高效微调统一框架——LLAMA-FACTORY技术点详解
高效的微调对于将大语言模型 (LLM) 适应下游任务至关重要。然而,在不同模型上实施这些方法需要付出不小的努力。 LLAMA-FACTORY是一个集成一套高效训练方法的统一框架。它允许用户通过内置的 Web UI LLAMA-BOARD 灵活地自定义 100 多个 LLM 的微调,无需编码。 (本文旨在说明LLAMA-FACTORY引入了NLP领域的哪些训练微调技术及其优势应用领域,项目部署与应用参考官方网址:https://github.com/hiyouga/LLaMA-Factory)
一. LLAMA-FACTORY简介
LLAMA-FACTORY是一个使 LLM 微调任务实现低代码规范化的框架。它通过可扩展的模块统一了各种高效的微调方法,从而能够以最少的资源和高吞吐量对数百种 LLM 进行微调。此外,它还简化了常用的训练方法,包括生成式预训练(Radford,2018)、监督微调 (SFT)(Wei,2022)、人类反馈中强化学习 (RLHF)(Ouyang,2022)和直接偏好优化 (DPO)(Rafailov,2023)。用户可以利用命令行或 Web 界面以最少或无需编码工作量来定制和微调LLM。
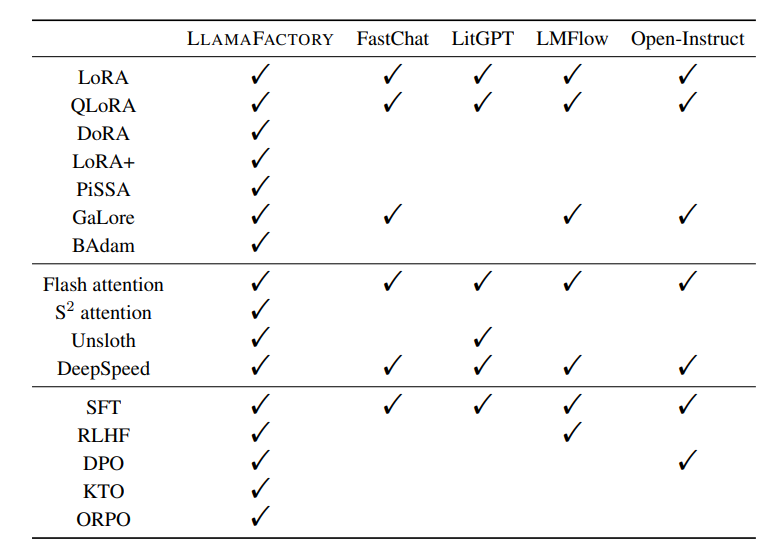
下表是其和现存LLM调优工具的特征比较:
LLAMA-FACTORY 由三个主要模块组成:模型加载器、数据工作器和训练器。尽量减少这些模块对特定模型和数据集的依赖,使框架能够灵活地扩展到数百个模型和数据集。具体来说,首先建立一个模型注册表,模型加载器可以通过识别精确的层将适配器精确地连接到预训练模型。然后,开发一个数据描述规范,允许数据工作器通过对齐相应的列来收集数据集。此外,提供高效微调方法的即插即用实现,使训练器能够通过替换默认方法激活。允许这些模块在不同的训练方法中重复使用,从而显著降低新方法的集成成本。
下表是支持的LLM清单:
| 模型名 | 模型大小 | Template |
|---|---|---|
| Baichuan 2 | 7B/13B | baichuan2 |
| BLOOM/BLOOMZ | 560M/1.1B/1.7B/3B/7.1B/176B | - |
| ChatGLM3 | 6B | chatglm3 |
| Command R | 35B/104B | cohere |
| DeepSeek (Code/MoE) | 7B/16B/67B/236B | deepseek |
| Falcon | 7B/11B/40B/180B | falcon |
| Gemma/Gemma 2/CodeGemma | 2B/7B/9B/27B | gemma |
| GLM-4 | 9B | glm4 |
| InternLM2/InternLM2.5 | 7B/20B | intern2 |
| Llama | 7B/13B/33B/65B | - |
| Llama 2 | 7B/13B/70B | llama2 |
| Llama 3/Llama 3.1 | 8B/70B | llama3 |
