AI技术在NLP领域的演进与实践
引言
在人工智能技术快速发展的今天,我们见证了一场前所未有的技术革命。从最初的机器学习算法到如今风靡全球的大语言模型(LLM),AI技术正在以惊人的速度重塑着我们的工作和生活方式。
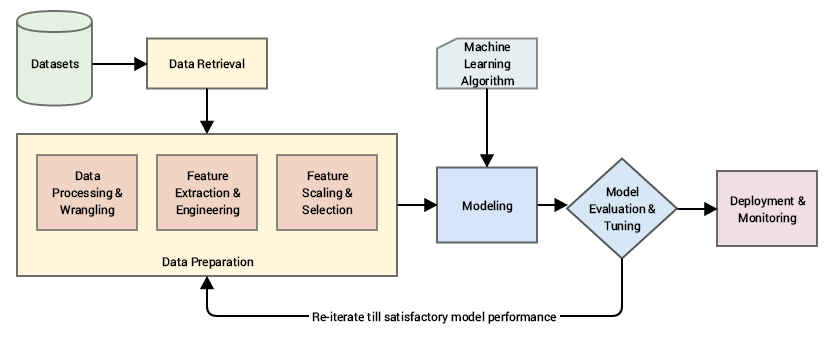
本文将带领大家循序渐进地探索AI技术的演进历程和实践应用。分享分为两部分,第一部分主要是从机器学习的基础概念出发,解析其如何一步步发展成为今天强大的语言模型,并针对具体任务给出一个简单示例。第二部分我们将深入剖析LLM的工程化应用,特别是检索增强生成(RAG)以及Agent技术如何帮助我们构建更智能、更可靠的AI应用系统。
从机器学习到语言模型
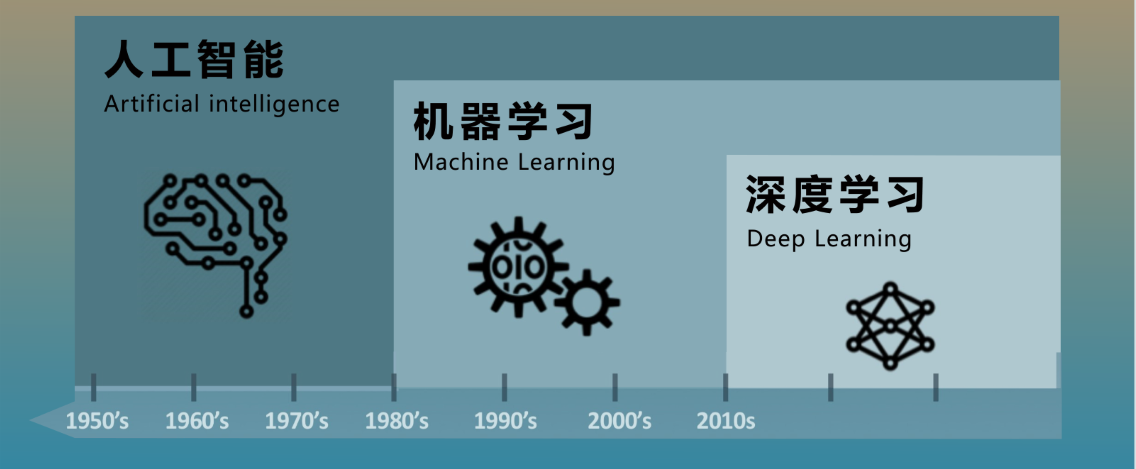
在进入主题之前,让我们先了解一下人工智能、机器学习与深度学习的关系
人工智能 (AI):AI的概念最早可以追溯到20世纪50年代,由麦卡锡、香农等学者提出。它旨在让机器展现出类似人类的智能能力,包括感知、学习、推理、规划、语言理解与生成等。AI的核心目标是开发能够解决复杂问题并执行智能任务的系统。
机器学习 (ML):ML 是实现 AI 的一种方法,它让机器通过数据自动学习模式并进行决策,而不是通过硬编码规则。
深度学习(DL)是机器学习的子集,深度学习的一大特点是用神经网络的方式来解决算法建模问题。深度学习两个热门的方向是CV,现在热门的实践应用包括智能驾驶技术。
机器学习算法
机器学习可以看作是让机器从数据中学习规律,从而进行预测或决策。想象一下,我们想让机器学会区分苹果和橘子,或者预测明天的股票价格,这就是机器学习可以做的事情。
1.1 机器学习主要解决两个核心问题:分类与回归
分类 (Classification): 就像给东西贴标签。机器会学习如何把数据分到不同的类别里。例如情绪识别、图像识别等问题。
常见传统机器学习算法: 逻辑回归 (Logistic Regression)、支持向量机 (SVM)、集成学习 (Ensemble Learning)、K近邻 (KNN) 等。
回归 (Regression): 就像预测一个数值。机器会学习如何根据输入的数据,预测一个连续的输出值。例如房价预测、股票预测等问题。 常见算法: 线性回归 (Linear Regression)、多项式回归 (Polynomial Regression) 等。
1.2 机器学习的基础概念
特征工程:指利用领域知识从原始数据中提取、构造或选择出对预测模型有用的特征的过程,它能够帮助模型更好地找到数据内在的规律,传统机器学习和深度学习的一大区别是ML更加依赖于特征工程。
样本与标签:样本指用于训练机器学习模型的单个数据实例,它一般由若干“特征”组成。标签是与样本相对应的答案或目标值。
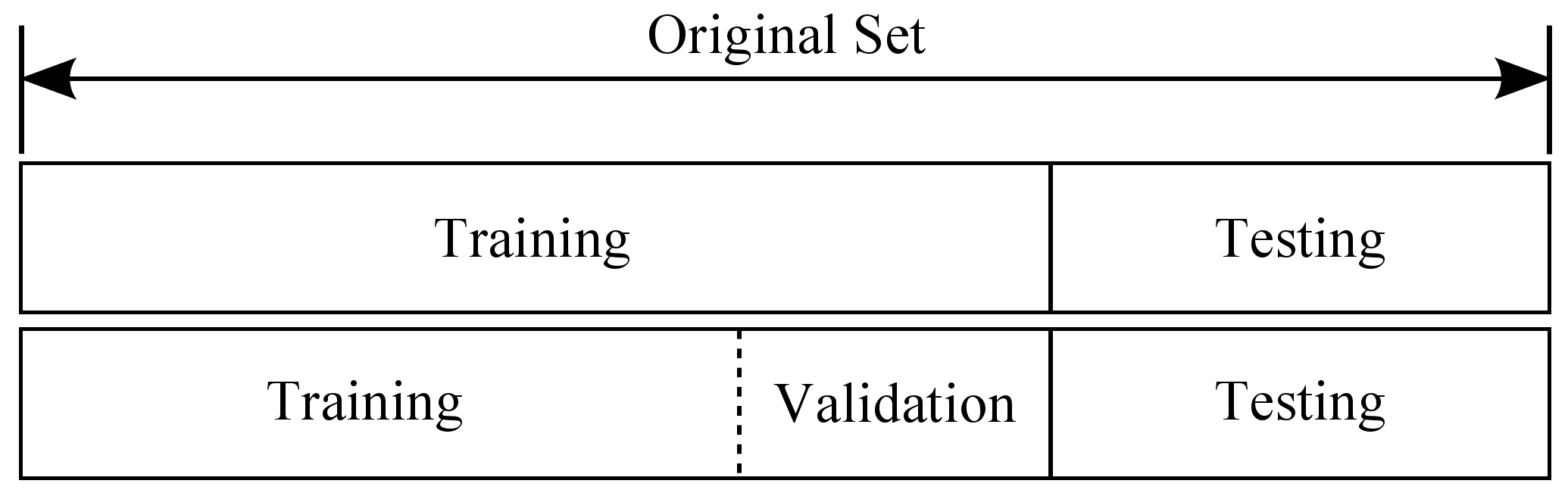
训练集与测试集:训练集用于模型训练,测试集用于模型训练结果的评估;训练集还可以进一步划分出一部分数据作为验证集。
1.2 机器学习算法示例-random forest解决情绪识别问题
机器学习算法种类繁多,思想迥异。接下来以集成学习中 Bagging 方法的代表算法——随机森林(Random Forest)为例,展开说明。同时结合TF-IDF构建特征与随机森林建模的方式演示如何解决情绪识别问题。
1.2.1 Bagging与Random Forest
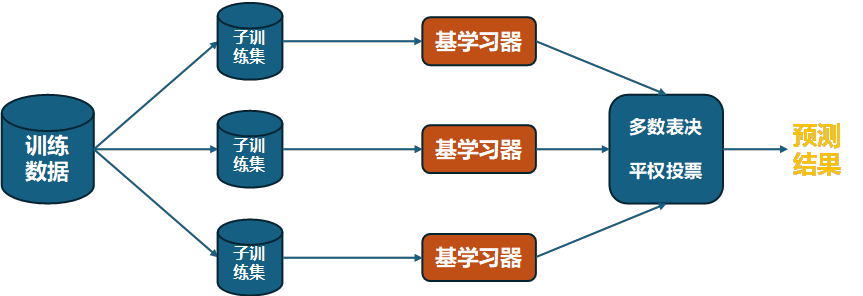
Bagging是一种集成学习技术,它通过对原始数据集进行有放回的随机抽样(Bootstrap sampling)来构建多个训练集,然后在这些训练集上分别训练出多个基学习器(如决策树、神经网络等),最后将这些基学习器的预测结果通过某种策略(如投票、平均等)组合起来作为最终的预测结果。
Random Forest模型技术要点
1.2.2 TF-IDF方法构建特征工程
