RAG效果评估
随着 LLM(Large Language Model)的应用逐渐普及,人们对 RAG(Retrieval Augmented Generation)场景的关注也越来越多。然而,如何定量评估 RAG 应用的质量一直以来都是一个前沿课题。
很显然,简单的几个例子的对比,并不能准确地衡量出 RAG 应用的整体的回答的好坏,必须采用一些有说服力的指标,定量地、可复现地、来评估一个 RAG 应用。目前,业内已经形成一些主流的方法论,并出现了一些用于评估 RAG 应用的专业工具或服务,用户可以用它们快速进行定量评估。
今天我们就带大家来盘一盘自动化评估 RAG 应用的常用方法论以及比较典型的评估工具对比。
01. 方法论
想要自动化定量评估 RAG 应用,并不是一个容易的事。很有可能会遇到一些常见的问题,比如,用什么指标评估 RAG?怎么样才有说服力?用什么数据集来评估?为此,我们将从“评估指标”“基于 LLM 定量评估”这两个角度来回答和阐述这些问题。
角度一:评估指标
- RAG 三元组——无需 ground-truth 也能做评估
如果我们拿到一些知识文档,对于每个 query 提问,没有对应的 ground-truth,可以评估这个 RAG 应用吗?
答案是可以,而且这种方法还挺常见。我们首先引用 TruLens-Eval(https://www.trulens.org/trulens_eval/install/) 里的一个概念,RAG 三元组(RAG Triad)来说明这个问题:
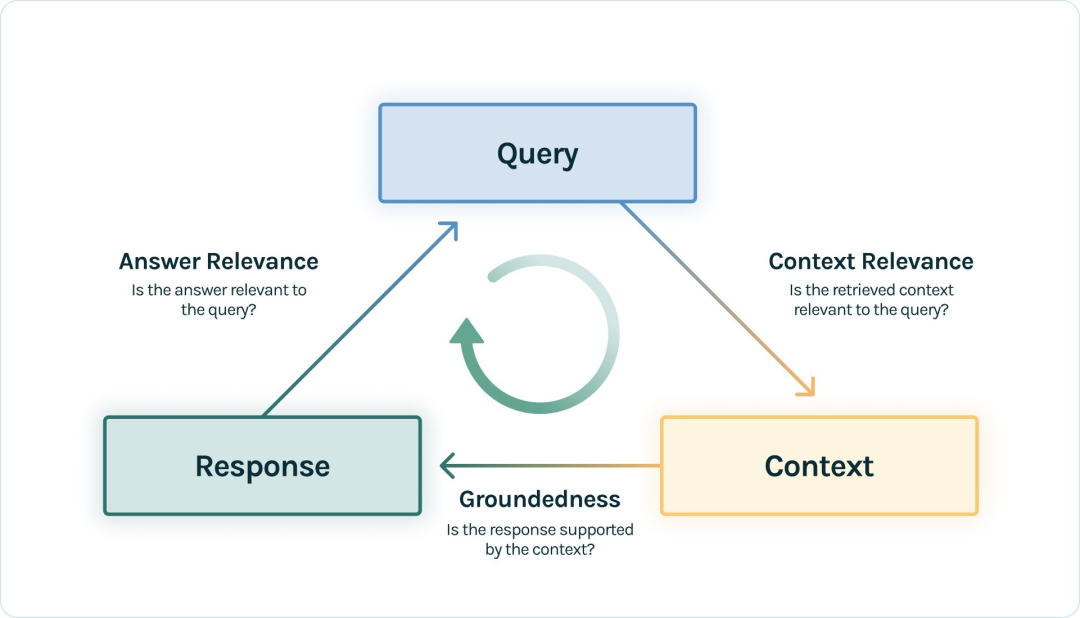
a.RAG 三元组
标准的 RAG 流程就是用户提出 Query 问题,RAG 应用去召回 Context,然后 LLM 将 Context 组装,生成满足 Query 的 Response 回答。那么在这里出现的三元组:—— Query、Context 和 Response 就是 RAG 整个过程中最重要的三元组,它们之间两两相互牵制。我们可以通过检测三元组之间两两元素的相关度,来评估这个 RAG 应用的效果:
- Context Relevance: 衡量召回的 Context 能够支持 Query 的程度。如果该得分低,反应出了召回了太多与Query 问题无关的内容,这些错误的召回知识会对 LLM 的最终回答造成一定影响。
- Groundedness: 衡量 LLM 的 Response 遵从召回的 Context 的程度。如果该得分低,反应出了 LLM 的回答不遵从召回的知识,那么回答出现幻觉的可能就越大。
- Answer Relevance: 衡量最终的 Response 回答对 Query 提问的相关度。如果该得分低,反应出了可能答不对题。
以 Answer Relevance 为例:
1 | |
因此,对于一个 RAG 系统来说,最基本的就是三元组指标得分,它反映了 RAG 效果的核心部分,整个过程中并不需要 ground-truth 的参与。
当然,具体怎么衡量这三个得分,也有不同的方式。最常见的就是基于目前最好的 LLM(如 GPT-4)做为一个裁判,给输入的这一对元组打分,判断它们的相似度,具体的例子将在后面介绍。
另外,三元指标其中的某个可能还有具体的一些细分,比如 Ragas(https://docs.ragas.io/en/latest/concepts/metrics/context_recall.html)中就将 Context Relevance 这一步又分为Context Precision、Context Relevancy、Context Recall。或者,一些工具中不一定是这三个名字,比如Groundedness 在有的工具中叫作 Faithfulness。
b. 基于 Ground-truth 的指标
- Ground-truth 是回答
当一个数据集已经标注好了ground-truth 回答,那就可以直接比较 RAG 应用的回答和 ground-truth 之间的相关性,来端到端地进行衡量。这种方法很直观也很容易想到,比如 Ragas 中相关的指标就有:Answer semantic similarity 和 Answer Correctness。
