RAG中的rerank技术
[检索增强生成](RAG)是解决大语言模型(LLM)实际使用中的一套完整的技术,它可以有效解决LLM的三个主要问题:[数据时效性]、幻觉和数据安全问题(在我之前的文章《大模型主流应用RAG的介绍——从架构到技术细节》中有详细介绍)。但是随着RAG越来越火热,使用者越来越多,我们也会发现用的好的人/团队其实还是不多的。这也是RAG常被人吐槽的一点:入门简单,用好却非常难!
对于RAG的效果,我们之前已经做了很多方面的优化了,包括:
- 优化内容提取的方法:从源头解决内容提取的有效性,包括文本内容、表格内容(保留制表符)和图片内容(OCR识别)等;
- 优化[chunking]:从最开始的512固定长度切分,到后面的句切分,再到后面的NLTK和[SpaCy];
- 再之后是优化[embedding模型]:Embedding模型的选择其实很魔性,我们在优化过程中也会不断否定之前的一些判断。比如我们最开始用m3e,后面用bge,再后面还用了通义千问的embedding模型。总体来说,收费的通义千问还是好一些,但是不明显,有些方面却不如bge。最近一朋友也向我推荐了Jina embedding模型,不过他们的中文模型需要12月份才出来;
- 我们还优化了其他一些过程:比如[prompt模板]、关键词摘要、元数据存储等。
这些优化确实给我们带来了非常好的效果,但不够!我们在一些客户的实践过程中,还是发现相关性效果不佳,甚至造成了其中一个客户选择了其他方案(使用RAG+GPT-4的方案)。
我们还是坚持用国产大模型(如Baichuan2-13B、ChatGLM3-6B和QWen-14B等),毕竟主要服务的还是国内客户,加上现在接触的多数客户其实都有私有化部署的需求。所以我们进行了一段时间的探索,发现我们还有一项很有效的优化没有去做——[ReRank]。
所以,虽然Rerank优化我们还在做,但是今天我们可以先聊聊ReRank这个话题。
为什么需要Rerank
我们发现,在10月中旬之前,国内外的互联网上很难发现Rerank相关的话题。有少量人提到了,但是基本上都没有提到解决方案。我和小明在讨论Rerank的时候其实是先从提问题开始的。
[Elasticsearch]中的[相似度检索算法]
前面说了,我们自己的RAG产品之前是存在一些相关性问题的,其他方面能优化的我们觉得也基本上优化的差不多了,除了我们采用的国产大模型在通用能力上和ChatGPT-3.5/4是存在差距的。我们发现的最大的问题就是使用[elasticsearch]的retrieval召回的内容相关度有问题,多数情况下score最高的chunk相关度没问题,但是top2-5的相关度就很随机了,这是最影响最终结果的。
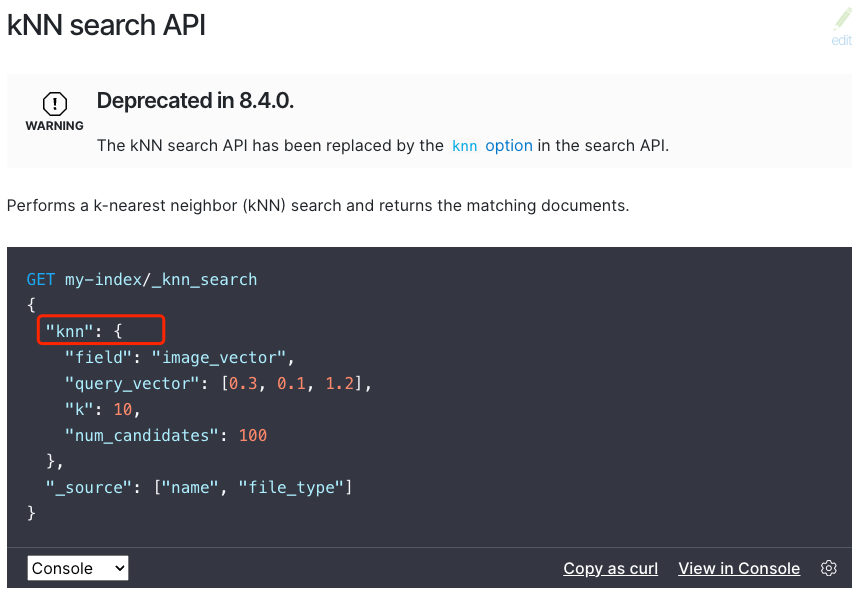
图1:elasticsearch8.4的knn使用方式
我们看了elasticsearch的[相似度算法],es用的是[KNN]算法(开始我们以为是暴力搜索),但仔细看了一下,在es8的相似度检索中,用的其实是基于HNSW(分层的最小世界导航算法),HNSW是有能力在几毫秒内从数百万个数据点中找到最近邻的。
图2:elasticsearch实际使用的是HNSW算法
HNSW带来的随机性问题
我们想象这么一个场景:你昨天刚在其他地方看到过一本新书,你想在图书馆找到类似的书。K-最近邻(KNN)算法的逻辑是浏览书架上的每一本书,并将它们从最相似到最不相似的顺序排列,以确定最相似的书(最有可能是你昨天看过的那本)。这也就是我们常说的暴力搜索,你有耐心做这么麻烦的工作吗?相反,如果我们对图书馆中的图书进行预排序和索引,要找到与你昨天看过的新书相似的书,你所需要做的就是去正确的楼层,正确的区域,正确的通道找到相似的书。