词频-逆文档频率法(TF-IDF)是一种常用的文本特征提取方法,用于衡量单词在文档和整个语料库中的重要性。它的计算方法为:

其核心思想是
- 高 TF 值表示单词对当前类型文档具有较好的表征能力。
- 高 IDF 值表示单词能更好地区分不同类型文档。
- 通过TF-IDF,常用词被赋值为低权重,独特词被赋值为高权重。
1.2.3 代码演示
示例代码已分享至github,点击下载使用:github.com
路径:/A_random_forest/
1 | |
- 文本标签映射为数字
- 使用jieba分词构建词样本数据
1 | |
- 词频-逆文档频率法(TF-idf)构建特征词向量
- 使用sk-learn库中Random Forest构建分类模型
- 模型的评估、保存
1 | |
- 模型推理调用
2. 深度学习算法
传统的机器学习算法虽然对一些简单任务快捷有效,但是却非常不擅长处理一些复杂的建模问题,比如图像分类、语言生成等,这时候我们就需要更加强大的新算法——深度学习。
深度学习使用神经网络建模,使模型具备了特征自动提取的能力,以及更加强大的学习表达能力。
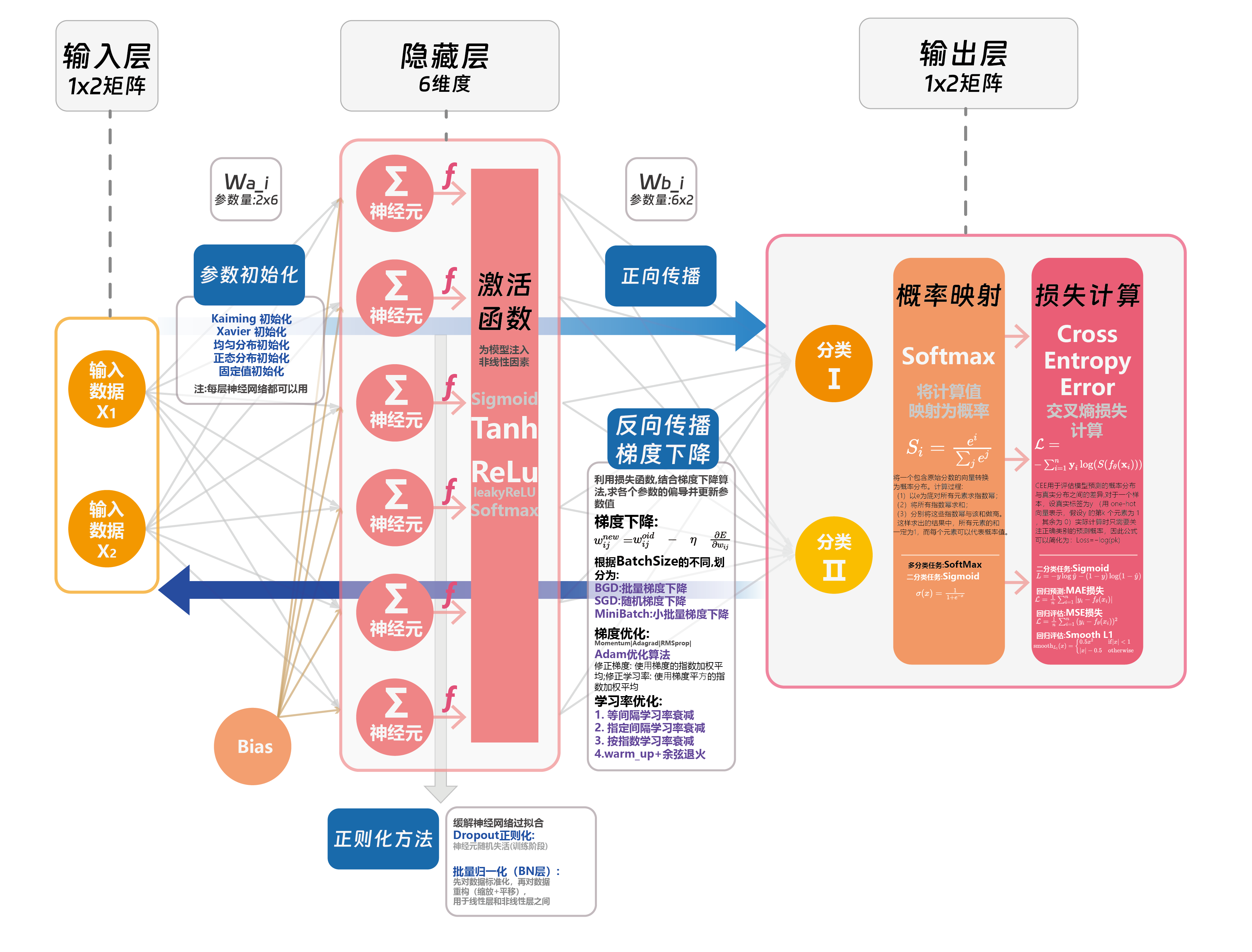
2.1 神经网络
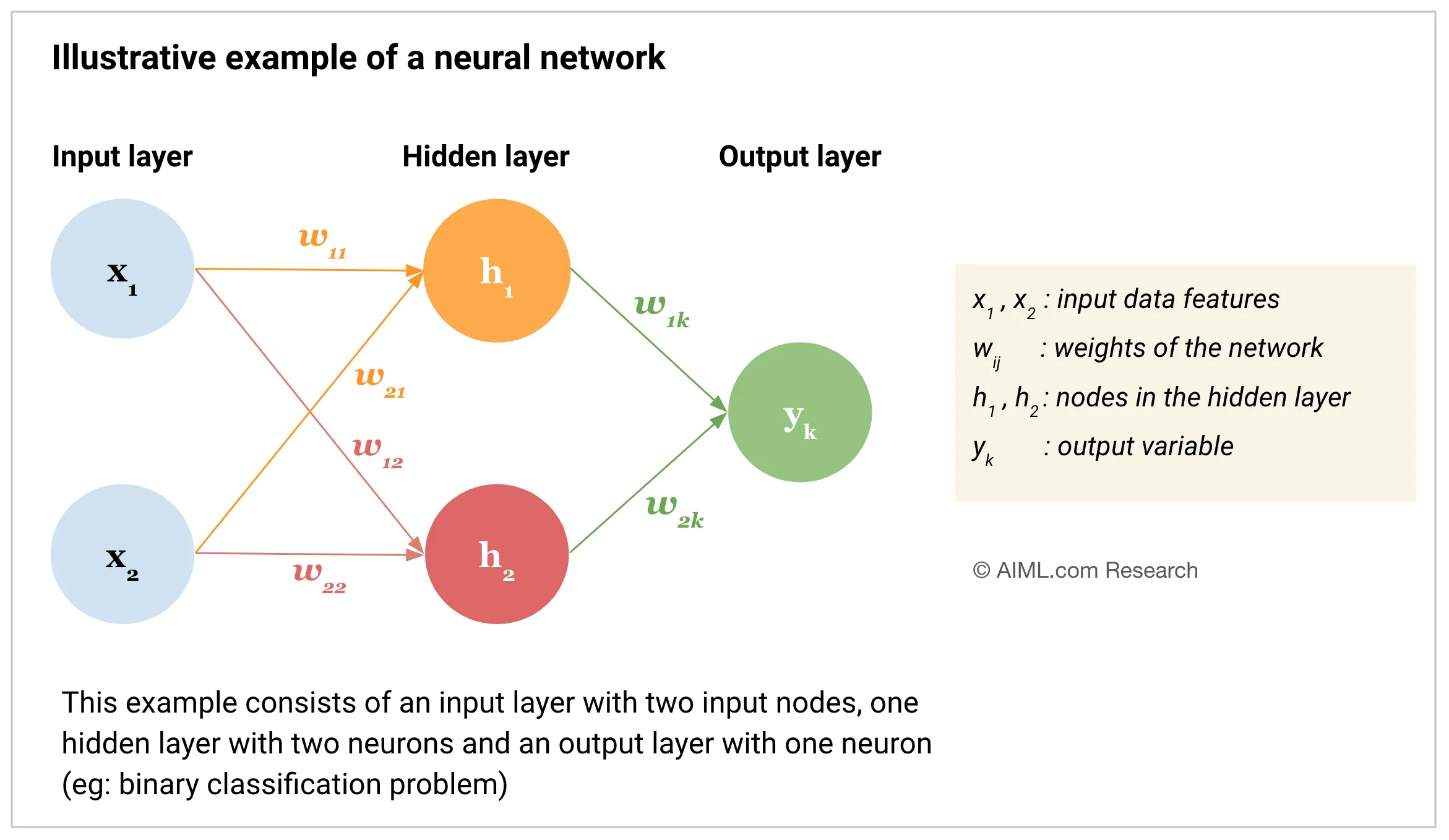
神经元
神经元是神经网络的基本计算单元,模拟生物神经元的工作方式。它接收输入信号,对其加权求和后,使用激活函数决定输出。
权重 (Weights) 和偏置 (Biases)
权重是神经网络中连接不同层之间的参数,反映输入特征的重要性。
偏置允许模型在输入为零时也能输出非零值,增强模型的表达能力。
神经网络架构
神经网络由多个“神经元”组成,这些神经元按层(layers)排列。通常来讲可以分为以下
输入层 (Input Layer): 接收数据,例如一张图片的所有像素值。
隐藏层 (Hidden Layer): 对输入数据进行处理和转换。可以有多个隐藏层,层数越多,模型越复杂。
输出层 (Output Layer): 输出结果,例如分类问题中每个类别的概率,或回归问题中的预测值。
2.2 神经网络的机制
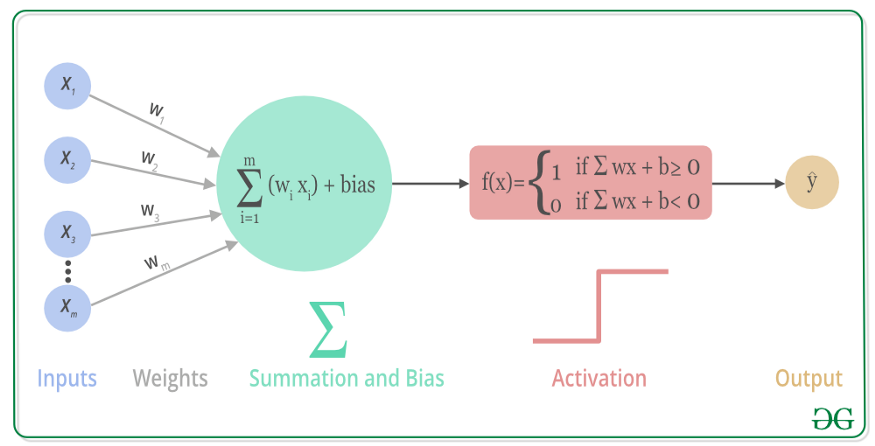
2.2.1 神经网络的基础机制
神经网络模型通过以下两个步骤实现其对数据的学习建模能力
Step1:【前向传播】+【损失函数】计算损失
前向传播(Forward Propagation):是神经网络中将输入数据转换为输出数据的过程。它通过将输入数据逐层传递通过网络的各个层,并在每一层应用激活函数来计算输出值。
损失函数(Loss FN):描述的是预测值ŷ与真实值y之间的差异,常用的损失计算方法有均方误差(缩写为MSE,用于回归问题)、交叉熵损失(softmax损失,用于分类问题)
Step2:【反向传播】+【梯度下降】更新梯度值
反向传播:从输出层开始,逐层计算每个神经元对损失函数的贡献,并根据链式法则计算每个权重的梯度。
梯度下降:通过寻找梯度负方向的方式迭代调整模型参数,使损失函数逐渐减小,最终找到其最小值。
梯度下降的原理
梯度下降法是一种寻找使损失函数最小化的方法。从数学上的角度来看,梯度的方向是函数增长速度最快的方向,那么梯度的反方向就是函数减少最快的方向,梯度下降的过程如下图所示:
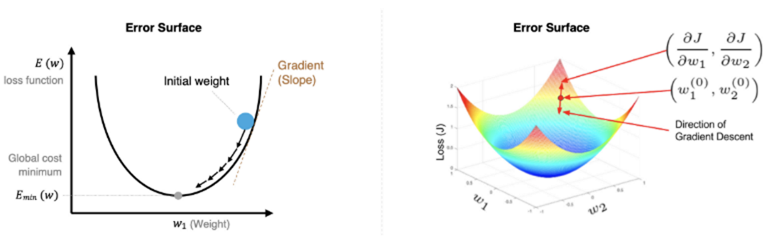
梯度下降公式:
\[w_{ij}^{new}=w_{ij}^{old}\quad-\quad\eta\quad\frac{\partial E}{\partial w_{ij}}\]
W_new为更新后的参数值,W_old为更新前的参数值,η是学习率,\[\frac{\partial E}{\partial w_{ij}}\]是损失函数对参数的梯度,即损失函数在参数处的导数。
2.2.2 从数据流向来理解梯度值的更新过程
构建一个2-2-2结构的前馈神经网络(如下图)
示例代码:example\nerual_network_BP.py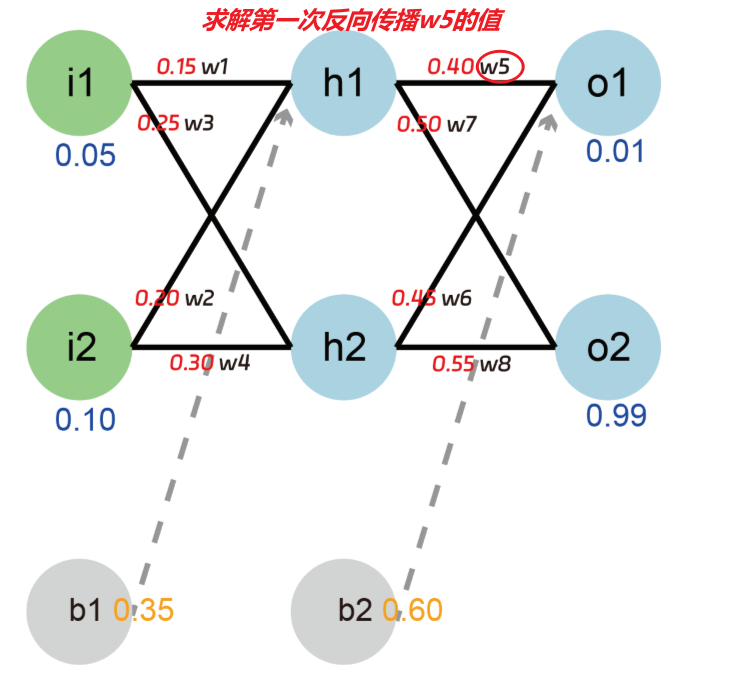