以 Answer Correctness 为例:
1 | |
具体怎么衡量相似性或相关性,可以用直接向 GPT-4 进行提示词工程打分,或用一些比较好的 embedding 模型来进行相似性打分。
- Ground-truth 是知识文档中的 chunks
常见的数据集中并没有回答的 ground-truth,而更多的情况是,数据集有 query 提问,和对应的文档内容中的 ground-truth doc chunks。这种情况下需要衡量的就是上文 RAG 三元组指标中的 Context Relevance,也就是对比 ground-truth doc chunks 和召回的 contexts 之间的相关性,这一步因为没有 LLM 生成的情况出现,对比的是相对固定的文本,所以在实现上可以使用一些传统的指标,比如 Exact Match (EM)、Rouge-L、F1 等。
其实这种情况下,本质上就是衡量 RAG 应用的召回效果,如果 RAG 应用只使用向量召回而没有用其它的召回方式,那这一步退化等效于衡量 embedding 模型的效果。
- 生成评估数据集
如果我们手头上的知识文档没有 ground-truth,并且只想评估一下 RAG 应用在这些文档上的效果,有办法可以实现吗?
既然 LLM 可以生成一切,那让 LLM 根据知识文档,来生成 query 和 ground-truth,这也是可行的。比如,在 ragas 的 Synthetic Test Data generation(https://docs.ragas.io/en/latest/concepts/testset_generation.html) 和 llama-index 的 QuestionGeneration(https://docs.llamaindex.ai/en/stable/examples/evaluation/QuestionGeneration.html)中都有一些集成好的方法,可以直接方便地使用。
我们来看一下 Ragas 中根据知识文档生成的效果:

可以看到,上图生成了许多 query questions 和对应的 answers,包含对应的 context 出处。为保证生成问题的多样性,还可以选择各种各样的 question_type。这样,我们就可以方便地直接用这些生成的 question 和 ground-truth,去定量评估一个 RAG 应用,无需去网上找各种各样的 baseline 数据集。
c. LLM 回答本身的指标
这一类的指标就是单从 LLM 的回答本身来看的,比如评估回答本身是否友好,是否有害,是否简洁等,它们参考来源的是 LLM 本身的一些评估指标。
比如 Langchain 的 Criteria Evaluation(https://python.langchain.com/docs/guides/evaluation/string/criteria_eval_chain),包括:
1 | |
比如 Ragas 中的 Aspect Critique(https://docs.ragas.io/en/latest/concepts/metrics/critique.html)包含:
1 | |
以 Conciseness 举例:
1 | |
角度二:基于 LLM 的定量评估
上文提到的大部分指标,都需要输入一些文字,然后期望得到一个定量的得分。这在以往是不太容易实现的,有了 GPT-4 后,其可行性就提高了。我们只需设计好 prompt,将要打分的一些文字放入 prompt,访问GPT-4,就可以得到一个想要的得分结果。
举个例子,在 LLM-as-a-judge(https://arxiv.org/abs/2306.05685)这篇论文中,提到的一个 prompt 设计如下:

可以看到,这段 prompt 设计的目的就是让 LLM 对一个 question 的 answer 进行打分,要考虑多方面的因素,得分在 1 到 10 之间。
那么,GPT-4,或者 LLM 本身做为一个裁判打分,它就不会有错吗?
根据我们目前的观察,GPT-4 这在方面做得已经很好了。人类都有可能打错分,GPT-4 的表现和人类类似,误判的比例保持在很低就可以保证这种方法的有效性。因此,如何设计 prompt 同样重要,这就要用到一些高级的 prompt 工程技巧,比如 multi-shot,或 CoT(Chain-of-Thought)思维链技巧。在设计这些 prompt 时,有时还要考虑 LLM 的一些偏见,比如 LLM 常见的位置偏见:当 prompt 比较长时,LLM 容易注意到 prompt 里前面的一些内容,而忽略一些中间位置的内容。
好在这些 prompt 的设计已经被设计和集成在 RAG 应用的评估工具中,我们的关注点可以放在其他地方,例如,大量访问 GPT-4 这种 LLM 需要消耗大量的 API key,加下来期待有更便宜的 LLM 或本地 LLM,能够达到“当好一个裁判”的水平。
02. 各类评估工具
接下来我们来介绍一下目前比较常见、好用的 RAG 评估工具的基本使用方法及其相应特点。
Ragas
RAG评估时通常会会用到四种数据,分别是用户问题,检索召回的样本,大模型生成答案以及标准答案
该方法有两类四项评估指标:
评估检索质量:
context_relevancy(上下文相关性,检索回的上下文与原始问题之间的相关性,对其中的冗余信息进行惩罚)
- 利用LLM,从给定的context上下文信息中,提取出所有对标准答案直接相关或重要的句子,不改变句子内容。
- 计算有用的内容占全部内容条数的比例
context_recall(召回性,引入标准答案进行判断,重点关注标准答案中提及但检索结果未体现的部分)
- 利用LLM,将标准答案拆分为多个知识点 , 根据每个知识点,查看检索到的条目是否能够找到相应支撑。
- 计算能够找到支撑的知识点占总体知识点的比例
评估生成质量:
faithfulness(忠实性,为生成答案找支撑,惩罚多余的生成)
- 首先使用LLM来根据问题和生成答案提取一组语句S。这一步骤的目的是将较长的句子分解为更短、更集中的断言。
- 针对生成的每个语句s,再次使用大模型或验证函数来判断这个语句是否能用上下文中的信息来支撑。
- 最后根据有支撑内容的占比计算得分
answer_relevancy(答案的相关性,根据潜在问题计算向量相似度)
- 根据最终答案,利用大模型生成针对该问题的多个潜在的问题。
- 针对生成的每个潜在问题,利用embedding模型 来计算与原始问题的向量相似度(余弦距离)
- 最终对所有的向量相似度取平均数。
Ragas(https://docs.ragas.io/en/latest/concepts/metrics/context_recall.html)通过简单的接口即可实现评估:
1 | |
只要把 RAG 过程中的question, contexts,
answer, ground_truths,构建成一个 Dataset
实例,即可一键启动测评,非常方便。
Ragas指标种类丰富多样,对 RAG 应用的框架无要求,也可以通过 langsmith(https://www.langchain.com/langsmith)来监控每次评估的过程,帮助分析每次评估的原因和观察 API key 的消耗。
Llama-Index
Llama-Index(https://docs.llamaindex.ai/en/stable/optimizing/evaluation/evaluation.html)很适合用来搭建 RAG 应用,且它的生态比较丰富,目前也处在快速迭代发展中。Llama-Index 也有一部分评估的功能,用户可以方便地对由 Llama-Index 本身搭建的 RAG 应用进行评估:
1 | |
可以看到,在runner.evaluate_queries()中,需要传入一个BaseQueryEngine实例,也就是说,它比较适合评估
Llama-Index 本身搭建的 RAG 应用。如果是其它架构搭建的 RAG
应用,可能需要在工程上做一些转换。
TruLens-Eval
Trulens-Eval(https://www.trulens.org/trulens_eval/install/)也是专门用于评估 RAG 指标的工具,它对 LangChain 和 Llama-Index 都有比较好的集成,可以方便地用于评估这两个框架搭建的 RAG 应用。我们以评估 LangChain 的 RAG 应用为例:
1 | |
当然,Trulens-Eval 也可以评估原生的 RAG
应用。在代码上会相对复杂一些,需要使用 instrument在RAG
应用代码中注册,具体可以参考官方文档(https://www.trulens.org/trulens_eval/install/)。此外,Trulens-Eval
也可以在浏览器中启动页面进行可视化地监控,帮助分析每次评估的原因和观察
API key 的消耗。
Phoenix
Phoenix(https://docs.arize.com/phoenix/)有许多评估 LLM 的功能,比如评估 Embedding 效果、评估 LLM 本身。在评估 RAG 这个能力上,也留出接口,和生态对接,但目前看指标种类还不是很多。下面是用 Phoenix 评估 Llama-Index 搭建的 RAG 应用例子:
1 | |
当px.launch_app()启动后,在本地可以打开一个网页,可以观察
RAG
应用链路中的每一步的过程。最近评估的结果还是放在retrieved_documents_relevance这里面。
其它
除上面这几个工具之外,DeepEval(https://github.com/confident-ai/deepeval)、LangSmith(https://docs.smith.langchain.com/evaluation/evaluator-implementations)、OpenAI Evals(https://github.com/openai/evals)等工具都集成工评估 RAG 应用的能力,在使用方法和原理上大同小异,感兴趣的朋友可以深入了解。
03. 总结
本文主要复盘了当前比较主流的评估框架和方法论,并介绍了相关工具的使用。因为当前 LLM 的各类应用发展迅速,在评估 RAG 这个赛道上,各种方法和工具如雨后春笋一样不断涌现。
虽然这些方法在大的框架上相似,但在具体实现方面,比如 prompt 的设计,仍处于百花齐放的状态。目前,我们还无法确定会有哪些工具能成为最后的王者,仍需时间的检验。期待在大浪淘沙后,开发者都能够找到最适合自己的工具。