论文题目:On LLMs-Driven Synthetic Data Generation, Curation, and
Evaluation: A Survey
论文链接:https://arxiv.org/pdf/2406.15126
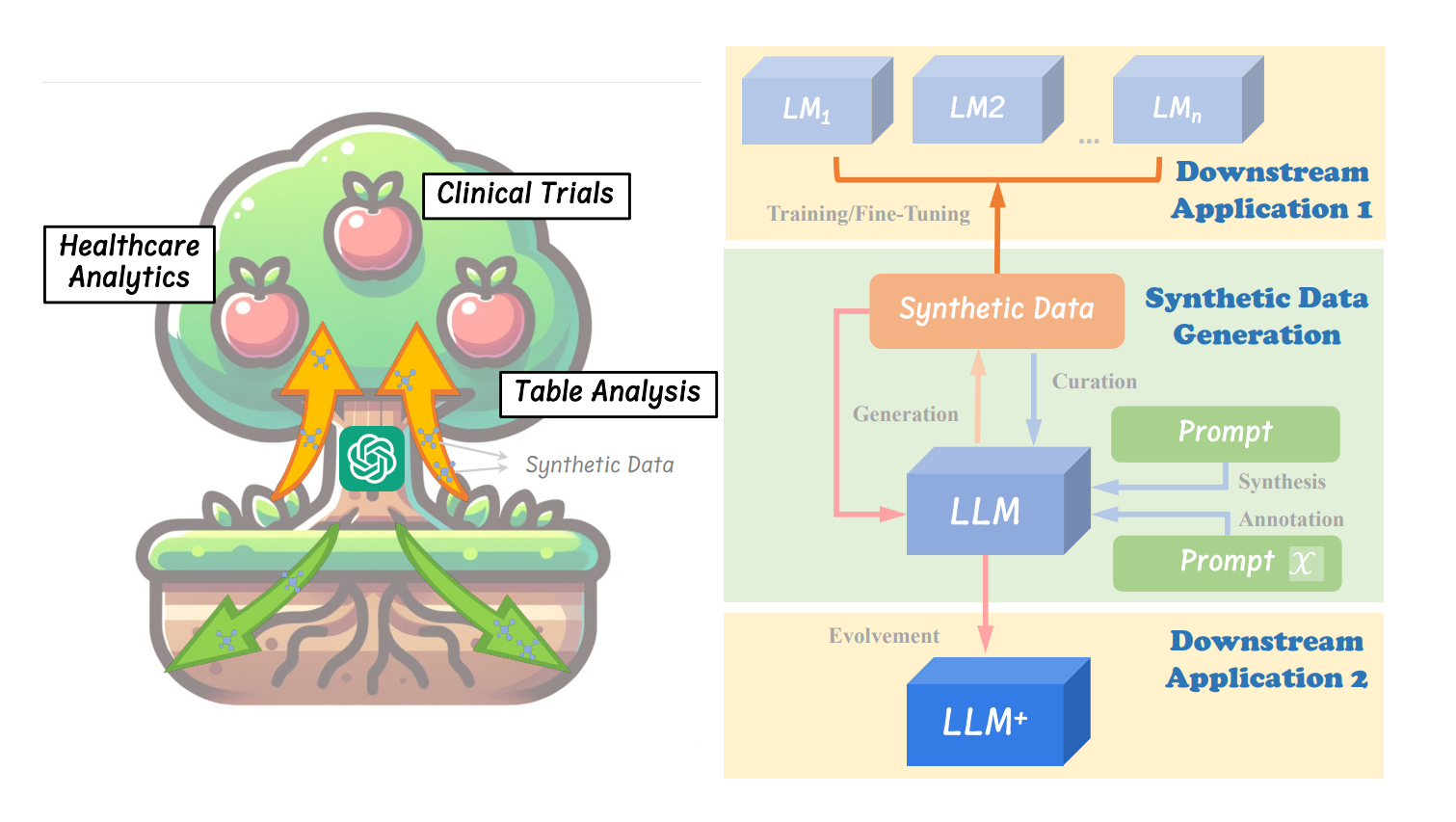
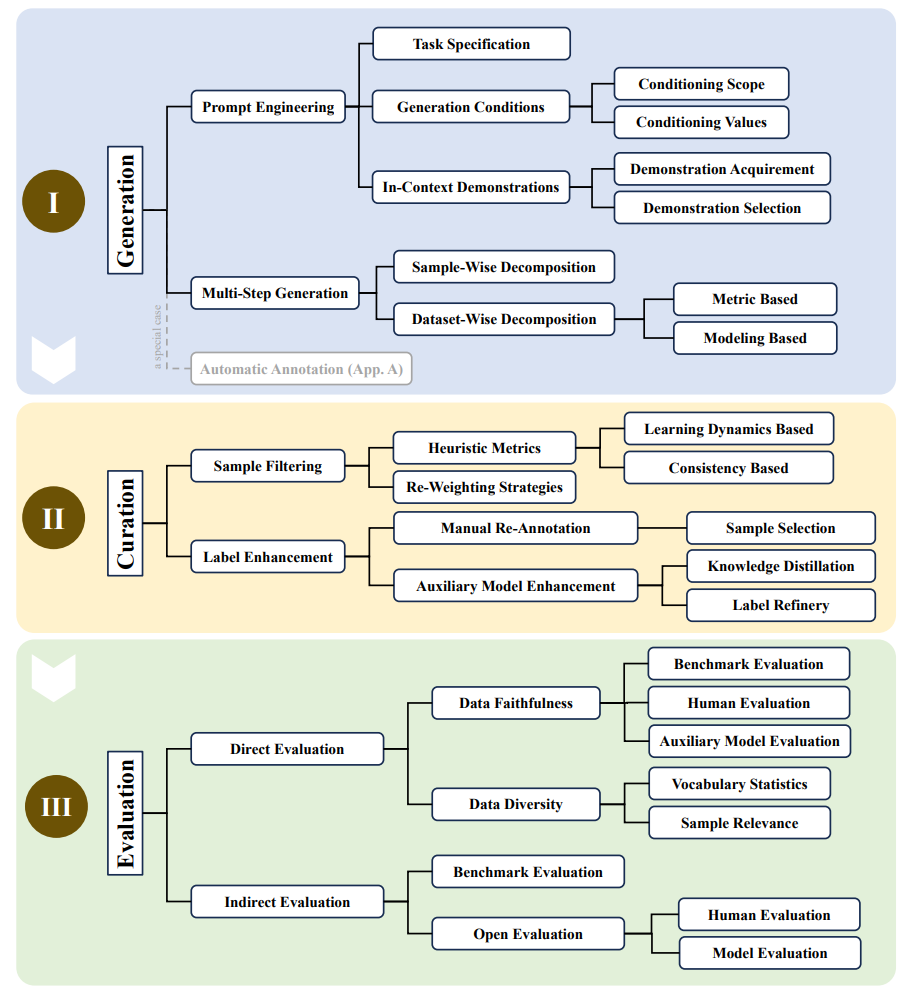
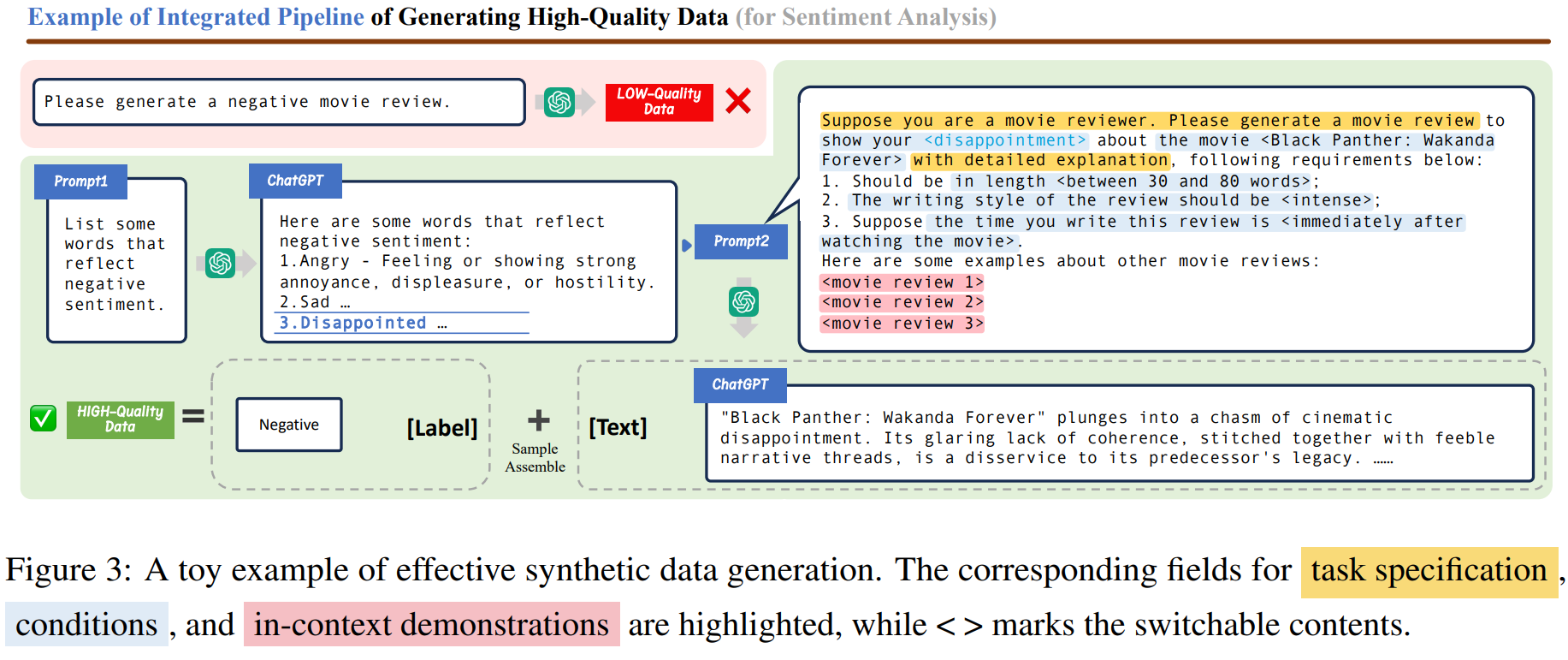
让我们大概了解使用 LLM 生成合成数据的基本过程:
1 2 3 4 5 6 7 8 9 10 11 12 13
from transformers import AutoTokenizer, AutoModelForCausalLM # Load a pre-trained LLM model_name = "gpt2-large" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name) # Define a prompt for synthetic data generation prompt = "Generate a customer review for a smartphone:" # Generate synthetic data input_ids = tokenizer.encode(prompt, return_tensors="pt") output = model.generate(input_ids, max_length=100, num_return_sequences=1) # Decode and print the generated text synthetic_review = tokenizer.decode(output[0], skip_special_tokens=True) print(synthetic_review)
few_shot_prompt = """ Generate a customer support conversation between an agent (A) and a customer (C) about a product issue. Follow this format: C: Hello, I'm having trouble with my new headphones. The right earbud isn't working. A: I'm sorry to hear that. Can you tell me which model of headphones you have? C: It's the SoundMax Pro 3000. A: Thank you. Have you tried resetting the headphones by placing