输入层:
- 包含两个节点 i1 和 i2,它们的输入值分别为 0.05 和 0.10。
隐藏层:
- 包含两个神经元 h1 和 h2。
输出层:
- 包含两个神经元 o1 和 o2,它们的输出值分别为 0.01 和 0.99。
参数初始化值:如图红色数字
共计2个输入节点,4个神经元,12个参数
网络类型:线性层
激活函数:sigmoid
学习率:0.5
目标:求解第一次梯度下降后w5的数值



依此类推,可以得到W6,W7,W8的值,继而可进一步推算出其它参数的值,至此,我们完成了第一步的梯度更新
以后便是重复以上步骤持续更新参数,直到到达指定步数或损失值
2.2.3 神经网络的其它机制
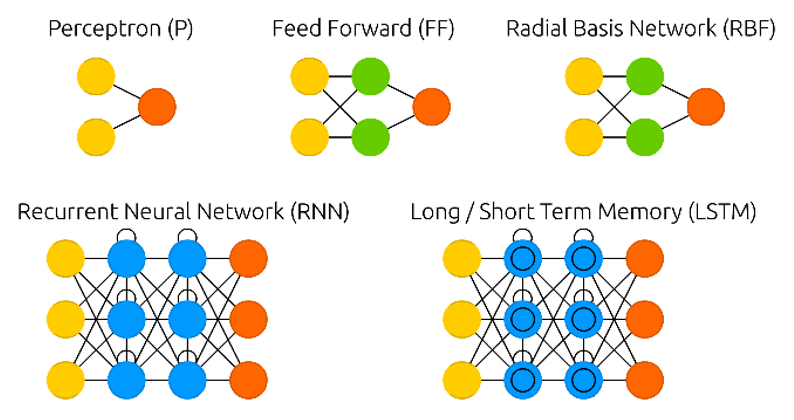
2.3 深度学习算法示例-LSTM解决情绪识别问题
通过基础神经元的组合以及隐藏层的设计,可以构建出多种神经网络架构,例如前文提到的前馈神经网络(FF)、循环神经网络(RNN)、长短期记忆网络(LSTM)等(如下图)。接下来,我们以LSTM为例进行详细讲解。
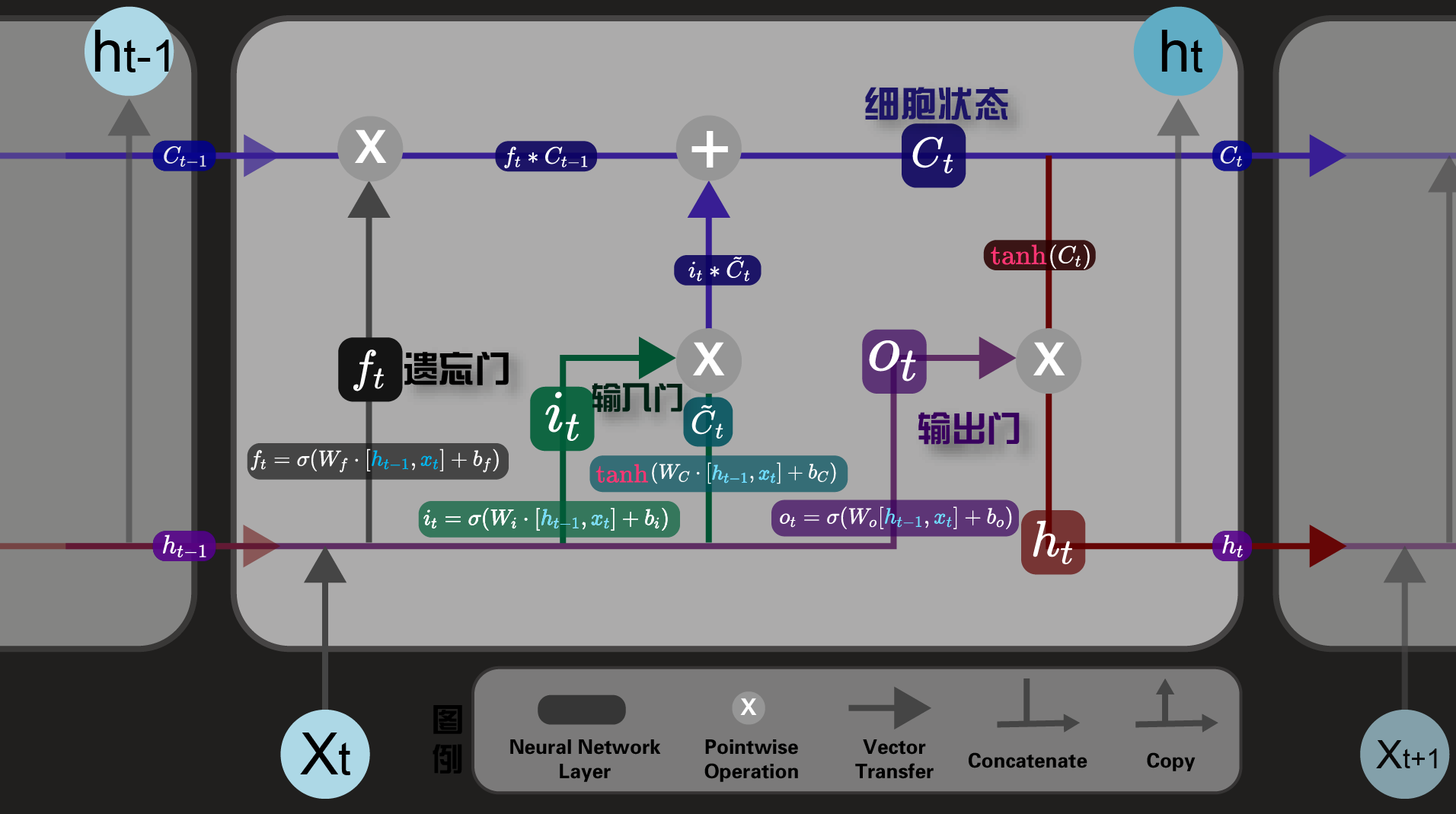
2.3.1 LSTM简介
LSTM(Long Short-Term Memory)也称长短时记忆结构, 它是RNN的变体, 与经典RNN相比能够有效捕捉长序列之间的语义关联, 缓解梯度消失或爆炸现象。LSTM的核心结构可以分为四个部分去解析:
1.细胞状态(CellState):用于保存长期的状态信息,可以看作是贯穿整个序列的“记忆”。
2.遗忘门(ForgetGate):决定当前时间步的记忆细胞状态中哪些信息需要丢弃。遗忘门通过一个sigmoid函数来决定保留哪些信息,输出在0到1之间。
3.输入门(InputGate):决定哪些新的信息需要添加到记忆细胞中。输入门也由一个sigmoid函数控制,用来选择性地更新细胞状态。
4.输出门(OutputGate):控制从细胞状态中输出的信息,决定哪些部分将作为下一个隐藏状态输出。
细胞状态更新:通过遗忘门和输入门的作用,更新当前细胞状态,形成新的细胞状态和隐藏状态。
2.3.2 代码演示
1 | |
使用torch库构建数据处理类
- 三个基础方法
构建模型架构:TextClassifier类
- 一个继承
- 两个方法
模型训练和评估函数
1 | |
- 数据加载处理
- 构建词表与标签映射
- 创建数据集实例
- 创建数据加载器
- 初始化模型
- 定义损失函数和优化器
- 训练模型
- 评估模型
1 | |
模型加载与推理
Transformers与预训练语言模型
传统RNN在处理长序列任务时难以记住早期信息。虽然LSTM通过门控机制在一定程度上缓解了这个问题,但直到注意力机制和Transformer的出现才真正突破了这一限制。
3.1 注意力机制与 transfomers架构
3.1.1 注意力机制
基础概念:
注意力机制 (Attention Mechanism) 是一种模仿人类注意力认知机制的技术,它允许模型在处理信息时,集中关注于输入中最相关的部分,从而提高模型的性能。就像我们在阅读一篇文章时,会重点关注一些关键词句,忽略一些不重要的细节,注意力机制也让模型学会了这种 "聚焦" 的能力。
核心思想:为输入数据的每个部分分配一个权重,权重越高,表示该部分越重要,模型会更加关注它。这些权重是动态计算的,会根据不同的输入和任务目标而变化。
注意力机制有很多种,比如硬注意力、软注意力、自注意力等,接下来以经典的自注意力为例进行讲解。
自注意力机制(Self-Attention):
自注意力机制是实现序列的子元素间互相关注的一种机制。通过自注意力机制,每个位置的表示可以动态地关注序列中其他位置的信息,特别是那些与当前表示有较高相关性的部分。
自注意力机制的核心概念:
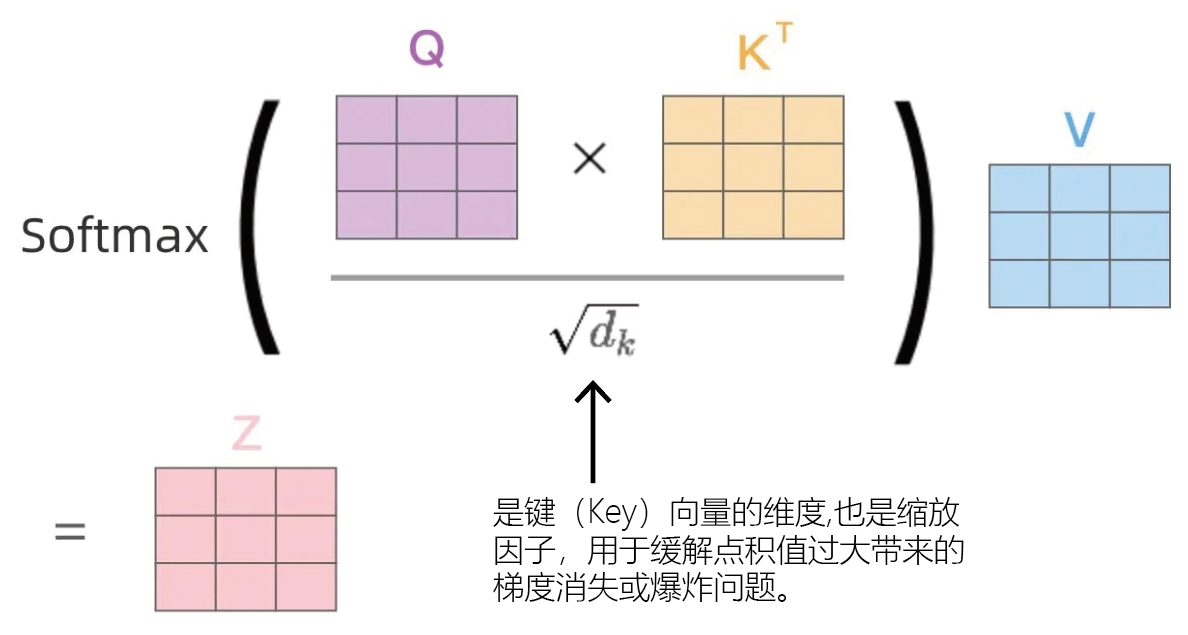
自注意力机制的核心概念有四个,分别是Q、K、V和评分函数,其中