| LLaVA-1.5 | 7B/13B | vicuna |
| MiniCPM | 1B/2B | cpm |
| Mistral/Mixtral | 7B/8x7B/8x22B | mistral |
| OLMo | 1B/7B | - |
| PaliGemma | 3B | gemma |
| Phi-1.5/Phi-2 | 1.3B/2.7B | - |
| Phi-3 | 4B/7B/14B | phi |
| Qwen/Qwen1.5/Qwen2 (Code/Math/MoE) | 0.5B/1.5B/4B/7B/14B/32B/72B/110B | qwen |
| StarCoder 2 | 3B/7B/15B | - |
| XVERSE | 7B/13B/65B | xverse |
| Yi/Yi-1.5 | 6B/9B/34B | yi |
| Yi-VL | 6B/34B | yi_vl |
| Yuan 2 | 2B/51B/102B | yuan |
LLAMA-FACTORY 是用 PyTorch(Paszke,2019)实现的,并且从开源库中获益良多,例如 Transformers(Wolf,2020)、PEFT(Mangrulkar,2022)和 TRL(von Werra,2020)。在此基础上,提供一个具有更高抽象级的开箱即用框架。此外,用 Gradio(Abid,2019)构建 LLAM-ABOARD,无需编码即可微调 LLM。
高效的 LLM 微调技术可分为两大类:专注于优化和面向计算。高效优化技术的主要目标是调整 LLM 参数,同时将成本保持在最低水平。另一方面,高效的计算方法则力求减少 LLM 中所需计算的时间或空间。LLAMA-FACTORY 中特色功能如下。
- 多种模型:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等等。
- 集成方法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO 训练、KTO 训练、ORPO 训练等等。
- 多种精度:16 比特全参数微调、冻结微调、LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ 的 2/3/4/5/6/8 比特 QLoRA 微调。
- 先进算法:GaLore、BAdam、Adam-mini、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ、PiSSA 和 Agent 微调。
- 实用技巧:FlashAttention-2、Unsloth、RoPE scaling、NEFTune 和 rsLoRA。
- 实验监控:LlamaBoard、TensorBoard、Wandb、MLflow 等等。
- 极速推理:基于 vLLM 的 OpenAI 风格 API、浏览器界面和命令行接口。
二. 特色功能介绍
LLAMA-FACTORY 可以覆盖LLM的预训练和RLHF(人类反馈强化)的完整阶段,以下是详细说明:
2.1 训练方法集成
1. (增量)预训练 (Pre-training)