them in the charging case for 10 seconds? C: Yes, I tried that, but it didn't help. A: I see. Let's try a firmware update. Can you please go to our website and download the latest firmware? Now generate a new conversation about a different product issue: C: Hi, I just received my new smartwatch, but it won't turn on. """ # Generate the conversation input_ids = tokenizer.encode(few_shot_prompt, return_tensors="pt") output = model.generate(input_ids, max_length=500, num_return_sequences=1) synthetic_conversation = tokenizer.decode(output[0], skip_special_tokens=True) print(synthetic_conversation)
import pandas as pd from sklearn.model_selection import train_test_split from transformers import pipeline # Load a small real-world dataset real_data = pd.read_csv("small_product_reviews.csv") # Split the data train_data, test_data = train_test_split(real_data, test_size=0.2, random_state=42) # Initialize the text generation pipeline generator = pipeline("text-generation", model="gpt2-medium") defaugment_dataset(data, num_synthetic_samples): synthetic_data = [] for _, row in data.iterrows(): prompt = f"Generate a product review similar to: {row['review']}\nNew review:" synthetic_review = generator(prompt, max_length=100, num_return_sequences=1)[0]['generated_text'] synthetic_data.append({'review': synthetic_review,'sentiment': row['sentiment'] # Assuming the sentiment is preserved}) iflen(synthetic_data) >= num_synthetic_samples: break return pd.DataFrame(synthetic_data) # Generate synthetic data synthetic_train_data = augment_dataset(train_data, num_synthetic_samples=len(train_data)) # Combine real and synthetic data augmented_train_data = pd.concat([train_data, synthetic_train_data], ignore_index=True) print(f"Original training data size: {len(train_data)}") print(f"Augmented training data size: {len(augmented_train_data)}")
这种方法可以显著增加训练数据集的大小和多样性,从而有可能提高机器学习模型的性能和稳健性。
挑战和最佳实践
虽然 LLM 驱动的合成数据生成提供了许多好处,但也带来了挑战:
质量控制:确保生成的数据质量高且与您的用例相关。实施严格的验证流程。
减少偏见:LLM
可以继承并放大其训练数据中存在的偏差。请注意这一点并实施偏差检测和缓解策略。
多元化:确保您的合成数据集多样化且能够代表真实世界场景。
持续一致:保持生成的数据的一致性,尤其是在创建大型数据集时。
关于
SCIREQ:要注意道德问题,尤其是在生成模仿敏感或个人信息的合成数据时。
LLM 驱动的合成数据生成的最佳实践:
迭代细化:根据输出的质量不断改进您的提示和生成技术。
混合方法:将 LLM
生成的数据与真实世界数据相结合以获得最佳结果。
验证:实施强有力的验证流程,以确保生成数据的质量和相关性。
配套文档:维护合成数据生成过程的清晰文档,以确保透明度和可重复性。
道德准则:制定并遵守合成数据生成和使用的道德准则。
结论
LLM 驱动的合成数据生成是一种强大的技术,它正在改变我们以数据为中心的
AI
开发方式。通过利用高级语言模型的功能,我们可以创建多样化、高质量的数据集,推动各个领域的创新。随着技术的不断发展,它有望在
AI
研究和应用程序开发中释放新的可能性,同时解决与数据稀缺和隐私相关的关键挑战。
随着我们不断前进,以平衡的视角看待合成数据生成至关重要,充分利用其优势,同时注意其局限性和道德影响。通过谨慎实施和不断改进,LLM
驱动的合成数据生成有可能加速 AI
进步并开辟机器学习和数据科学的新领域。