提升模型训练效率的十个Pytorch技巧
- One cycle学习率策略
- Batch size
- num workers & pin memory
- 自动混合精度训练
- torch.backends.cudnn.benchmark
- torch.nn.parallel.DistributedDataParallel
- 梯度累加
- 梯度裁剪
- BN前卷积层中的bias
- 陋习改正
在使用 PyTorch 进行深度学习模型训练时,提升训练效率和性能是至关重要的。以下是一些常用的 PyTorch 技巧,帮助提升模型训练效率:
1. One Cycle 学习率策略
One Cycle Learning Rate Policy 是一种动态调整学习率的方法,由 Leslie N. Smith 提出。其核心思想是在训练的前半部分逐渐增加学习率,然后在后半部分逐渐减小,从而加速收敛并提高模型的泛化能力。One Cycle 策略主要包含以下几个步骤:
- 增加阶段:从一个较小的初始学习率开始,逐步增加到一个较高的最大学习率。
- 减小阶段:从最大学习率开始,逐步减小到一个比初始学习率更小的终止学习率。
- 动量调整:同时调整动量值,在学习率增加时减小动量,在学习率减小时增加动量。
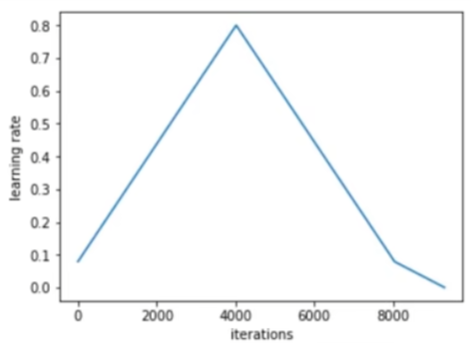
使用 One Cycle 学习率策略的好处包括: - 加快收敛速度。 - 避免模型陷入局部最优。 - 改善训练的稳定性。
在 PyTorch 中,可以使用
torch.optim.lr_scheduler.OneCycleLR 来实现 One Cycle
策略。例如:
1 | |
2. Batch Size
Batch size 是指在一次迭代中传递给模型的样本数量。调整 batch size 可以显著影响模型的训练速度和性能:
- 较大 batch size:
- 提高 GPU 的利用率,因为每次迭代处理更多数据。
- 减少更新模型参数的频率,可能会导致收敛速度变慢。
- 较小 batch size:
- 提高模型的泛化能力,因为更新更频繁,参数更易于捕捉数据分布的细微变化。
- 在内存允许的情况下,可以使用较大的 batch size 来提高训练速度。
在训练中,可以逐步增加 batch size 来找到内存和速度之间的平衡。还可以使用 Gradient Accumulation 来模拟较大的 batch size 而不增加显存使用。
3. num_workers & pin_memory

num_workers 和 pin_memory 是
DataLoader 中的两个重要参数,它们影响数据加载效率:
- num_workers:指定数据加载时使用的子进程数量。增大
num_workers可以提高数据加载速度,但设置过高可能导致资源竞争或内存不足。- 对于 CPU 核心较多的机器,可以尝试增大
num_workers,通常设置为 CPU 核心数的 2 到 4 倍。 - 对于小数据集或 IO 受限的情况,适当的增大
num_workers也可以提升性能。
- 对于 CPU 核心较多的机器,可以尝试增大
- pin_memory:如果设置为 True,DataLoader 会在将张量转移到 GPU 前将它们锁页到内存中。对于 CUDA 后端,这通常可以加快数据转移速度。
1 | |
4. 自动混合精度训练
自动混合精度(AMP)训练是一种通过使用半精度(FP16)和单精度(FP32)混合计算来加速模型训练的方法。AMP 可以有效减少显存使用并提高训练速度,同时通常不会影响模型精度。
在 PyTorch 中,可以使用 torch.cuda.amp
模块来实现自动混合精度训练:
1 | |
自动混合精度训练的优点:
- 内存效率:减少显存使用,使得可以增大 batch size。
- 速度提升:在不显著影响模型精度的前提下加速训练。
注意:使用 AMP 时需要确保梯度不会溢出,并使用 GradScaler