- 预训练: 预训练是指在大规模文本数据上训练一个语言模型,使其学习通用的语言表示。预训练模型能够捕捉语言的语法、语义和上下文信息,为下游任务提供良好的初始化参数。
- 增量预训练: 指在已有的预训练模型基础上,使用新的数据或任务继续训练,以增强模型的性能或使其适应新的领域。增量预训练可以避免从头训练,节省时间和资源。
2. (多模态)指令监督微调 (Instruction-tuned Fine-tuning)
- 指令监督微调: 指使用指令-答案对数据对预训练模型进行微调,使其能够遵循指令完成各种任务。指令通常描述了任务目标和输入格式,答案则是期望的输出。
- 多模态指令监督微调: 将指令监督微调扩展到多模态领域,例如图像-文本对或视频-文本对,使模型能够理解和处理多模态信息。
3. 奖励模型训练 (Reward Model Training)
奖励模型用于评估模型生成的文本质量。在强化学习中,奖励模型为模型提供反馈信号,指导模型学习生成更优质的文本。奖励模型通常通过人工标注数据或根据特定指标进行训练。
4. PPO 训练 (Proximal Policy Optimization)
PPO 是一种强化学习算法,用于训练 agent (例如语言模型) 在与环境交互的过程中学习最佳策略。PPO 算法通过迭代更新策略网络的参数,以最大化累积奖励。
5. DPO 训练 (Direct Preference Optimization)
DPO 是一种基于偏好的强化学习算法,它直接从人类偏好数据中学习奖励函数,并使用该奖励函数来优化策略。DPO 避免了手动设计奖励函数的困难,能够更好地捕捉人类的偏好。
6. KTO 训练 (Knowledge-aware Training)
KTO 训练是指将知识图谱等外部知识融入到模型训练中,以增强模型的知识理解和推理能力。KTO 训练可以帮助模型更好地理解文本中的实体、关系和概念,从而提高模型的性能。
7. ORPO 训练 (Off-Policy Reward Policy Optimization)
ORPO 是一种离线强化学习算法,它利用预先收集的数据来训练策略,而不需要与环境进行实时交互。ORPO 算法可以有效地利用历史数据,并能够在离线环境中进行策略优化
2.2 LLM微调方法集成
LLAMA-FACTORY 支持六种先进微调方案和六种模型训练加速方案

1.冻结调整方法 (Frozen Fine-tuning, Houlsby, 2019)**
- 核心思想: 只微调模型的一小部分参数,通常是解码器最后几层,而其余参数保持冻结。
- 优点: 简单易实现,计算成本和存储成本低。
- 缺点: 限制了模型的表达能力,可能导致性能不如全参数微调。
2. 梯度低秩投影 (Gradient Low-Rank Projection, GaLoRA, Zhao, 2024)
- 核心思想: 将梯度投影到低维空间,从而降低梯度更新的维度,节省内存。
- 优点: 允许全参数学习,同时降低内存占用。
- 缺点: 相比LoRA等方法,实现较为复杂。
3. 低秩自适应 (Low-Rank Adaptation, LoRA, Hu, 2022)