Query(Q)、Key(K)和Value(V)三个矩阵都是通过对输入进行线性变换得到的,评分函数常用缩放点积的方式实现,以下为具体的解释:查询矩阵(Query, Q):查询矩阵包含了要从其他位置获取信息的请求。Query(查询)是一个特征向量,描述我们在序列中寻找什么,即我们可能想要注意什么。
键矩阵(Key, K):每个输入元素有一个键,它也是一个特征向量。该特征向量粗略地描述了该元素“提供”什么,或者它何时可能很重要。键的设计应该使得我们可以根据Query来识别我们想要关注的元素。
值矩阵(Value, V):每个输入元素,我们还有一个值向量。这个向量就是我们期望得到的平均向量。
Score function:评分函数为了对想要关注的元素进行评分,我们需要指定一个评分函数f该函数将查询和键作为输入,并输出查询-键对的得分/注意力权重。它通常通过简单的相似性度量来实现,例如点积。
自注意力通常以缩放点积的方式实现,其公式为:
下图直观地描述了自注意力如何作用在一系列单词上。
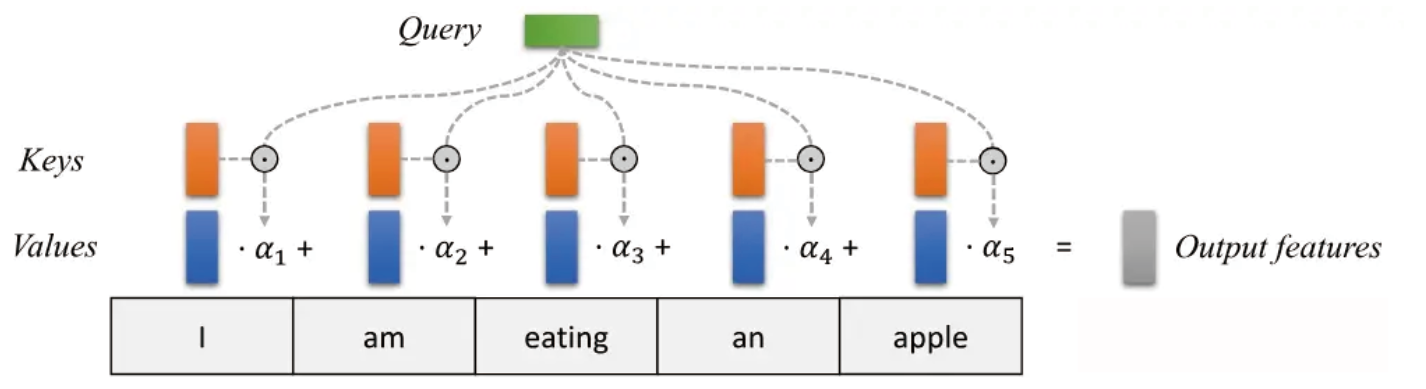
输入单词序列(最下方的灰色框):
- 这是输入的一组词,表示为 "I am eating an apple"。每个词会被嵌入成一个向量(Embedding),用于后续计算。
Keys, Values, Query:
- 对每个输入词,我们生成三个向量:Key (橙色)、Value (蓝色)、Query (绿色)。这些向量由嵌入向量通过不同的线性变换得到,用于计算注意力权重和输出。
α 权重:
- 每个输入词的 Query 和所有词的 Key 进行点积(计算相似度),再通过 Softmax 得到注意力权重(α)。
- 这些权重反映了当前 Query 词与每个输入词的相关性。
加权求和(Weighted Sum):
- 权重 α 作用于对应的 Value 向量,计算加权求和,得到当前词的输出向量。
输出特征:
- 最终,输出特征是每个词加权后的向量,用于后续层的处理。
多头自注意力机制
多头注意力机制是对自注意力机制的扩展。它通过引入多个注意力头,允许模型从不同的表示子空间中获取信息,从而增强模型的表达能力。具体来说:
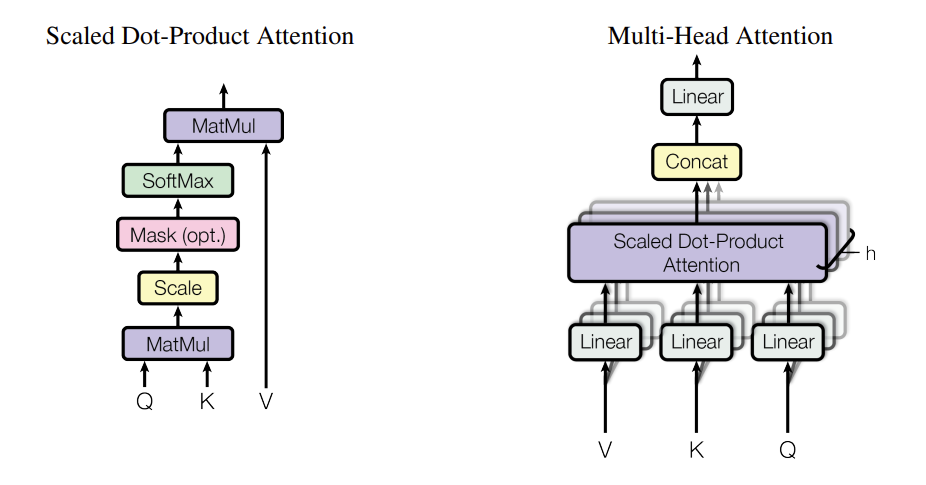
- 将 Q、K、V 分成多个子空间,每个子空间独立计算注意力。
- 最终将各头的输出拼接起来,经过线性变换得到结果。
- 作用:捕捉不同语义关系,提高模型表达能力。
理解了多头自注意力机制,便理解了transfomers架构的核心内容。
3.1.2 transfomers架构
2017年,来自谷歌的Google Brain团队发布题为《Attention Is All You Need》的论文,该论文提出Transformer这一革命性架构,从此世界进入Scale Law主宰的大模型时代。
Transformer最突出的贡献就是解决了传统RNN和LSTM等序列处理中的长距离依赖差、计算效率低、拓展性差三大核心问题,被广泛应用于自然语言处理(NLP)任务,例如机器翻译、文本摘要等,除此之外也被广泛应用于各种其它领域,包括计算机视觉、语音识别等。Transformer已经成为现代深度学习中的主流架构。
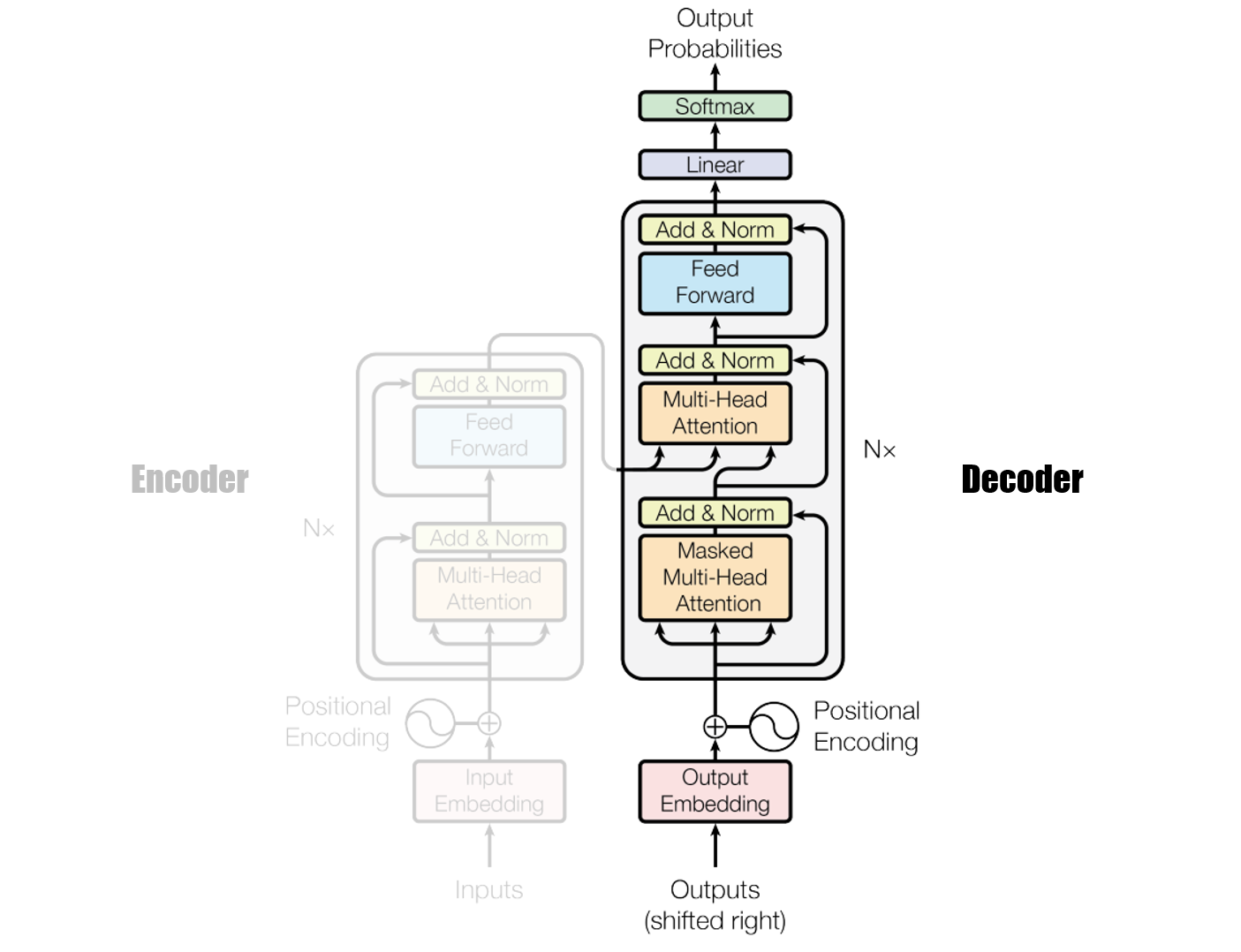
Transformers的模型架构
一个典型的 Transformer 模型主要由两部分组成:编码器(Encoder) 和 解码器(Decoder)。
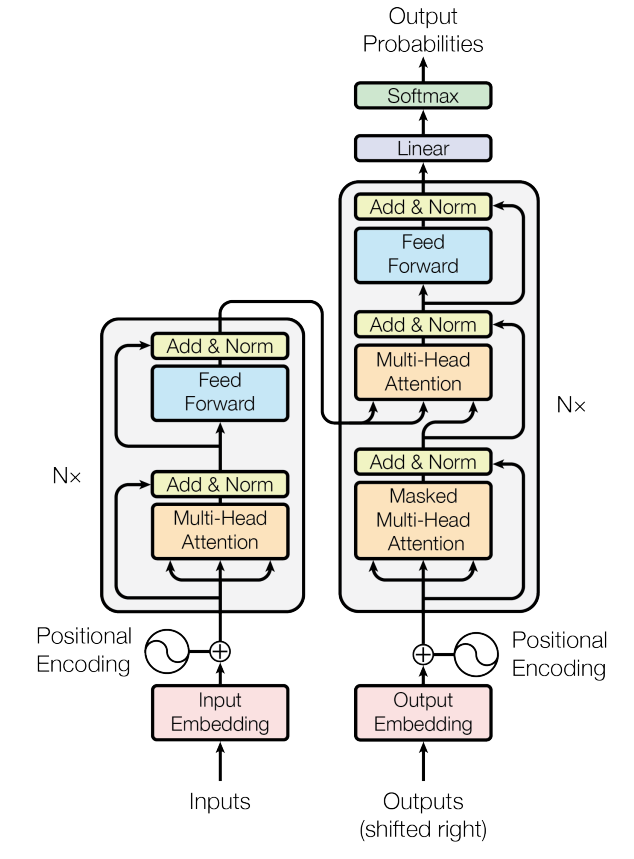
- 编码器(Encoder):
- 作用: 将输入序列(例如一个句子)编码成一个包含丰富语义信息的 上下文向量(Context Vector)。
- 结构: 通常由 N 个相同的编码器层堆叠而成(论文中
N=6)。每个编码器层包含两个主要子层:
