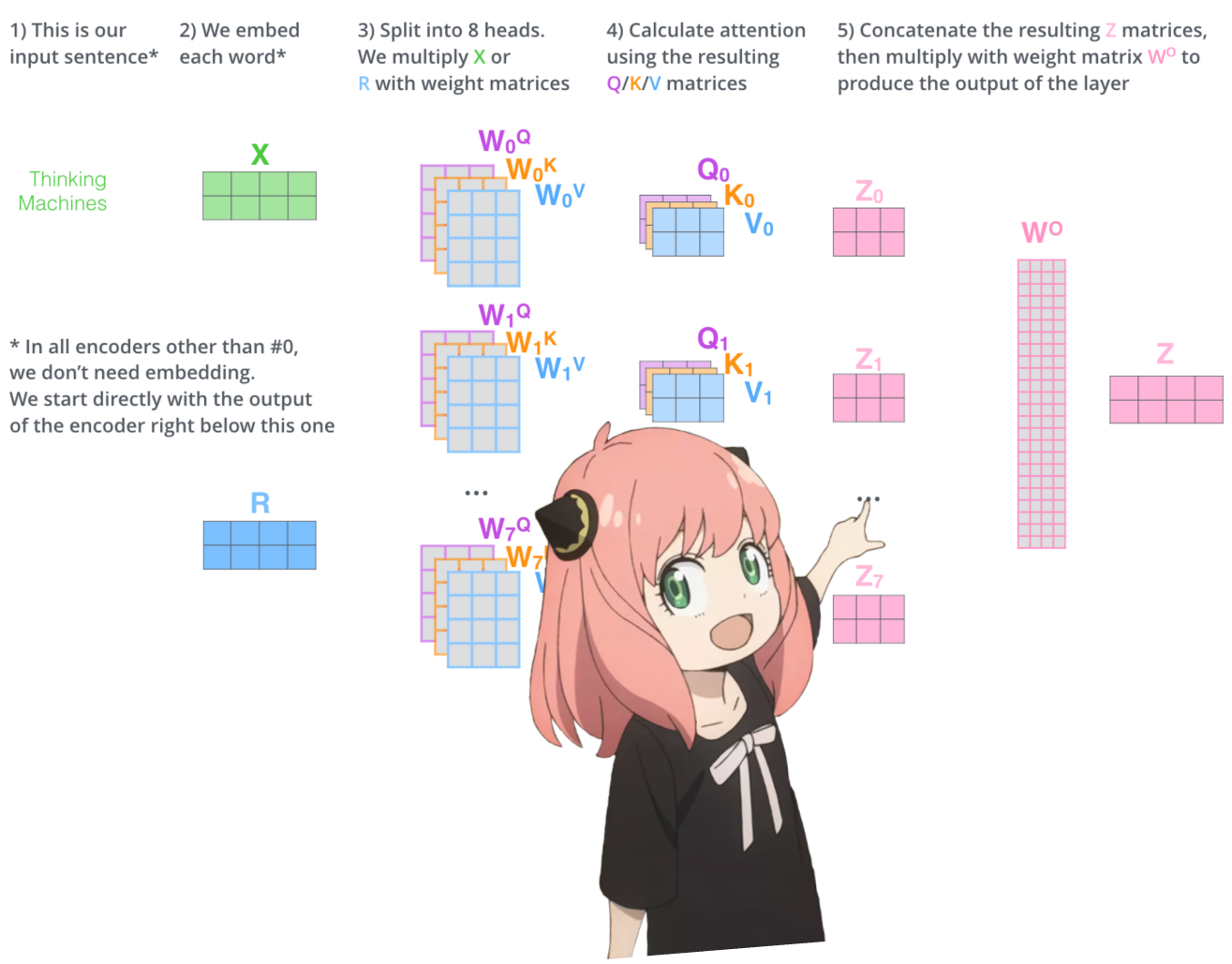
我们现在有了第一层所有 32 个头的 qkv_attention 矩阵,接下来我将把所有注意力分数合并到一个大小为 [17x4096] 的大矩阵中, 我们即将结束:)
1 | |
6.权重矩阵,最后步骤之一