- 核心思想: 冻结所有预训练权重,并在特定层引入一对可训练的低秩矩阵。这些矩阵捕获微调过程中的关键更新信息。
- 优点: 在保持性能的同时,显著降低内存占用和计算成本。
- 缺点: 对于某些任务,可能需要仔细调整低秩矩阵的秩。
4. 量化低秩自适应 (Quantized Low-Rank Adaptation, QLoRA, Dettmers, 2023)
- 核心思想: 将 LoRA 与量化技术结合,进一步压缩模型大小,降低内存需求。
- 优点: 在 LoRA 的基础上进一步降低内存占用,使得在更小的设备上进行微调成为可能。
- 缺点: 量化可能会导致一定的性能损失。
5. 权重分解低秩自适应 (Weight Decomposed Low-Rank Adaptation, DoRA, Liu et al., 2024)
- 核心思想: 将预训练权重分解为绝对值和方向分量,只将 LoRA 应用于方向分量。
- 优点: 相比 LoRA,可以更有效地捕捉权重更新的方向,提升微调效果。
- 缺点: 实现比 LoRA 稍复杂。
6. LoRA+ (Hayou et al., 2024)
- 核心思想: 针对 LoRA 的一些不足进行改进,例如对不同层使用不同的低秩矩阵秩。
- 优点: 在 LoRA 的基础上进一步提升性能,并提供更灵活的配置选项。
- 缺点: 相对 LoRA 更复杂,需要更多的调参经验。
2.3 高效训练技术
在 LLAMA-FACTORY 中,集成了一系列高效的计算技术。常用的技术包括混合精度训练(Micikevicius,2018)和激活检查点(Chen,2016)。从检查注意层的输入输出 (IO) 开销中汲取见解,flash attention(Dao,2022 年)引入一种硬件友好的方法来增强注意计算。S^2 attention(Chen,2024b)解决了在块稀疏注意中扩展上下文的挑战,从而减少了微调长上下文 LLM 中的内存使用量。
混合精度训练 (Mixed Precision Training) (Micikevicius, 2018)
- 核心思想: 在训练过程中混合使用 FP32 (单精度浮点数) 和 FP16 (半精度浮点数)。
- 优势:
- 加速训练: FP16 计算速度比 FP32 快,减少训练时间。
- 降低内存占用: FP16 占用内存更少,允许训练更大模型或使用更大批次。
- 关键技术: 损失缩放 (loss scaling) 防止梯度下溢 (underflow)。
- 应用: 广泛应用于各种深度学习模型训练,尤其在 GPU 上训练大型 NLP 模型时效果显著。
2. 激活检查点 (Activation Checkpointing) (Chen, 2016)
- 核心思想: 只保存部分激活值,并在反向传播时重新计算未保存的激活值。
- 优势:
- 大幅降低内存占用: 避免存储所有中间激活值,特别有利于训练深度网络。
- 劣势:
- 增加计算开销: 需要重新计算部分激活值,延长训练时间。
- 应用: 适用于内存受限的情况下训练大型模型,例如训练长序列的 NLP 模型。
3. Flash Attention 2
- 核心思想: 对注意力机制的计算进行优化,使其更加硬件友好,特别针对 GPU。