- 多头自注意力层(Multi-Head Self-Attention): 这是 Transformer 的核心。它允许模型关注输入序列中不同位置的单词,并计算它们之间的关系,从而捕捉上下文信息。
- 前馈神经网络层(Feed-Forward Network): 对每个位置的单词表示进行非线性变换,进一步增强模型的表达能力。
- 输入: 输入序列(例如单词序列)经过词嵌入(Word Embedding)和位置编码(Positional Encoding)后,输入到编码器中。
- 解码器(Decoder):
- 作用: 根据编码器生成的上下文向量和已生成的输出序列,生成目标序列(例如翻译后的句子)。
- 结构: 也由 N 个相同的解码器层堆叠而成(论文中
N=6)。每个解码器层包含三个主要子层:
- 掩码多头自注意力层(Masked Multi-Head Self-Attention): 与编码器中的自注意力层类似,但会添加一个掩码(Mask),以防止解码器在生成当前单词时“偷看”到未来的单词,确保生成的序列是自回归的。
- 多头自注意力层(Multi-Head Self-Attention): 允许解码器关注编码器输出的上下文向量,从而获取输入序列的信息。
- 前馈神经网络层(Feed-Forward Network): 与编码器中的前馈神经网络层相同。
- 输入: 解码器的输入包括两部分:编码器输出的上下文向量和已生成的输出序列(经过词嵌入和位置编码)。
3.2 预训练语言模型
基于transformer架构的强大能力,使用大规模语料集训练“多用途”的预训练语言模型(PLM)成为热门趋势;而大语言模型(LLM),可以简单理解为参数量超过10亿的预训练语言模型。
大语言模型相对于传统NLP模型的核心优势就是通过强大的泛化能力和上下文理解能力,统一了各类NLP任务的解决范式,甚至重塑了人类整合和获取知识的方式。
下图介绍了Encoder Only | Decoder Only | Encoder+Decoder三种技术路线的模型的发展趋势,可以很明显看出越往后推出的模型,呈现出其性能越高,其参数量越大的规律,这就是我们常提到Scale Law。
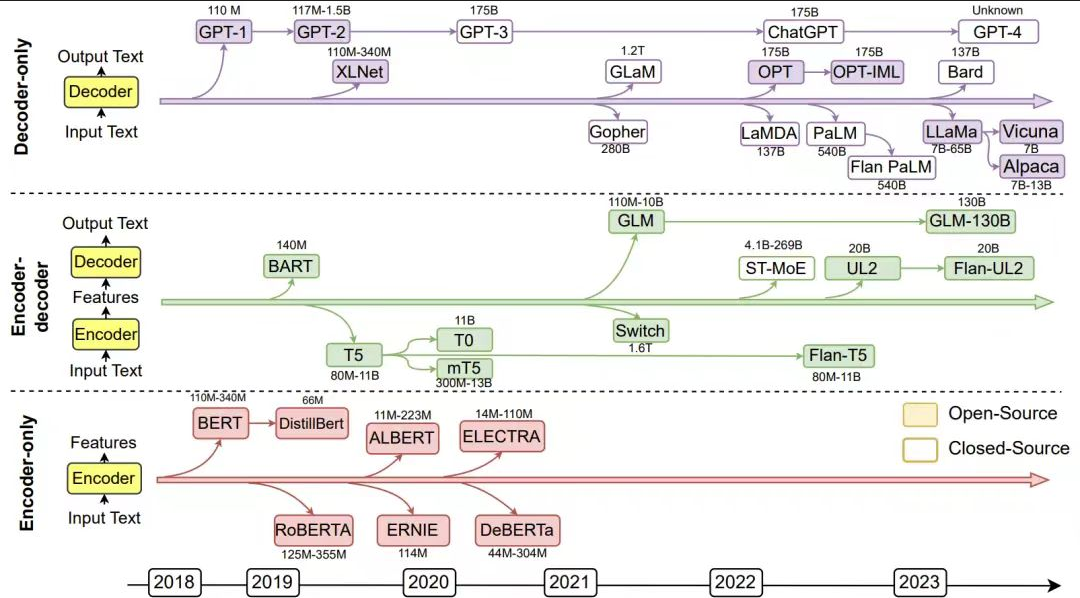
接下来我们以Encoder Only 的典型代表——Bert,Decoder Only的典型代表——GPT展开作详细讲解。
3.2.1 Bert
BERT (Bidirectional Encoder Representations from Transformers) 是 Google 于 2018 年提出的一种预训练语言模型,它是基于transformers Encoder部分的改良。
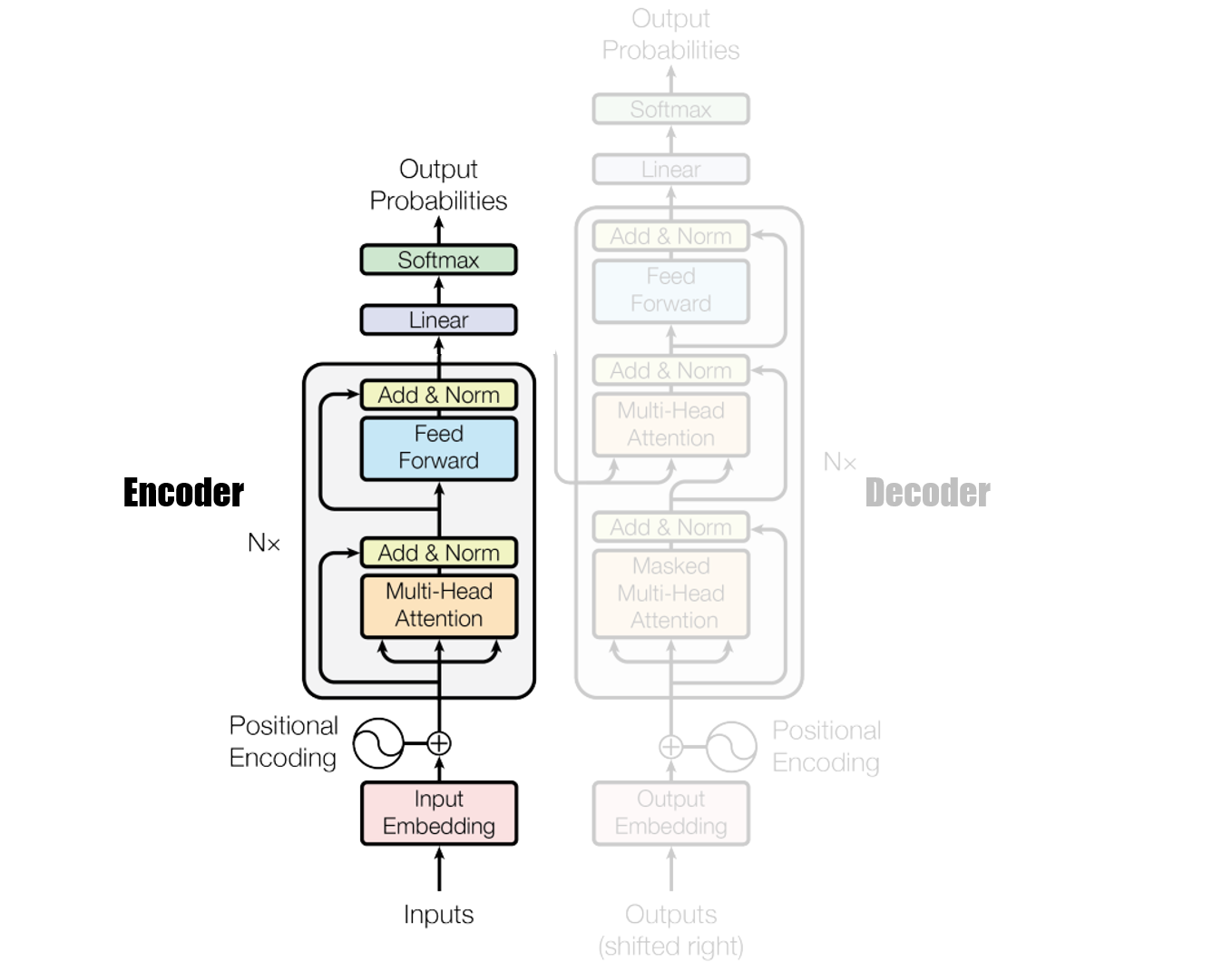
Bert被广泛应用在文本分类、句子对识别、序列标注等任务。它凭借较小的资源占用和较高的稳定性,在NLP领域扮演着不可或缺的角色。
Bert模型的架构
BERT 的核心思想是利用双向 Transformer 编码器进行无监督预训练,从而学习到丰富的上下文相关的词嵌入表示。宏观上BERT分三个主要模块。
- 最底层黄色标记的Embedding模块。
- 中间层蓝色标记的Transformer 的 encoder模块。
- 最上层绿色标记的预微调模块。
如何训练BERT
Bert训练使用了132GB的数据(33亿图书馆+百科词汇语料),由谷歌团队用16个TPU,4天时间训练完成。并同时应用了以下两个训练任务:
- 掩码语言模型 (Masked Language Model, MLM): 随机掩盖 (mask) 输入句子中的部分词(使用特殊标记 [MASK] 替换),然后训练模型根据上下文预测这些被掩盖的词。这使得 BERT 能够学习到双向的上下文表示。为了提高效率,BERT只预测被遮盖的单词,而不是重建整个输入。
- 遮盖策略:
- 80% 的概率用
[MASK]标记替换。- 10% 的概率用一个随机的单词替换。
- 10% 的概率保持原单词不变。