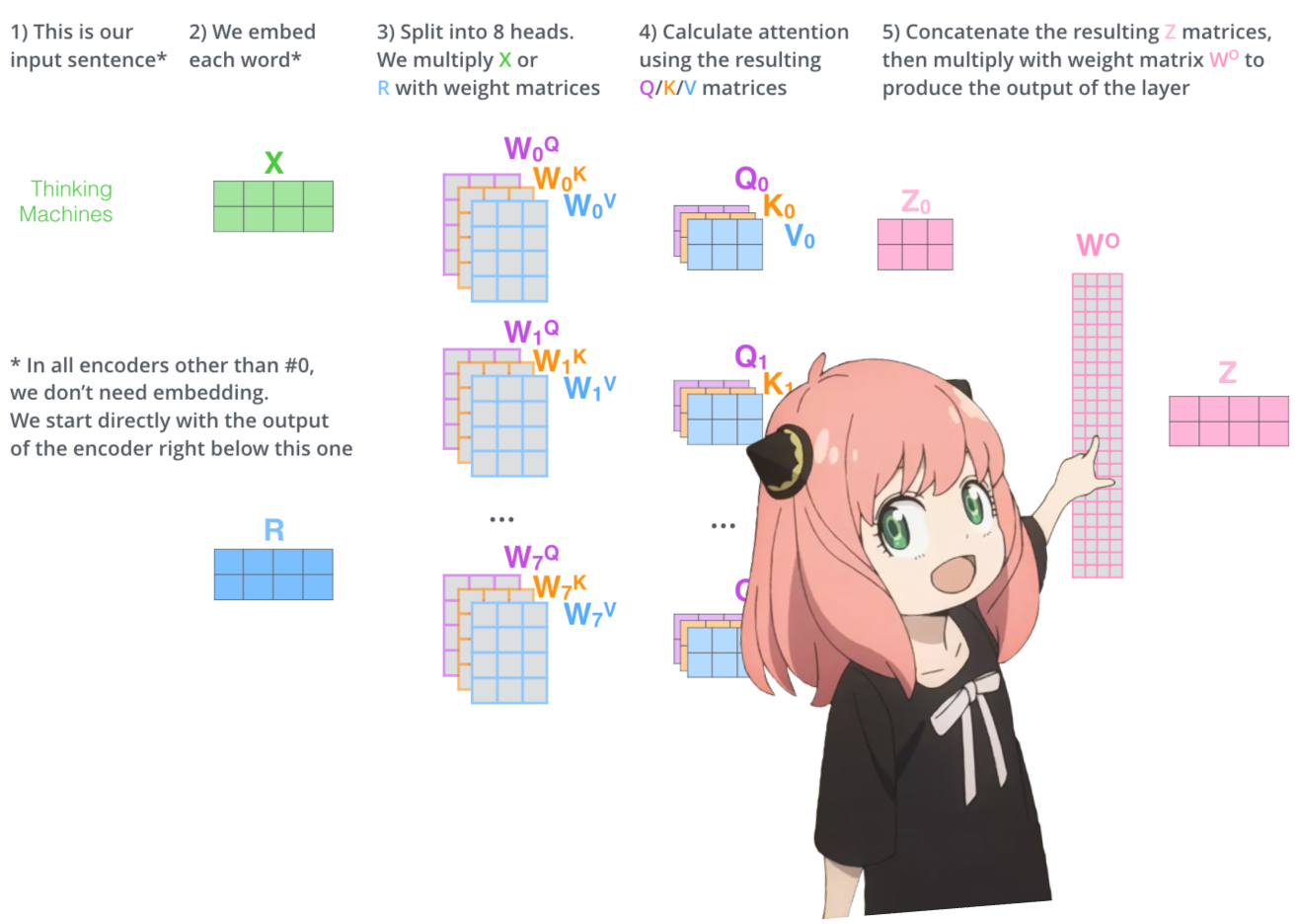
对于第 0 层注意力要做的最后一件事是乘以
1 | |
这是一个简单的线性层,所以我们只需 matmul
1 | |
我们现在在注意力之后嵌入值发生了变化,这应该添加到原始令牌嵌入中
1 | |