- 优势:
- 加速训练和推理: 通过优化内存访问模式和减少冗余计算,提高计算效率。
- 降低内存占用: 更高效地利用内存,允许处理更长的序列。
- 应用: 广泛应用于 Transformer 模型,显著提升其性能,特别是在长序列任务上。
4. S^2 Attention (Chen, 2024b)
- 核心思想: 一种针对块稀疏注意力的方法,旨在解决扩展上下文长度时内存使用过大的问题。
- 优势:
- 降低内存占用: 允许在微调长上下文 LLM 时使用更长的序列,而不会导致内存溢出。
- 应用: 主要用于微调大型语言模型 (LLM),使其能够处理更长的上下文信息,例如长文档或对话历史。
5. Unsloth
- 核心思想: 一种用于优化 Transformer 模型训练的库,主要针对长序列任务。
- 优势:
- 加速训练: 通过一系列优化技术,例如 Flash Attention 和 S^2 Attention,提高训练速度。
- 降低内存占用: 允许训练更长序列的模型,或使用更大的批次。
- 应用: 主要用于训练长序列 Transformer 模型,例如用于代码生成或长文本摘要的模型。
三. 项目框架
LLAMA-FACTORY 有效地将这些技术组合成一个凝聚的结构,大大提高 LLM 微调的效率。这使得内存占用从混合精度训练期间的18 字节/参数(Micikevicius,2018)或 Bfloat16 训练期间的 8 字节/参数(Le Scao,2022)减少到 0.6 字节/参数。
在LLAMA-FACTORY 中, 模型加载器准备了各种用于微调的架构,支持 100 多个 LLM。数据工作器通过精心设计的流水线处理来自不同任务的数据,支持 50 多个数据集。训练器统一了有效的微调方法,使这些模型适应不同的任务和数据集,提供四种训练方法。LLAMA-BOARD 为上述模块提供了友好的可视化界面,使用户能够以无代码的方式配置和启动单个 LLM 微调过程,并实时监控训练状态。如图说明 LLAMA-FACTORY 的整体架构。
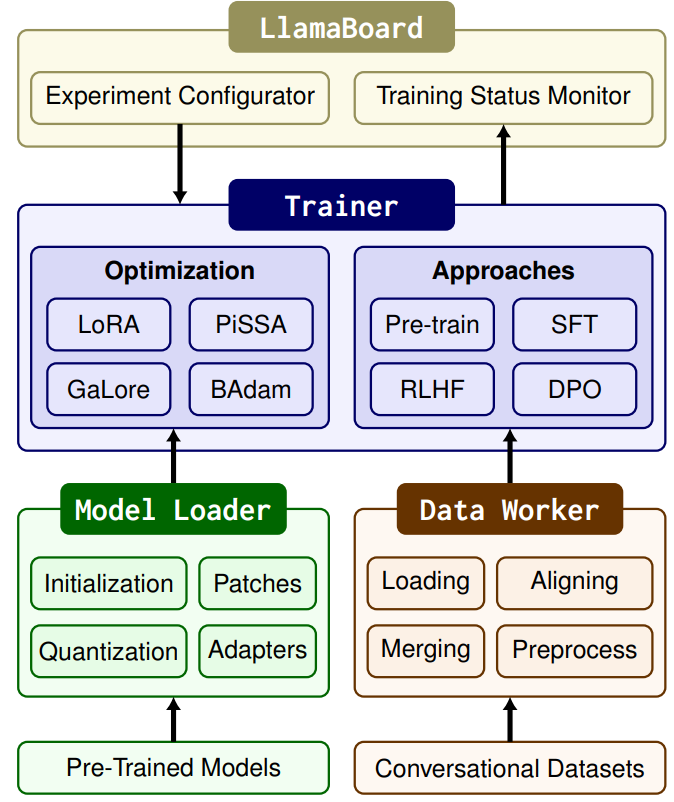
3.1 模型加载器有四个组件:模型初始化、模型补丁、模型量化和适配器连接。
模型初始化。用 HF Transformers 的 AutoModel API(Wolf,2020)来加载模型和初始化参数。为了使框架与不同的模型架构兼容,建立了一个模型注册表来存储每个层的类型,从而更直接地促进高效微调技术的使用。如果token化器的词汇表大小超出了嵌入层的容量,会调整层的大小并使用噪声均值初始化来初始化新参数。为了确定 RoPE 的缩放因子(Chen,2023),将其取做最大输入序列长度与模型的上下文长度之比。
模型补丁。为了启用 flash attention 和 S^2 attention,用 monkey patch 来代替模型的前向计算。不过,由于自 HF Transformers 4.34.0 以来就支持 flash attention,用 API 来启用 flash attention。为了防止动态模块过度分区,在 DeepSpeed ZeRO-3 (Rasley et al., 2020) 优化时将混合专家 (MoE) 块设置为叶(Leaf)模块。
