集成学习常见模型比对
集成学习的基础思想是通过组合多个基学习器形成整体强学习器,使基学习器在预测准确性、降低过拟合风险、增强模型的鲁棒性等方面获得明显提升,集成学习主要包含Bagging和Boosting两大分类。本文对比总结了四种集成学习常见模型。
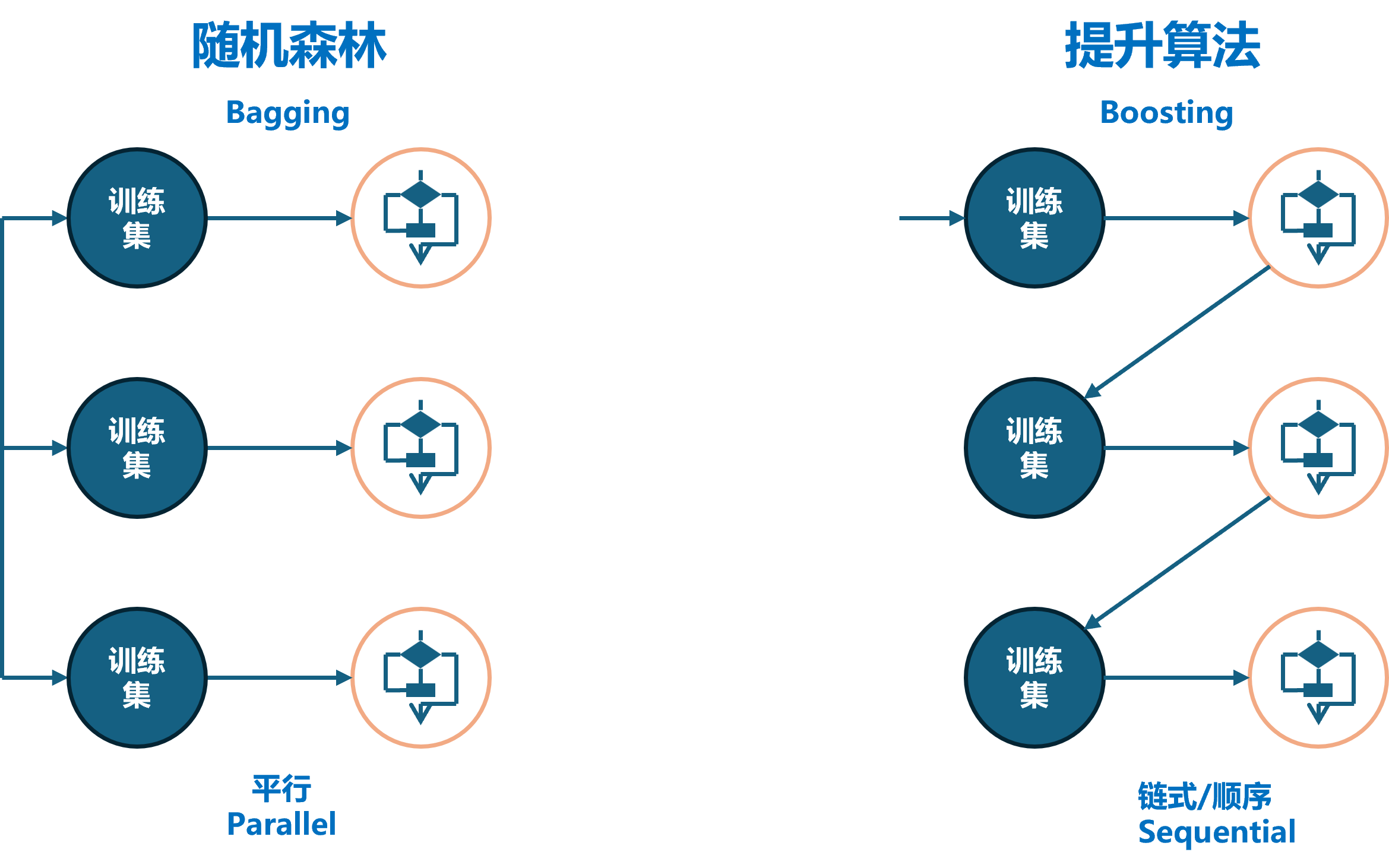
Bagging是一种并行式的集成学习方法,其特点包括通过有放回的抽样产生不同的训练集,从而训练多个不同的学习器,并通过平均投票或多数表决的方式决定预测结果。此外,Bagging允许弱学习器并行训练,代表算法包括随机森林算法。
Boosting是一种串行式的集成学习方法,其特点是随着学习的积累从弱到强,每加入一个弱学习器,整体能力会得到提升。Boosting对学习器进行加权投票,采用串行方式进行学习,具有明确的先后顺序。代表算法包括Adaboost、GBDT、XGBoost以及LightGBM。
| 模型 | 核心要点 | 模型优缺点 | 模型应用 |
|---|---|---|---|
| Bagging随机森林 | 1. 随机有放回的抽样产生不同的训练集(boostrap) 2. 基于不同抽样训练多个基学习器(如决策树) 3. 通过投票或平均组合预测结果 |
优点: - 泛化错误率低 - 易于并行训练 缺点: -性能上限低 |
1. 分类问题 2. 回归问题 |
| Adaptive Boosting | 1. 迭代构建弱学习器 2. 聚焦错误样本,每轮根据分类结果调整样本及模型权重 3. 组合加权弱学习器成强学习器 |
优点: - 泛化能力强 - 易于处理多种数据 缺点: - 对离群点敏感 - 需要预处理高维或不平衡数据 |
1. 分类问题 2. 图像识别 |
| GBDT (梯度提升树) | 1. 迭代构建决策树 2. 拟合损失函数的负梯度训练新树 3. 累加方式构建最终模型 |
优点: - 准确性高 - 可以适应多种损失函数 缺点: - 容易过拟合 - 计算量大 |
1. 回归问题 2. 排名问题 3. 分类问题 |
| XGBoost | 1. 基于GBDT的高效实现 2. 加入正则化项解决GBDT过拟合问题 3. 损失函数泰勒二阶近似优化拟合函数 4.支持并行化和缺失值处理 |
优点: - 速度快 - 准确性高,防止过拟合 - 支持多种目标函数和评估指标 缺点: - 参数调整复杂 - 可能需要更多的内存 |
1. 赢取竞赛的首选算法 2. 排名问题 3. 分类和回归问题 |
集成学习常见模型比对
https://linxkon.github.io/机器学习要点对比.html