此外,你通常不需要对前10本相似的书进行精确排名,比如100%、99%或95%的匹配度,而是通通先拿回来。这就是近似近邻(ANN)的思想。你应该注意到了,这里已经出现了一些随机性——不做匹配分数的排名。但是这些准确度上的损失是为了让检索效率更快,为了显著降低计算成本,它牺牲了找到[绝对最近邻]的保证,这算是在计算效率和准确性之间取得平衡。
[ANN算法]目前主要有三种:
- 基于图的算法创建数据的图表示,最主要的就是分层可导航小世界图算法(HNSW)。
- 基于哈希的算法:流行的算法包括:位置敏感哈希(LSH)、[多索引哈希(MIH)];
- 基于树的算法:流行的是kd树、[球树]和随机投影树(RP树)。对于低维空间(≤10),基于树的算法是非常有效的。
HNSW借鉴了跳表(Skip List)的思路。[跳表]是一种数据结构,用于维护一组已排序的元素,并允许进行高效的搜索、插入和删除操作。它是由[William Pugh]在1989年发明的。图(3)显示了数字[3、6、7、9、12、17、19、21、25、26]的[排序链表]。假设我们想找到目标19。当值小于目标时,我们向右移动,如果是传统的方式,需要6步才能找到它。

图3:链表中查找数据
但是我们在每个节点增加向后的[指向指针],比如列表中每三个其他节点都有一个指向后面三个节点的指针,如图(4)所示,那么只需要3步就可以到达19

图4:跳表每三个节点就设置一个多指向指针节点,可以让搜索速度明显加快,如果我们再增加这个指针节点数量呢?
这就是[small world]的底层思路,说回到小世界(small world)网络,它是一种特殊的网络,在这种网络中,你可以快速地联系到网络中的其他人或点。这有点像“[凯文·培根]的六度”(Six Degrees of Kevin Bacon)游戏,在这个游戏中,你可以通过一系列其他演员,在不到六个步骤的时间里,将任何演员与凯文·培根联系起来。想象一下,你有一群朋友排成一个圆圈,如图5所示。每个朋友都与坐在他们旁边的人直接相连。我们称它为“原始圆”。
现在,这就是奇迹发生的地方。你可以随机选择将其中一些连接改变给圆圈中的其他人,就像图5中的红色连接线一样。这就像这些连接的“抢椅子”游戏。有人跳到另一把椅子上的几率用概率p表示。如果p很小,移动的人就不多,网络看起来就很像原来的圆圈。但如果p很大,很多人就会跳来跳去,网络就会变得有点混乱。当您选择正确的p值时,红色连接是最优的。网络变成了一个[小世界网络]。你可以很快地从一个朋友转到另一个朋友(这就是“小世界”的特点)。

图5:small world网络结构
现在我们要扩展到高维空间,图中的每个节点都是一个高维向量。在高维空间中,搜索速度会变慢。这是不可避免的“维度的诅咒”。HNSW是一种[高级数据结构],用于优化高维空间中的相似性搜索。让我们看看HNSW如何构建图的[层次结构]。HNSW从图(6)中的第0层这样的基础图开始。它通常使用[随机初始化数据点]来构建。
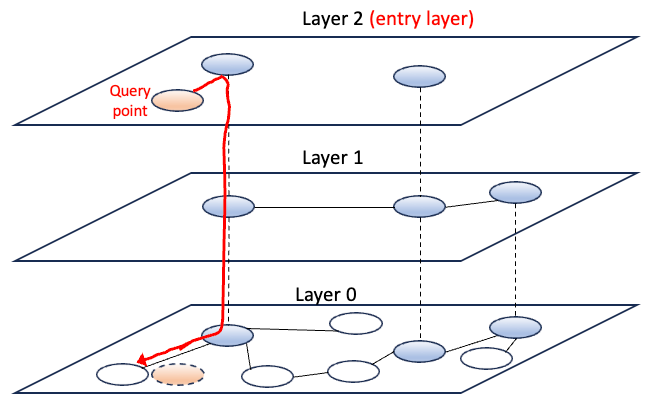
图6:HNSW的结构示例
这里大家要注意再次出现了”随机“,所以,为了检索的快速,HNSW算法会存在一些随机性,反映在实际召回结果中,最大的影响就是返回结果中top_K并不是我们最想要的,至少这K个文件的排名并不是我们认为的从高分到低分排序的。