模型量化。可以通过 bits-and-bytes 库 (Dettmers, 2021) 用 LLM.int8 (Dettmers et al., 2022a) 将模型动态量化为 8 位或 4 位。对于 4 位量化,用双量化和 4 位普通浮点作为 QLoRA (Dettmers et al., 2023)。还支持训练后量化 (PTQ) 方法量化的模型微调,包括 GPTQ (Frantar,2023)、AWQ (Lin,2023) 和 AQLM (Egiazarian,2024)。请注意,无法直接微调量化权重;因此,量化模型仅与基于适配器的方法兼容。
适配器附加。用模型注册表自动识别适当的层来附加适配器。适配器默认附加到一个层的子集以节省内存,但将它们附加到所有线性层可能会产生更好的性能 (Dettmers,2023)。 PEFT (Mangrulkar et al., 2022) 库提供了一种非常方便的方式来连接适配器,例如 LoRA (Hu et al., 2022)、rsLoRA (Kalajdzievski, 2023) 和 DoRA (Liu et al., 2024)。替换后向计算为Unsloth (Han & Han, 2023) 的版本加速 LoRA。为了执行人类反馈中强化学习 (RLHF) ,在模型上添加了一个V头,这是一个将每个 token 的表示映射到标量的线性层。
精度适应。根据设备的功能处理预训练模型的浮点精度。对于 NVIDIA GPU,如果计算能力为 8.0 或更高,使用 bfloat16 精度。否则,采用 float16。对 Ascend NPU 和 AMD GPU 使用 float16,对非 CUDA 设备使用 float32。请注意,用 float16 精度加载 bfloat16 模型可能会导致溢出问题。在混合精度训练中,将所有可训练参数设置为 float32。尽管如此,在 bfloat16 训练中将可训练参数保留为 bfloat16。
fp16:
- 常用于 GPU(例如 NVIDIA 的 Tensor Cores)中,以加速深度学习模型的训练。
- 在部分硬件中,
fp16运算速度比fp32更快,且内存消耗较少。- 由于尾数部分较长,
fp16能在一些需要较高精度的运算中发挥优势。
bf16:
bf16主要由 Google 推广,特别适用于 TPU(Tensor Processing Unit)。- 因为指数位数较多,
bf16在处理较大数值范围时表现优异,同时避免了过度的数值溢出。- 尽管
bf16的精度比fp16低,但在深度学习训练中,bf16被认为在保持足够数值范围的同时具有足够的精度,因此非常适合神经网络的训练。
3.2 一个数据处理流水线
包括数据集加载、数据集对齐、数据集合并和数据集预处理。它将不同任务的数据集标准化为统一的格式,能够在各种格式的数据集上微调模型。
数据集加载。用数据集(Lhoest,2021)库来加载数据,这使用户可以从 Hugging Face Hub 加载远程数据集或通过脚本或文件读取本地数据集。数据集库显着减少数据处理过程中的内存开销,并加速了用 Arrow(Apache,2016)的样本查询。默认情况下,整个数据集会下载到本地磁盘。但是,如果数据集太大而无法存储,框架提供数据集流动对其进行迭代,而无需下载。