- 为什么要这样设计呢?如果100%都用[MASK]替换,模型就只学会了预测[MASK],如果只替换不mask,模型直接复制就行,为了防止模型学到捷径,同时引入其他词带来的噪音,所以混合了这几种策略。
- 下一句预测 (Next Sentence Prediction, NSP): 判断两个句子是否是连续的句子。输入是一对句子 A 和 B,模型需要预测 B 是否是 A 的下一句。这个任务有助于 BERT 学习句子之间的关系。
BERT模型参数
BERT提供了简单和复杂两类模型,对应的超参数分别如下:
BERT-base : L=12,H=768,A=12,参数总量110M;
BERT-large: L=24,H=1024,A=16,参数总量340M;
在上面的超参数中,L表示网络的层数(即Transformer blocks的数量),A表示Multi-Head Attention中self-Attention的数量。
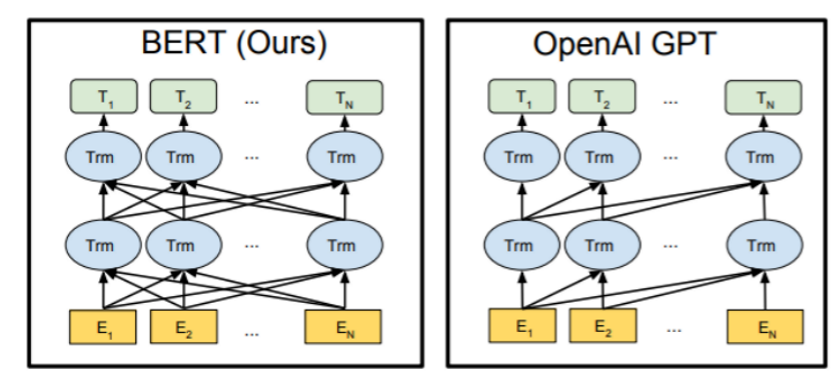
3.2.2 GPT
2018 年 6 月, OpenAI 发布题为 "Improving Language Understanding by Generative Pre-Training"的论文,标志着 GPT 系列模型的开端。
GPT采用的是Decoder only的架构,即transformers架构的右半部分。GPT的核心任务是NWP(Next word prediction),即通过自回归生成的方式,依次预测下一个词,直至生成完整的句子或段落。
下图以“robot must obey orders”这句话为例,演示了如何通过倒三角掩码的方式构建自回归训练任务。

GPT的训练流程
- 预训练 (Pre-training)
- 目标: 让模型学习通用的语言表示,捕捉语言的统计规律、语法结构、语义关系以及一些常识知识等。
- 数据集: 这个阶段使用的数据集非常庞大,通常包括互联网上的各种文本,例如网页、书籍、新闻文章、维基百科等等。例如,GPT-3.5 的训练数据量达到了 45TB。
- 训练方法: 在海量文本数据集上进行无监督学习 (Unsupervised Learning),通常使用自回归语言模型 (Autoregressive Language Modeling) 作为训练目标。需要数千个GPU进行数月的大规模分布式训练,95%的训练成本都用在这个阶段。
- 结果: 预训练阶段得到的模型具有很强的通用性,可以理解和生成各种类型的文本,但它还没有针对特定任务进行优化。
- 微调 (Fine-tuning)
- 目标: 将预训练模型适配到具体的下游任务,例如问答、翻译、摘要生成等等。
- 数据集:由承包商编写的理想助手响应(包括提示和响应对),数量在1万到10万对之间,质量较高。
- 方法: 在特定任务的标注数据集上进行监督学习 (Supervised Learning)。需要1到100个GPU,训练时间为数天。
- 过程: 将预训练模型的参数作为初始值,并在标注数据集上进行进一步的训练。
- 结果: 经过微调的模型在特定任务上的表现会得到显著提升。
- 基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF)
- 目标: 进一步提升模型的生成质量,使其生成的内容更符合人类的偏好,例如更加有用、真实、无害。
- 数据集:构建人类偏好数据集,由承包商编写的比较数据,数量在10万到100万之间,质量较高
- 训练方法:从SFT模型初始化并使用奖励模型,需要1到100个GPU,训练时间为数天。
- 这个阶段通常包含三个步骤:
- 监督微调 (Supervised Fine-tuning, SFT): 使用人工标注的数据进一步微调模型,例如让人类标注员编写高质量的回复。
- 训练奖励模型 (Reward Model, RM): 使用人工标注的偏好数据训练一个奖励模型。例如,对于同一个问题,人类标注员会对模型的多个回复进行排序,然后训练一个模型来预测人类的排序。
- 使用强化学习 (例如 PPO 算法) 优化策略: 使用奖励模型作为反馈信号,通过强化学习算法优化模型的策略,使其生成的内容获得更高的奖励。
结果: 经过 RLHF 训练的模型,其生成的内容通常更符合人类的期望,更加安全可靠。
3.3 预训练语言模型示例-基于bert微调解决情绪识别问题
C_Bert\Bert_model.py
使用torch库构建数据预处理类
- 三个基础方法
搭建模型架构:BertClassifier类
- 一个继承
- 两个方法
模型训练和评估函数函数
C_Bert\Bert_main.py
- 数据加载处理
- 构建词表与标签映射
- 创建数据集实例
- 创建数据加载器
- 初始化模型
- 定义损失函数和优化器
- 训练模型
- 评估模型
C_Bert\Bert_infer.py
模型加载与推理
三类模型在情绪识别任务的特点总结
| 类型 | 传统机器学习——Random Forest | 深度学习——LSTM | 预训练语言模型——BERT |
|---|---|---|---|
| 数据处理 | 依赖特征工程(TF-IDF) | 自动从数据中提取特征 | 自动从数据中提取特征 |
| 算法 | 决策树 | 神经网络 | Transforers |
| 数据 | 数据量适中时效果良好 | 需要大量数据才能表现出色 | 微调时少量数据即可取得不错效果 |
| 算力 | 对计算资源要求较低 | 需要强大的硬件支持(GPU/TPU 等) | 需要强大的硬件支持(GPU/TPU 等) |
| 准确率 | 75% | 84% | 91% |
大语言模型的工程化应用
1. RAG
RAG:检索增强生成(Retrieval Augmented Generation, RAG)。它将传统信息检索系统(例如数据库)的优势与生成式大语言模型 (LLM) 的功能结合在一起。 数据搜索+大模型。
1.1 RAG要解决的问题:
- 模型的知识量不足问题
- 幻觉问题
- 模型数据不能实时更新问题等等
1.2 RAG一般实现流程:
- 创建数据库: 会先将相关文档分块,为这些块生成嵌入向量,并存储到向量库中。
- 输入: 用户输入。
- 检索: 输入对话生成嵌入向量,通过向量相似查询,找到相关的文档。
- 生成: 将找到的相关文档与原始输入结合,然后传递给模型进行回应生成,最终形成系统对用户的回答。
设计到的技术:
embedding模型:文本转化成向量表示,语义越相似生成的向量越接近。(一种基于transformer的结构。)
向量数据库:向量的相似度匹配。(索引优化。请求向量对比数据库中所有向量效率太低。)
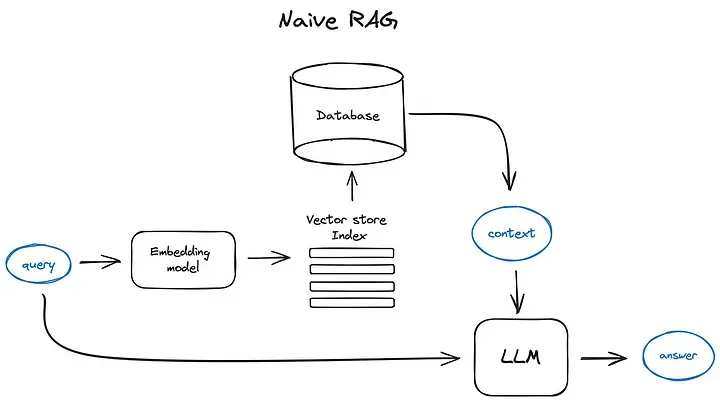
1.3 简单RAG实现
1 | |
1.4 高级RAG
问题:
- 用户输入的表达和知识库的表达差异大。
- 检索到的内容不完整。
- 文档向量匹配不准确。
- 检索到相关性低的文档。
- 检索没有结合用户的对话历史。
- 用户输入检索到无关的知识库。
- 检索结果内容太多。
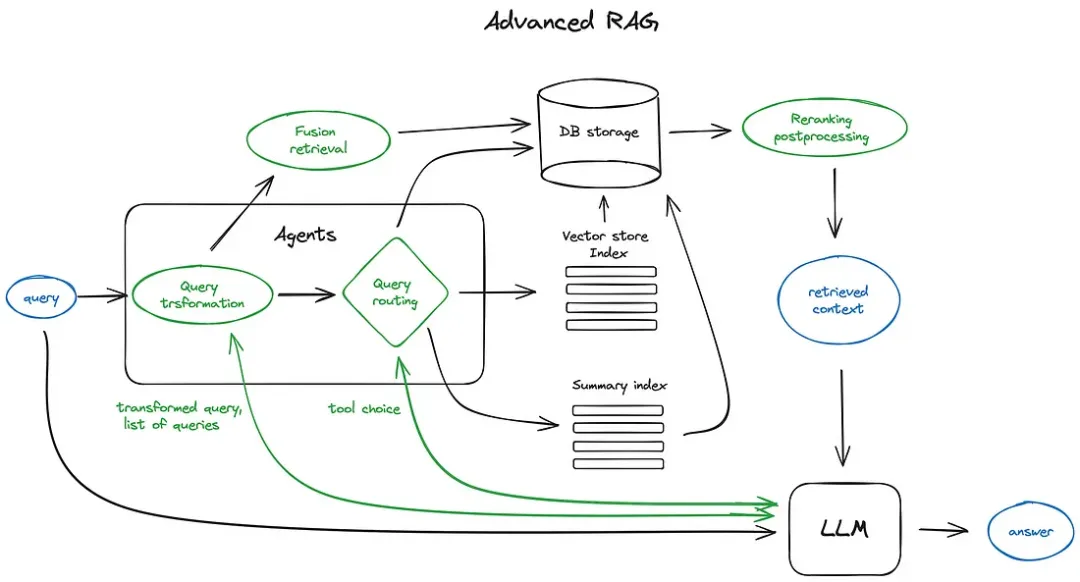
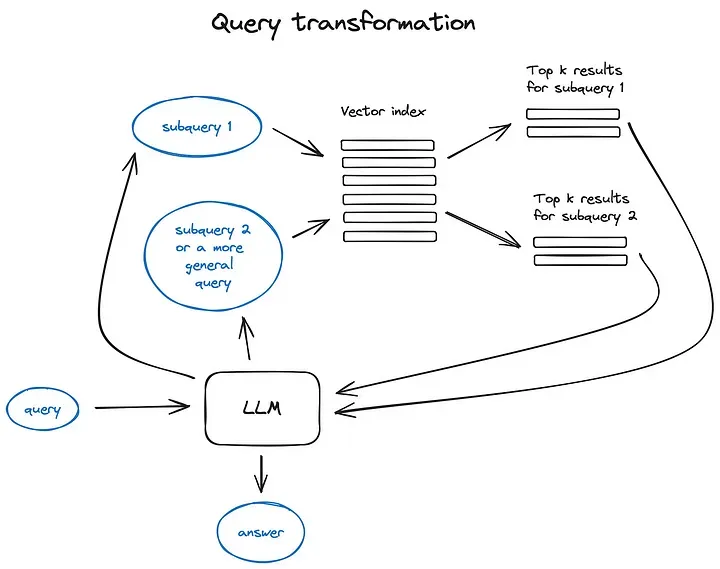
对齐查询和文档(1)
查询转换,利用LLMs生成多条类似的查询(新的查询更符合文档表达形式)。然后多条查询分别检索相关记录。
上下文增强(2)
一是通过在检索到的较小块周围添加句子来扩展上下文,
为了更好地推理分析找到的上下文,我们会在检索到的关键句子前后各扩展k个句子,然后将这个扩展的上下文发送给LLM。
二是递归地将文档分割成多个包含较小子块的大型父块。
在检索过程中,我们会检索出k个叶子块。如果存在n个块都指向同一个更大的父块,那么我们就用这个父块来替换这些子块,并将其送入大语言模型(LLM)用于生成答案。
混合搜索(3)
结合了两种不同的搜索方法:一种是基于关键词的传统搜索方法,另一种是现代的语义或向量搜索。这两种方法被融合在一起,以产生一个综合的检索结果。
假设性问题(3)
让LLM为每个块生成一个假设性问题,并将这些问题以向量形式嵌入。针对假设的问题向量的索引进行查询搜索(用问题向量替换我们索引中的块向量),检索后将原始文本块作为上下文发送给LLM以获取答案。
重新排名和过滤(4)
得到了检索结果,接下来需要通过过滤、重新排名或进行一些转换来进一步优化这些结果。使用reranker模型或者llm
对话历史(5)
结合用户前几轮的对话历史进行检索。将当前的问题结合对话历史,利用LLM生成新的问题,使用新问题进行检索。
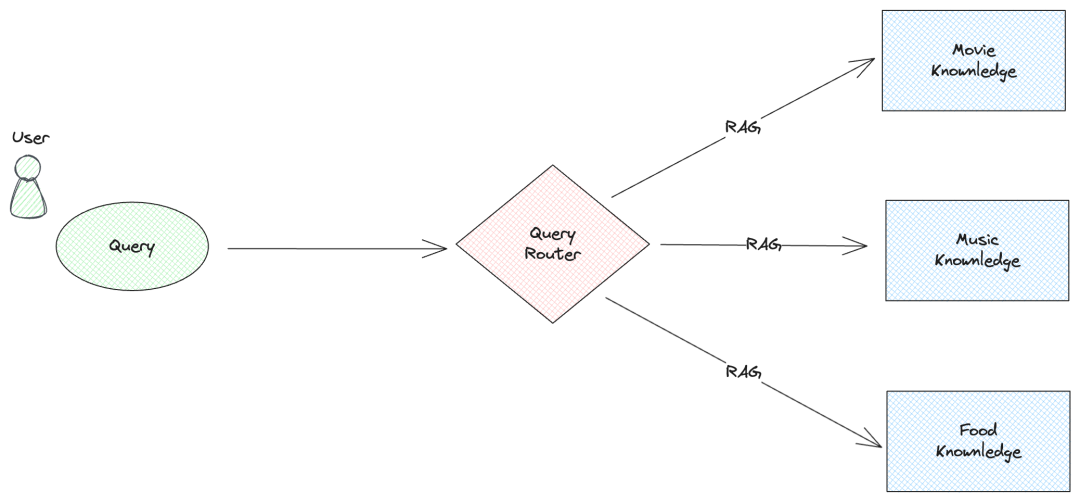
查询路由(6)
用户输入,LLM判断用户意图,将查询路由的相关的数据库。
响应合成器(7)
RAG最后一步 —— 基于检索的上下文和用户的查询来生成答案。
- 将检索到的上下文分块后逐次发送给大语言模型(LLM),以此迭代地精炼答案。
- 总结检索到的上下文,使其适应输入提示。
- 基于不同上下文块生成多个答案,然后将这些答案连接或总结起来。
2. Agent
大模型Agent:一种构建于大型语言模型(LLM)之上的智能体,它具备环境感知能力、自主理解、决策制定及执行行动的能力。
RAG:主要做大模型知识补充。
Agent:一套智能系统。解决自主处理问题的方案。
2.1 ReAct实现Agent
ReAct一种提示词范式,推理过程包含thought-action-observation步骤。
提示词:
1 | |
核心代码:
1 | |
2.2 Agent结构
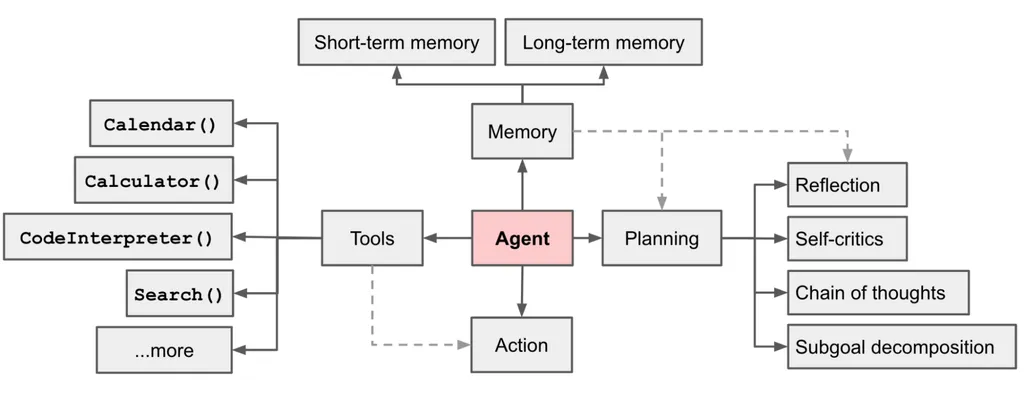
- 规划(Planning):
定义:规划是Agent的思维模型,负责拆解复杂任务为可执行的子任务,并评估执行策略。
实现方式:通过大模型提示工程(如ReAct、CoT推理模式)实现,使Agent能够精准拆解任务,分步解决。
- 记忆(Memory):
定义:记忆即信息存储与回忆,包括短期记忆和长期记忆。
实现方式:短期记忆存储在会话上下文中,支持多轮对话;长期记忆可以通过RAG实现存储和查询。
- 工具(Tools):
定义:工具是Agent感知环境、执行决策的辅助手段,如API调用、插件扩展等。
实现方式:通过接入外部工具(如API、插件)扩展Agent的能力,如ChatPDF解析文档、Midjourney文生图等。
- 行动(Action):
定义:行动是Agent将规划与记忆转化为具体输出的过程,包括与外部环境的互动或工具调用。
实现方式:函数调用,模型做出规划并选择可使用的函数,给出函数调用的参数。
Agent:P(感知)→ P(规划)→ A(行动)
小节
- Agent很适合做一个智能npc。
- 上面是单一的Agent,可以处理某类任务。
- 更复杂的任务可以设计多Agent模式,将多个单一的Agent有机结合起来。
- 还可以通过工作流实现Agent,通过预定义的代码路径对LLM和工具进行编排。
总结
回顾一下
- 机器学习的概念和随机森林算法做情绪识别。
问题:对数据特征的依赖程度很高,数据处理复杂。模型表现能力弱。等
- 深度学习的神经网络原理和LSTM做情绪识别。
问题:深度学习解决了很多问题,但是始终没有很好解决自然语言处理问题。
- transformer模型的结构,bert和gpt模型的训练和微调,bert微调做情绪识别。
问题:大模型知识不足,不新,幻觉等问题
- RAG的实现流程和高级RAG的优化
问题:不够智能
- Agent的ReAct版实现和基本结构
问题:算力消耗大,延迟高
AI应用
AI不只是大语言模型LLM。除了生成文本,生成图片,生成视频的模型,huggingface有很多常用的各任务类型模型图像识别,语音识别,视频文本分类等等。
大模型的应用技术总体分两种:微调 & 提示词工程(rag,agent)。一般不从零训练。特定的任务训练一个参数量小的网络模型,强化学习非常适合游戏方向的训练。
游戏AI
AI 对话,AI 内容生成,AI NPC,AI 游戏内容搜索,AI 策略决策 等等。
有伙伴有什么想法可以一起研究一下。