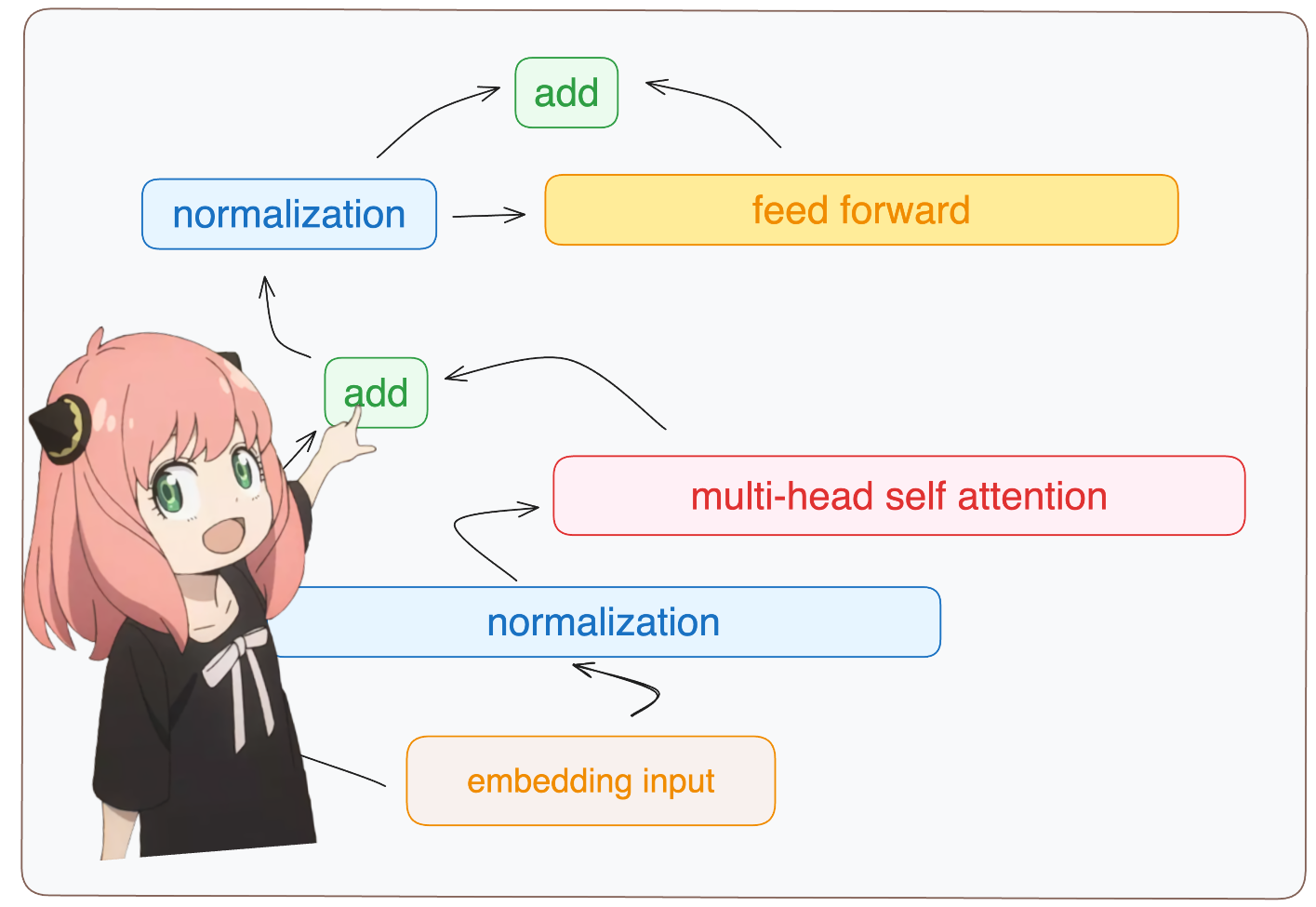
7.我们进行标准化,然后通过嵌入增量运行前馈神经网络
1 | |
加载 ff 权重并实现前馈网络

在 llama3 中,他们使用了 SwiGLU 前馈网络,这种网络架构非常擅长在模型需要时添加非线性。 如今在 llms 中使用这种前馈网络架构是相当标准的