数据集对齐。为了统一数据集格式,设计了一个数据描述规范来表征数据集的结构。例如,羊驼数据集有三列:指令、输入和输出(Taori,2023)。根据数据描述规范将数据集转换为与各种任务兼容的标准结构。下表显示了一些数据集结构示例。

数据集合并。统一的数据集结构为合并多个数据集提供了一种有效的方法。对于非流动模式下的数据集,只需在训练期间数据集混洗之前先连接起来。然而,在流动模式下,简单地连接数据集会阻碍数据混洗。因此,提供交替读取不同数据集数据的方法。
数据集预处理。LLAMA-FACTORY 专为微调文本生成模型而设计,主要用于聊天完成。聊天模板是这些模型中的关键组成部分,因为它与这些模型的指令遵循能力高度相关。因此,提供数十种聊天模板,可以根据模型类型自动选择。用token化器在应用聊天模板后对句子进行编码。默认情况下,仅计算完成的损失,而忽略提示(Taori,2023)。或者,利用序列打包(Krell,2021)来减少训练时间,这在执行生成式预训练时会自动启用。
设计了一个 Formatter 类,以便将文本输入稳健地转换为其嵌入 ID。具体来说,提供 EmptyFormatter、StringFormatter、FunctionFormatter 和 ToolFormatter。此外,LLAMA-FACTORY 支持微调模型以获得函数调用能力。虽然 ReAct 提示(Yao,2023)是工具使用的流行选择,但它对于嵌套工具参数来说是不够的。优化的工具调用提示如表所示。

高效训练微调。将最先进的高效微调方法,包括 LoRA+(Hayou,2024)和 GaLore(Zhao,2024),集成到训练器中,替换默认组件。这些训练方法独立于训练器,因此可以轻松应用于各种任务。利用 Transformers(Wolf,2020)的训练器进行预训练和 SFT,同时采用 TRL(von Werra,2020)的训练器进行 RLHF 和 DPO。利用定制的数据整理器来区分各种训练方法的训练器。为了匹配训练器偏好数据的输入格式,在一个批次中构建 2n 个样本,其中前 n 个样本是选定的示例,后 n 个样本是拒绝的示例。
模型共享RLHF。允许在消费设备上进行 RLHF 训练是 LLM 微调的一个有用属性。然而,这个实现起来很困难,因为 RLHF 训练需要四种不同的模型。为了解决这个问题,提出了模型共享 RLHF,使整个 RLHF 训练只用一个预训练模型即可完成。具体来说,首先用奖励建模的目标函数训练一个适配器和一个V头,让模型计算奖励分数。然后初始化另一个适配器和V头,并用 PPO 算法 (Ouyang et al., 2022) 训练它们。在训练过程中,适配器和V头通过 PEFT (Mangrulkar et al., 2022) 的 set_adapter 和 disable_adapter API 动态切换,允许预训练模型同时用作策略、价值、参考和奖励模型。