来防止数值不稳定性。
5. 动态调整卷积操作
- 功能:
torch.backends.cudnn.benchmark是 PyTorch 中一个设置,可以动态调整卷积操作的算法以提高 GPU 上的性能。 - 工作原理:在 GPU
上进行卷积操作时,有多种算法可供选择。
benchmark会让 cuDNN 进行测试,以选择最适合当前卷积层配置(如输入大小、批量大小等)的算法。这对于输入大小固定的场景尤其有用,因为可以显著减少算法选择带来的开销。 - 使用建议:在输入大小不变的情况下开启,可以提升性能。但是如果输入大小会变(比如处理变长序列),不建议开启,因为每次输入改变时都需要重新测试,反而降低性能。
1 | |
6. 分布式训练模块DDP

- 功能:
DistributedDataParallel(DDP)是 PyTorch 中用于分布式训练的模块,允许跨多 GPU 和多节点并行地训练模型。 - 工作原理:DDP 将模型复制到多个 GPU 上,每个 GPU 上的模型处理一部分数据。各个 GPU 之间通过梯度同步机制确保更新的一致性。
- 使用建议:在多 GPU 训练中优先使用 DDP,而不是
DataParallel,因为 DDP 的通信开销较小,且更具扩展性。使用 DDP 可以充分利用多个 GPU 和节点的计算资源,加快训练过程。 - 拓展:huggingface中的
1 | |
7. 梯度累加
- 功能:梯度累加(Gradient Accumulation)是一种技术,可以通过多次反向传播累积梯度,模拟更大批量的训练效果,而不需要增加显存占用。
- 工作原理:将一个大批量划分为多个小批量,每个小批量计算完损失后执行反向传播,但不立即更新权重,而是累积梯度,直到累积一定次数后才执行优化器的
step操作更新模型权重。 - 使用建议:适用于显存不足以支撑大批量训练的情况,通过这种方式可以有效提高模型的泛化能力。
1 | |
8. 梯度裁剪
- 功能:梯度裁剪(Gradient Clipping)用于控制梯度的大小,防止梯度爆炸问题。
- 工作原理:在反向传播时对梯度进行裁剪,如果梯度的范数超过预设阈值,则按比例缩小,使得训练更稳定。
- 使用建议:在 RNN 或者深度网络中使用,有助于稳定训练过程,尤其是在处理梯度爆炸问题时。
1 | |
9. BN 前卷积层中的 bias
- 功能:在 Batch Normalization(BN)层前的卷积层中通常不需要使用偏置(bias)项。
- 工作原理:BN 层会对每个特征进行标准化并重新添加缩放和偏移参数,因此卷积层的偏置会被 BN 层的偏置覆盖,成为冗余。
- 使用建议:在使用 BN 的模型中,可以去掉卷积层中的偏置参数,以减少计算量和内存使用,尤其是在较大模型中有显著效果。
1 | |
10.减少不必要的数据复制和设备之间的数据传输
- 避免频繁使用
torch.cpu()和torch.cuda():- 建议: 在训练过程中,尽量减少在 CPU 和 GPU 之间频繁切换张量。这是因为这种操作涉及大量的数据传输,会显著降低训练速度。
- 优化方法: 尽量将所有计算都放在 GPU 上进行,以减少数据在设备之间的传输。
- 避免使用
torch.tensor():- 原因:
torch.tensor()每次调用都会复制数据,导致额外的内存开销。 - 替代方法: 使用
torch.as_tensor(),这会共享数据,不会进行复制,从而提高效率。
- 原因:
- 使用
torch.as_tensor()和torch.from_numpy():torch.as_tensor(): 直接将已有的数据转化为张量,并且不会进行数据的复制,适合在已有数据需要转换为张量时使用。torch.from_numpy(): 可以将 NumPy 数组转换为张量,且不会复制数据。这个方法适用于已有数据在 NumPy 格式时。
提升模型训练效率的十个Pytorch技巧
https://linxkon.github.io/提升模型训练效率的十个Pytorch技巧.html