Rerank可以在小范围内逐一计算分值
因为在搜索的时候存在随机性,这应该就是我们在RAG中第一次召回的结果往往不太满意的原因。但是这也没办法,如果你的索引有数百万甚至千万的级别,那你只能牺牲一些精确度,换回时间。这时候我们可以做的就是增加top_k的大小,比如从原来的10个,增加到30个。然后再使用更精确的算法来做rerank,使用一一计算打分的方式,做好排序。比如30次的[遍历相似度]计算的时间,我们还是可以接受的。
关于HNSW的内容,大家可以查看像光速一样搜索——HNSW算法介绍。
主要的Reank方式评测
评测方法
为了衡量我们的检索系统的有效性,我们主要依赖于两个被广泛接受的指标:命中率和平均倒数排名(MRR)。让我们深入研究这些指标,了解它们的重要性以及它们是如何运作的。我们来解释一下这两个指标:
- 命中率:Hit rate计算在前k个检索文档中找到正确答案的查询比例。简单来说,它是关于我们的系统在前几次猜测中正确的频率。
- 平均倒数排名(MRR):对于每个查询,MRR通过查看排名最高的相关文档的排名来评估系统的准确性。具体来说,它是所有查询中这些秩的倒数的平均值。因此,如果第一个相关文档是顶部结果,则倒数排名为1;如果是第二个,倒数是1/2,以此类推。
评测结果
具体的评测过程大家可以看提升RAG——选择最佳Embedding和重新排名模型,也是llamaindex最近刚刚发布的一篇著名rerank评测文章,我这里就不具体展开了,直接用他们的结果。评测采用的是embedding模型 + [rerank模型]的方式进行的。
以下是使用的模型:
Embedding模型:
[Rerank模型]:
值得一提的是,这些结果为这个特定数据集和任务的性能提供了坚实的见解。但是,实际结果可能会根据数据特征、数据集大小和其他变量(如[chunk_size]、similarity_top_k等)而有所不同。
下表展示了基于命中率和MRR指标的评估结果:
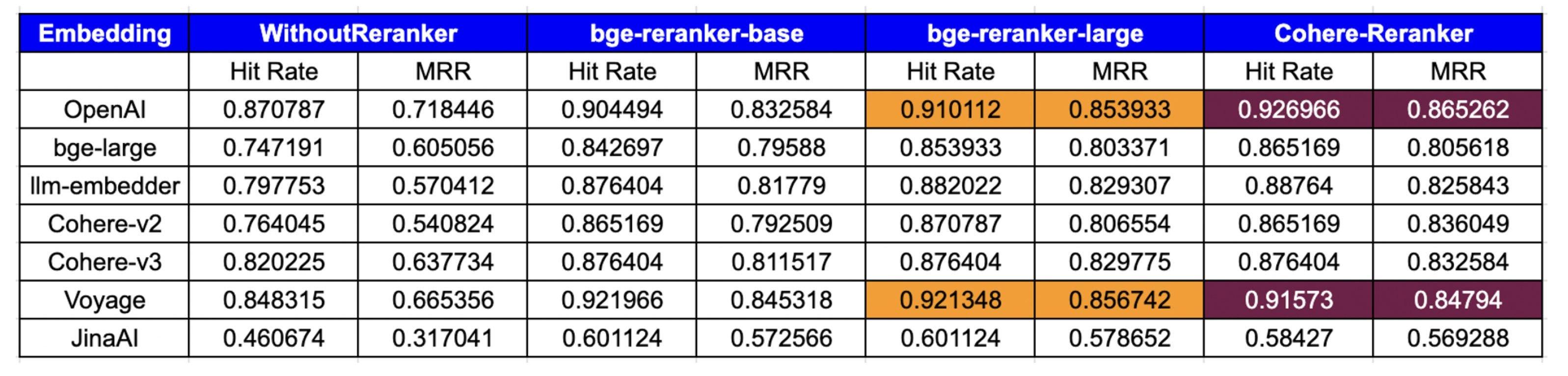
图7:测试结果
我对[LlamaIndex]的评测结果做一个简单总结:
- 目前rerank模型里面,最好的应该是cohere,不过它是收费的。开源的是智源发布的bge-reranker-base和bge-reranker-large。bge-reranker-large的能力基本上接近cohere,而且在一些方面还更好;
- 几乎所有的Embeddings都在重排之后显示出更高的命中率和MRR,所以rerank的效果是非常显著的;
- embedding模型和rerank模型的组合也会有影响,可能需要开发者在实际过程中去调测最佳组合。
我们可以如何使用Rerank
目前最无脑的方式就是使用bge-reranker-large,我们可以在https://huggingface.co/BAAI/bge-reranker-large/tree/main上找到models文件,下载安装。我已经下载了:
图8:bge-reranker-large的models文件,大约4.5GB
这两天要给它安装起来,测测我们的产品rerank之后的效果。
其实还有一种比较简单的方式,这种方式其实是从上面的原理中得出来的:
- 第一次召回不精确,是因为要对抗时间过长,所以使用了ANN等方法;
- 那么,我们是否可以在已经得到top_k的情况下,使用KNN这种暴力检索(逐个计算相似度,打分)来做一个精准排序,然后取top_n。假设这里k=30,n=5.