1 | |
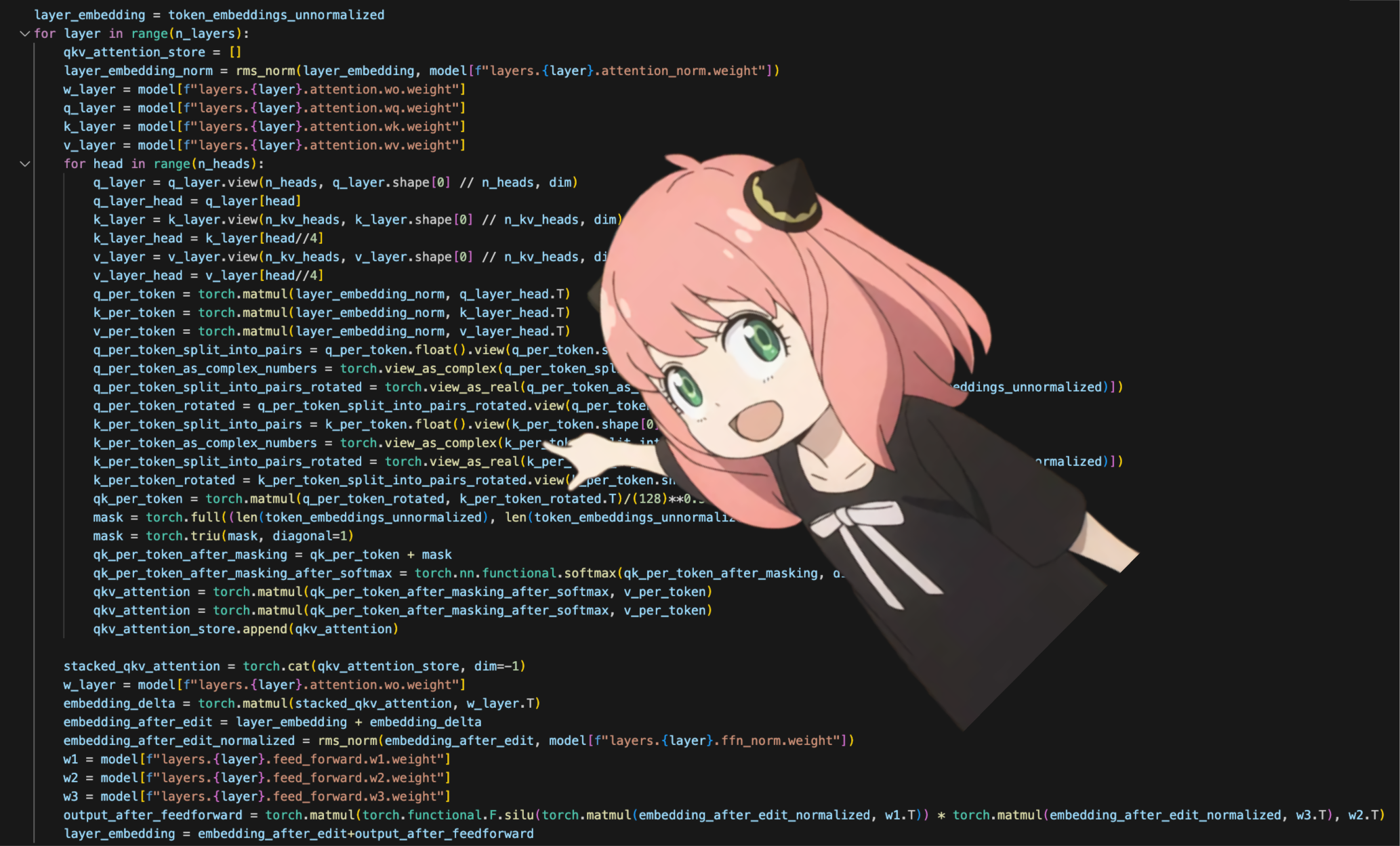
我们终于在第一层之后为每个令牌有了新编辑的嵌入
在我们完成之前还需要 31 层(一个 for 循环), 您可以想象这个编辑后的嵌入包含有关第一层上提出的所有查询的信息, 现在每一层都会对所提出的问题编码越来越复杂的查询,直到我们有一个嵌入知道我们需要的下一个令牌的所有信息。
1 | |
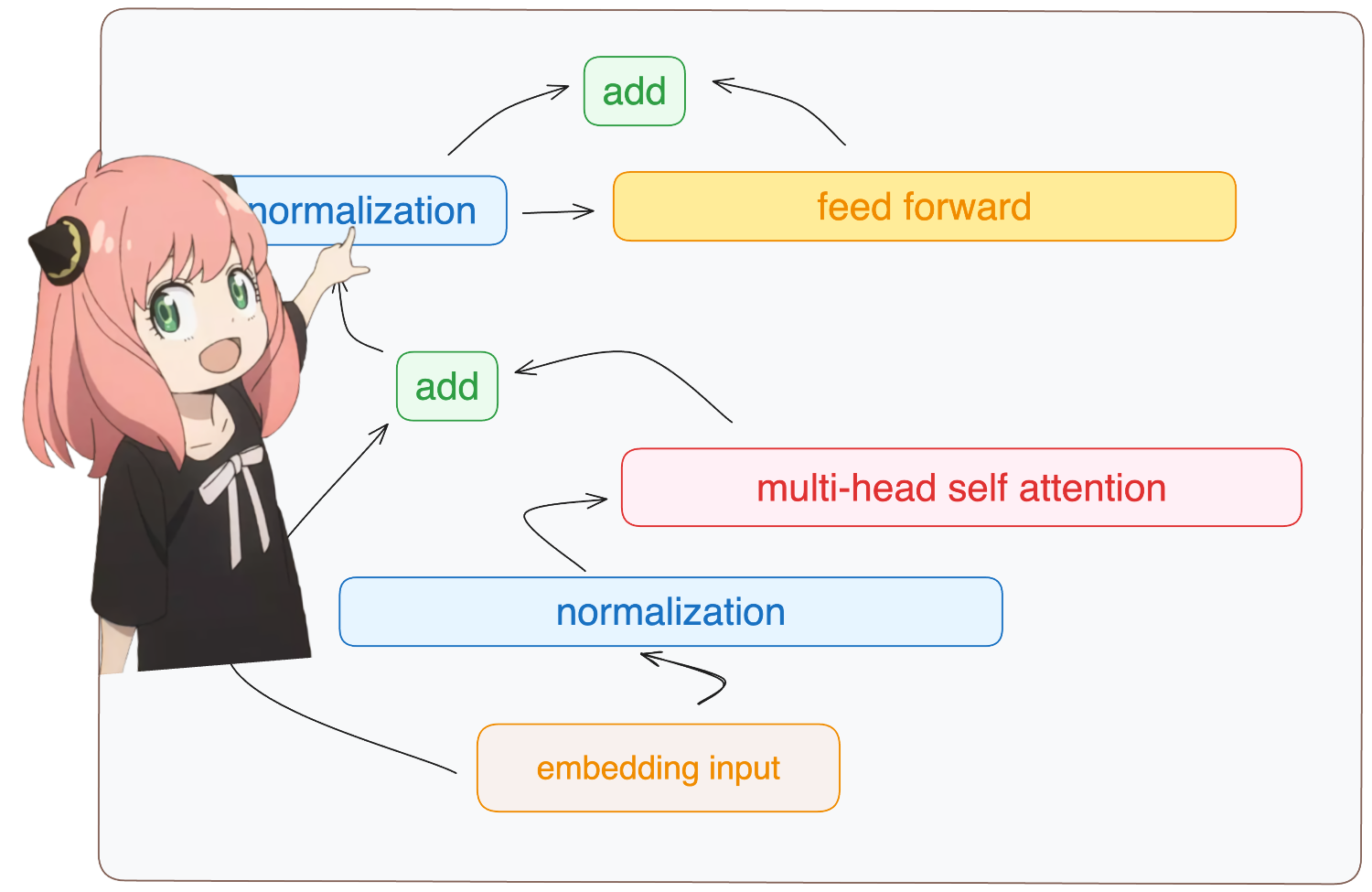
天哪,一切都同时发生
是的,就是这样。我们之前为每一层所做的一切都是一次性完成的。
祝阅读愉快:)
1 | |
8.我们现在有了最终的嵌入,模型可以对下一个标记做出的最佳猜测
嵌入的形状与常规令牌嵌入 [17x4096] 相同,其中 17 是令牌数量,4096 是嵌入暗淡
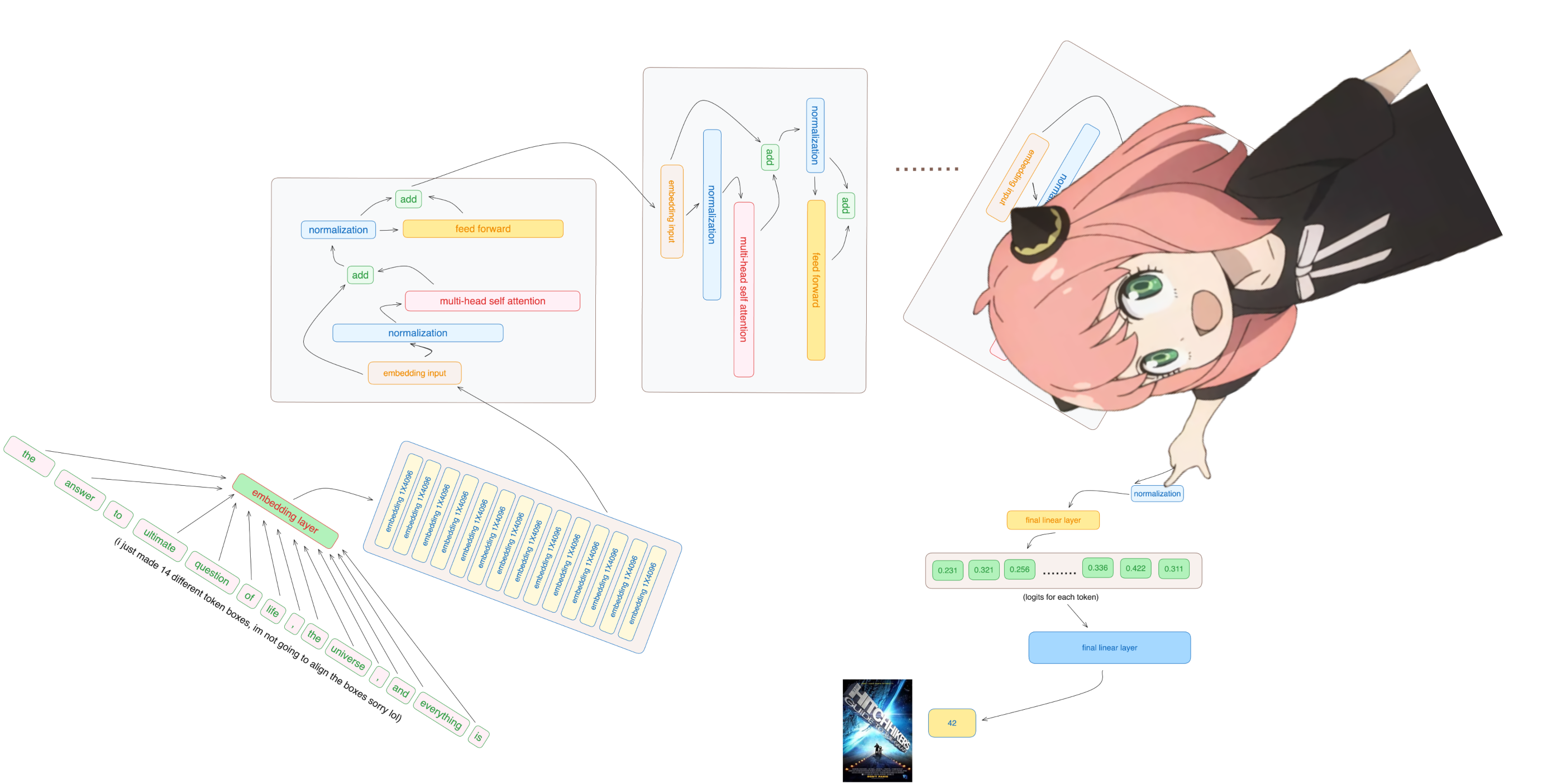
1 | |
最后,让我们将嵌入解码到令牌值中
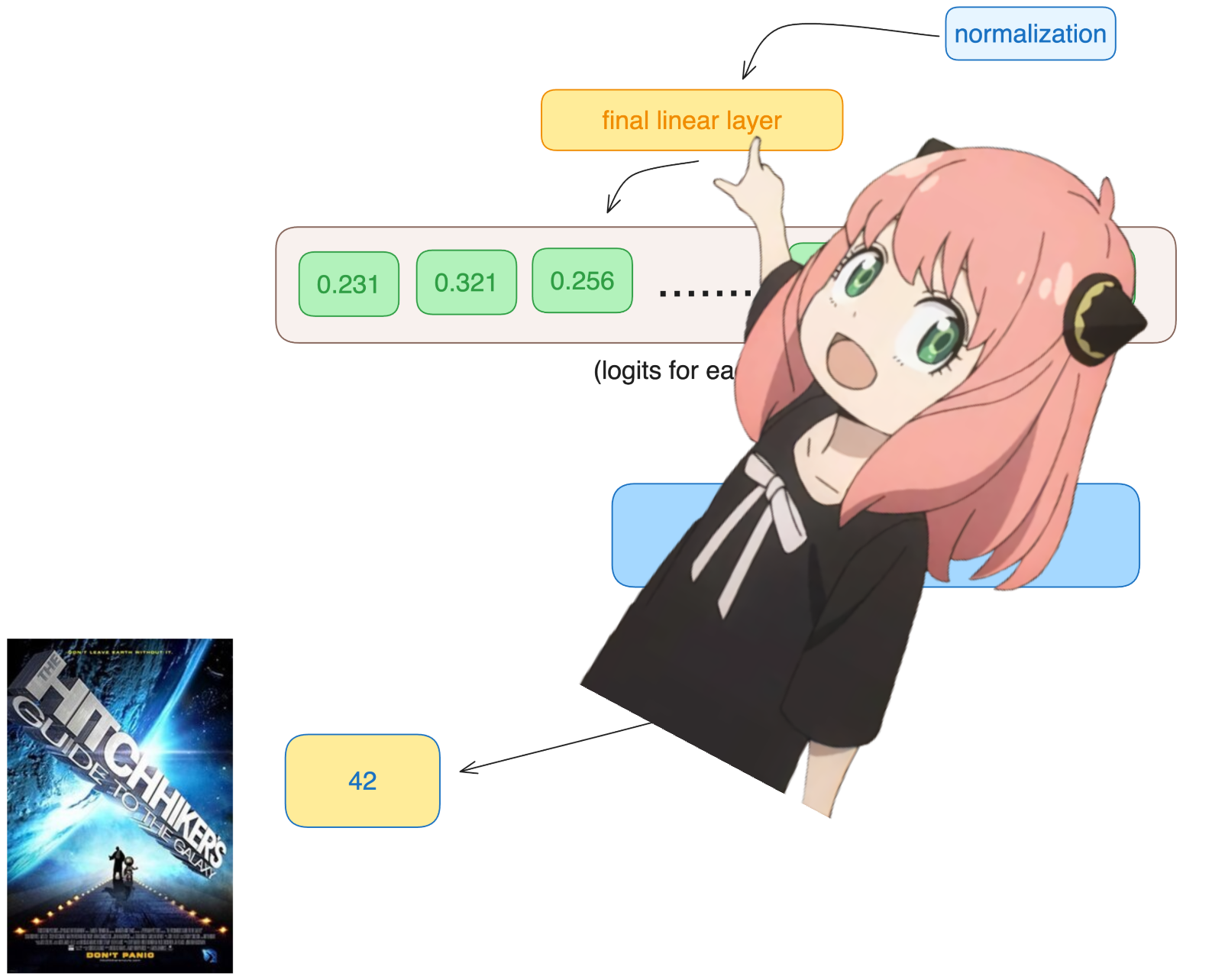
我们将使用输出解码器将最终的嵌入转换为令牌
1 | |
我们使用最后一个标记的嵌入来预测下一个值
希望在我们的例子中,42 :) 注意:42 是“生命、宇宙和一切的终极问题的答案”的答案,根据《银河系漫游指南》一书,大多数现代 llms 都会回答这里有 42,这应该验证我们的整个代码!祝我好运 :)
1 | |
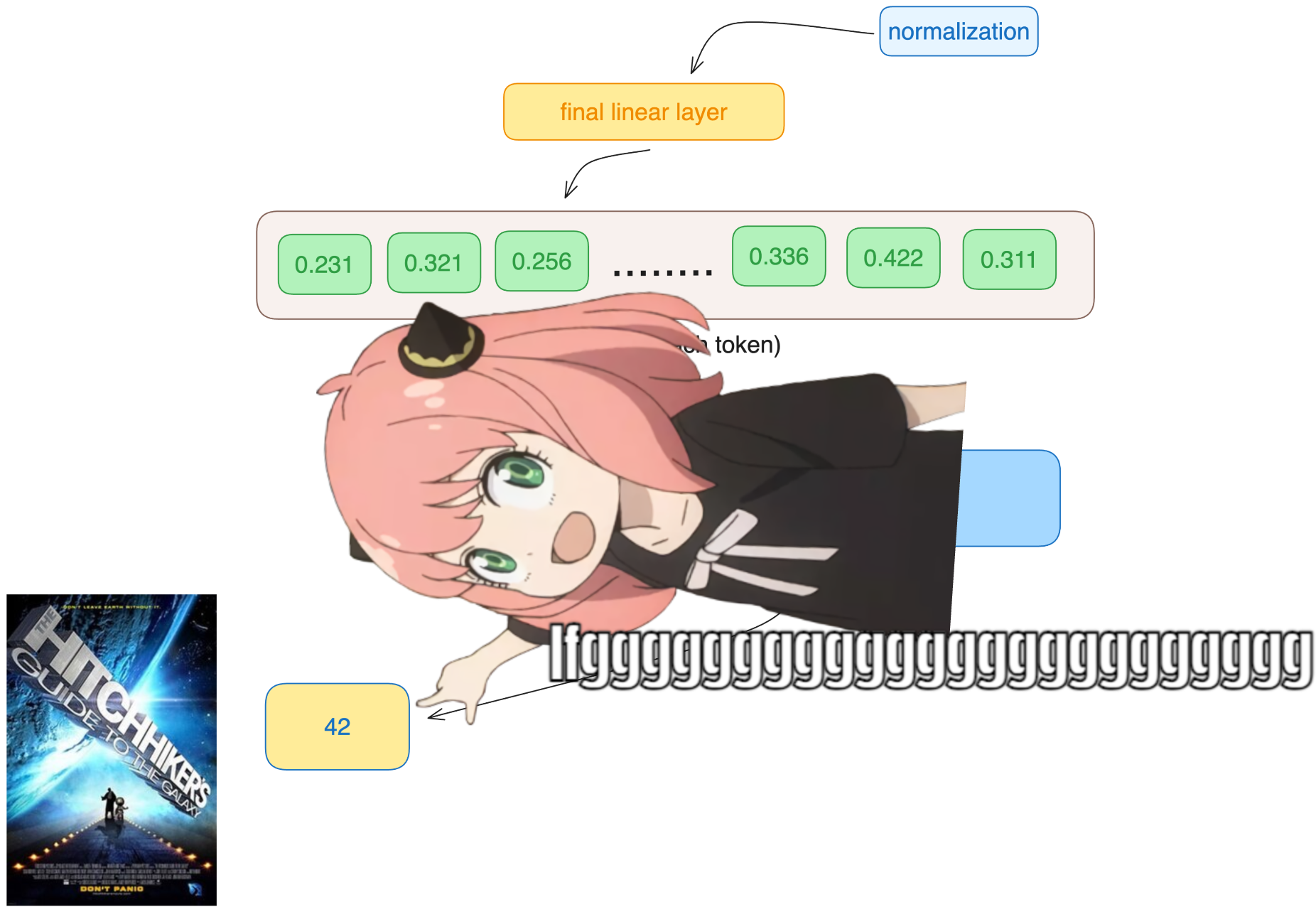
模型预测令牌编号 2983 作为下一个令牌,这是 42 的令牌编号吗?
我正在向您宣传,这是代码的最后一个单元格,希望您玩得开心:)
1 | |
Let's go
1 | |