分布式训练。将上述训练器与 DeepSpeed (Rasley et al., 2020) 结合进行分布式训练。利用 DeepSpeed ZeRO 优化器,可以通过分区或卸载进一步减少内存消耗。
加速推理。在推理期间,重用数据工作器的聊天模板来构建模型输入。支持使用 HF Transformers(Wolf,2020 年)和 vLLM(Kwon,2023)对模型输出进行采样,这两者都支持流解码。此外,还实现一个 OpenAI 风格的 API,该 API 利用异步 LLM 引擎和 vLLM 的paged attention来提供高吞吐量的并发推理服务,从而促进微调的 LLM 部署到各种应用程序中。
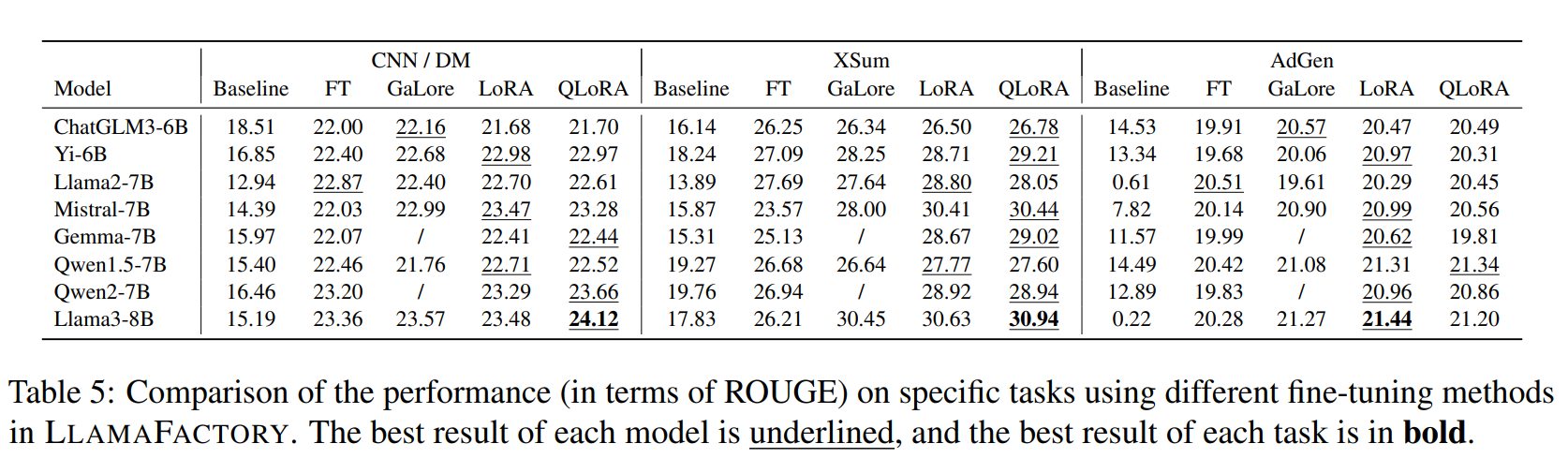
综合评估。纳入多项 LLM 评估指标,包括多项选择任务,如 MMLU(Hendrycks et al., 2021)、CMMLU(Li et al., 2023a)和 C-Eval(Huang et al., 2023),以及计算文本相似度分数,如 BLEU-4(Papineni et al., 2002)和 ROUGE(Lin, 2004)。
3.3 可视化界面
LLAMA-BOARD 是一个基于 Gradio(Abid,2019)的统一用户界面,允许用户自定义 LLM 的微调,而无需编写任何代码。它提供了简化的模型微调和推理服务,使用户能够在实践中轻松利用 100 多个 LLM 和 50 多个数据集。LLAMA-BOARD 具有以下显着特点:
易于配置。LLAMA-BOARD 允许用户通过Web 界面交互自定义微调参数。其为许多参数提供了推荐给大多数用户的默认值,从而简化了配置过程。此外,用户可以在 Web UI 上预览数据集以检查其自定义格式。
可监控的训练。在训练过程中,训练日志和损失曲线可视化和实时更新,使用户可以监控训练进度。此功能为分析微调过程提供了有价值的见解。
灵活的评估。LLAMA-BOARD 支持计算数据集上的文本相似度得分,自动评估模型或通过与模型聊天进行人工评估。
多语言支持。LLAMA-BOARD 提供本地化文件,方便集成新语言呈现界面。目前支持三种语言:英语、俄语和中文,这使得更广泛的用户能够使用 LLAMA-BOARD 来微调 LLM。
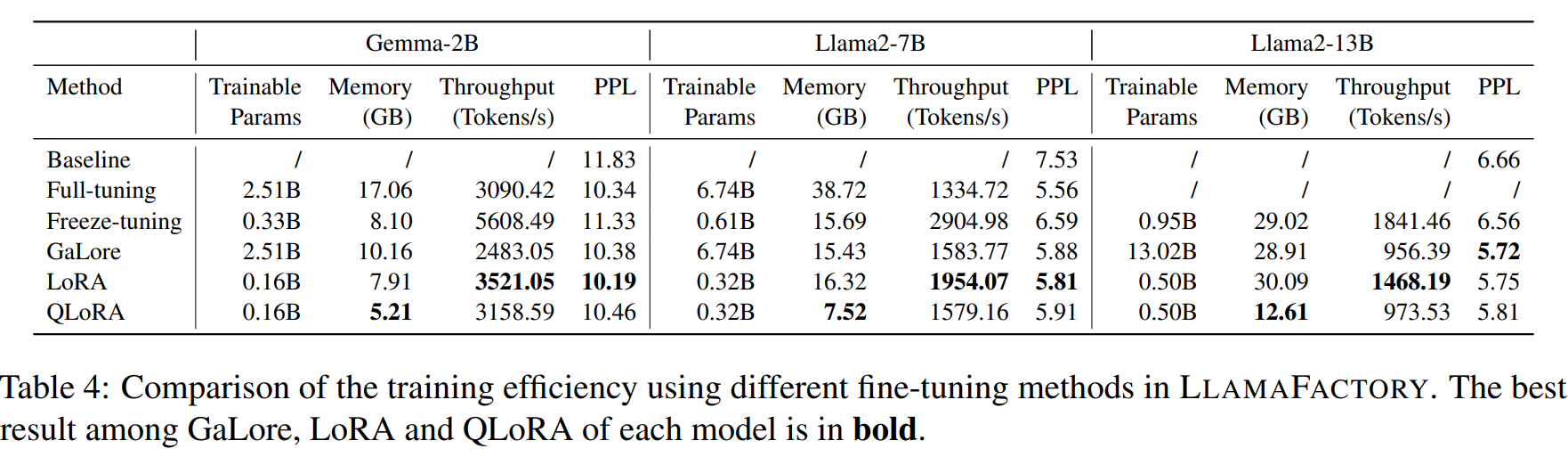
训练细节。采用 10−5 的学习率和 512 的tokens批处理大小,使用 8 位 AdamW 优化器(Dettmers,2022b)以 bfloat16 精度对这些模型进行微调,并使用激活检查点来减少内存占用。在冻结调整中,仅微调模型的最后 3 个解码器层。对于 GaLore,分别将秩和尺度设置为 128 和 2.0。对于 LoRA 和 QLoRA,将适配器连接到所有线性层,并将秩和 alpha 分别设置为 128 和 256。所有实验均在单个 NVIDIA A100 40GB GPU 上进行。在所有实验中启用flash attention,并在 LoRA 和 QLoRA 实验中启用 Unsloth。
四.总结
LLAMA-FACTORY 无疑可以规范工作流程,大大增加NLPer的工作效率,下表是其不同微调方法的训练效率对比参考: