DeepSeek-V3技术报告 近年来,LLM 经历了快速迭代和演进,逐步缩小了与通用人工智能(AGI)的差距。除了闭源模型外,开源模型阵营也在取得重大进展,包括 DeepSeek 系列、LLaMA 系列、Qwen 系列和 Mistral 系列,这些模型正在努力缩小与闭源模型的性能差距。 为了进一步突破开源模型的能力边界,研究团队开发了 DeepSeek-V3,这是一个基于 MoE 架构的大模型,总参数量达到 671B 2025-02-06 categories #LLM #论文精读
如何使用UV管理python环境 UV 是一个快速的 Python 包管理器,它比 pip 和 venv 更高效,适用于 Python 环境管理。 2025-01-20 categories #笔记整理 #UV #环境安装
Build Efficient Agents——Anthropic团队 在过去的一年里,Anthropic团队(后面简称“团队”)与来自各行各业的团队合作,开发了基于LLM的智能体。结果显示,最成功的实现方式并非依赖复杂的框架或专门的库,而是采用简单、可组合的模式进行构建。 团队将通过这篇文章分享从客户合作和自身智能体构建中获得的经验,并为开发者提供构建高效智能体的实用建议。 原文链接:Building effective agents Anthropic 2024-12-21 categories #精选 #llm #agent
AI Agent:多模态交互前沿调查-李飞飞团队 cdd602f68a7c5a1414d69d136a39ac8d 多模态AI系统很可能会在我们的日常生活中无处不在。将这些系统具身化为物理和虚拟环境中的代理是一种有前途的方式,以使其更加互动化。目前,这些系统利用现有的基础模型作为构建具身代理的基本构件。将代理嵌入这样的环境中,有助于模型处理和解释视觉和上下文数据的能力,这是创建更复杂且具备上下文感知的AI系统的关键。例如,一个能够感 2024-12-08 categories #AI agent #论文 #前沿
FRP使用教程-Windows\linux 在当下的环境中,家宽 公网IPv4 不是每家每户都有的,但是是谁都想搭建个网站玩玩。或者受不了各大云盘厂商的收费方式和手段想搭个 私有云 以解决自己高要求的存储需求。虽然有 IPv6 等手段解决,但是受限于路由器防火墙和国内IPv6普及率问题。目前的 IPv6 在国内更像是 IPv4 的一种补充手段,并没有实现真正意义上的替代。(毕竟没听过纯IPv6网站) 这时候我们就需要使用 Fr 2024-11-11 categories #网络 #工具 #教程
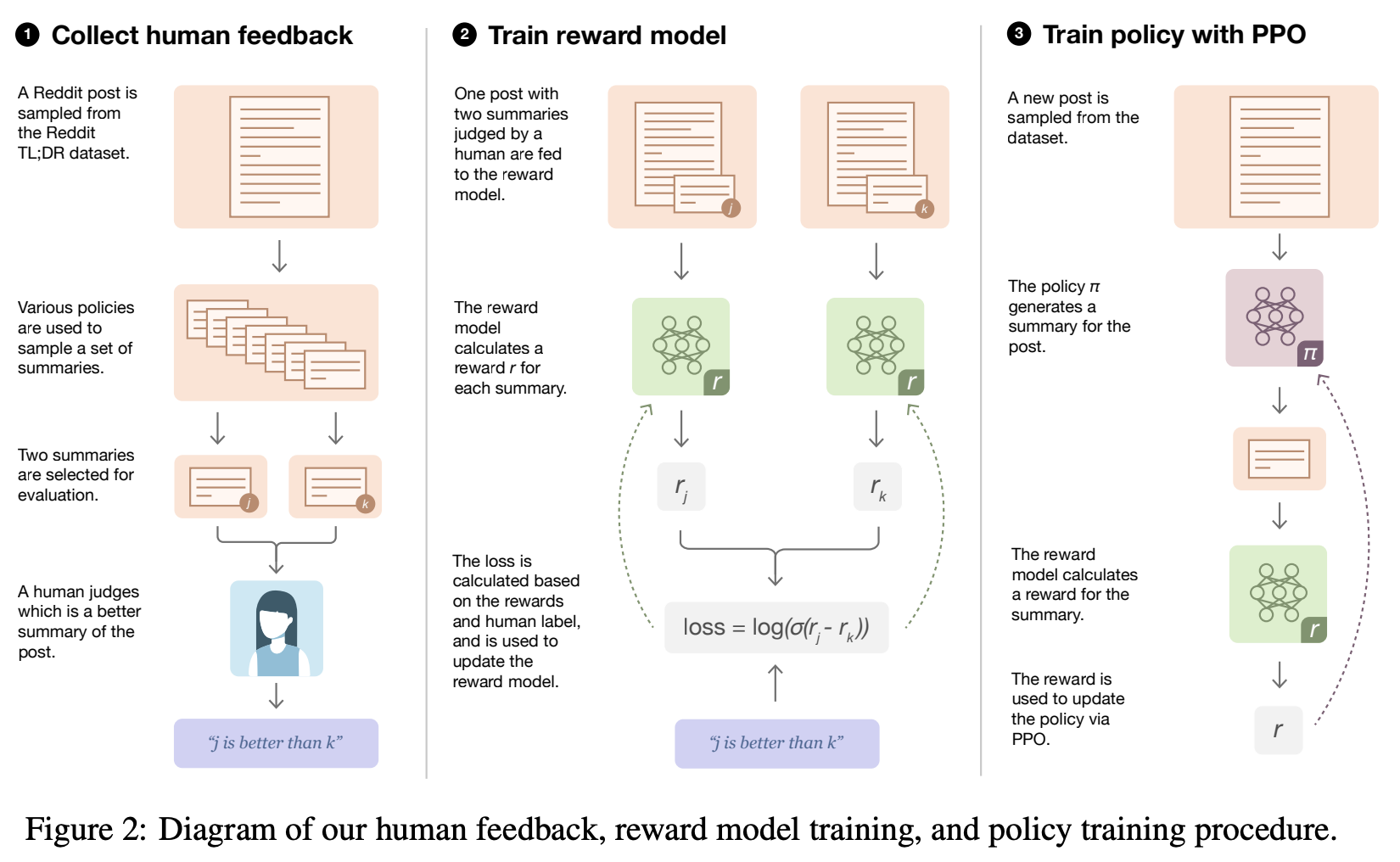
选择RLHF还是SFT 随着 [Llama3] 的开源,人们对 Alignment 的重视程度又上一个阶梯。作为 Alignment 家族中的核中核,RLHF 家族也开始变的繁荣昌盛,这对各位 RLer 来说可真是喜闻乐见。今天我们就一起来俯瞰一下当下 RLHF 都有些什么奇巧的魔改思路。如果你还不太清楚 RLHF 的一些基本概念,可以试着看看这篇文章:何枝:【RLHF】RL 究竟是如何与 LLM 做结合 2024-10-01 RLHF #LLM #模型训练
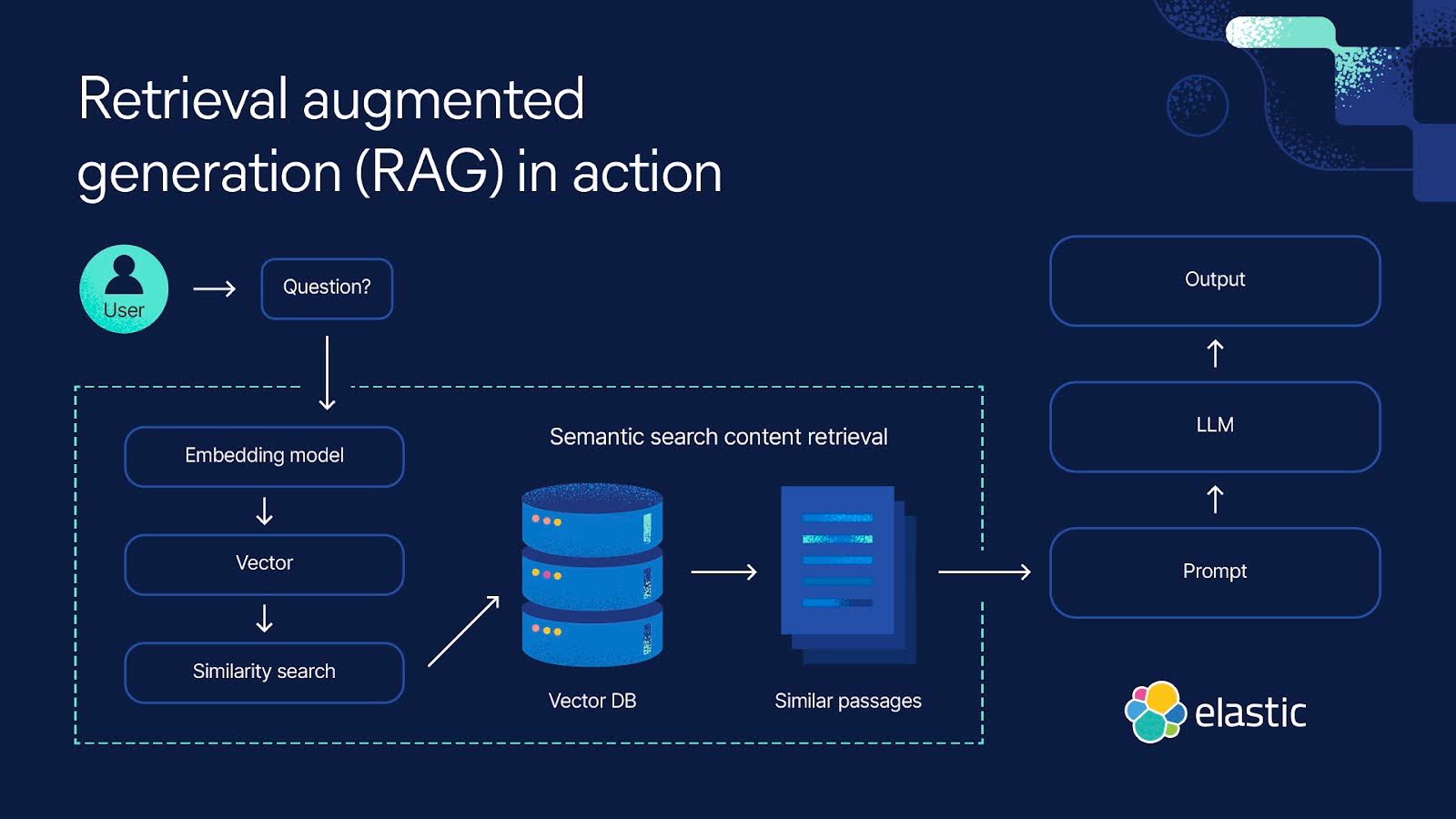
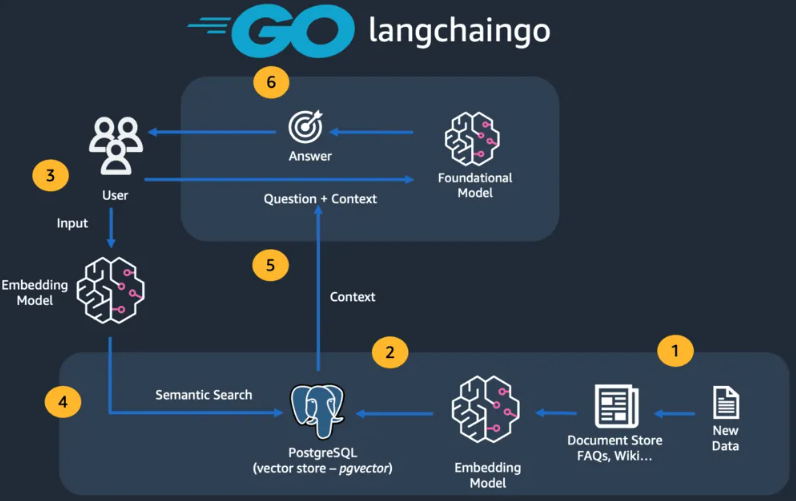
RAG中的rerank技术 [检索增强生成](RAG)是解决大语言模型(LLM)实际使用中的一套完整的技术,它可以有效解决LLM的三个主要问题:[数据时效性]、幻觉和数据安全问题(在我之前的文章《大模型主流应用RAG的介绍——从架构到技术细节》中有详细介绍)。但是随着RAG越来越火热,使用者越来越多,我们也会发现用的好的人/团队其实还是不多的。这也是RAG常被人吐槽的一点:入门简单,用好却非常难! 对于RAG的效果,我们之 2024-09-22 RAG #LLM #rerank
RAG效果评估 随着 LLM(Large Language Model)的应用逐渐普及,人们对 RAG(Retrieval Augmented Generation)场景的关注也越来越多。然而,如何定量评估 RAG 应用的质量一直以来都是一个前沿课题。 很显然,简单的几个例子的对比,并不能准确地衡量出 RAG 应用的整体的回答的好坏,必须采用一些有说服力的指标,定量地、可复现地、来评估一个 RAG 应 2024-09-15 大模型应用 #笔记整理 #大模型应用 #方法框架
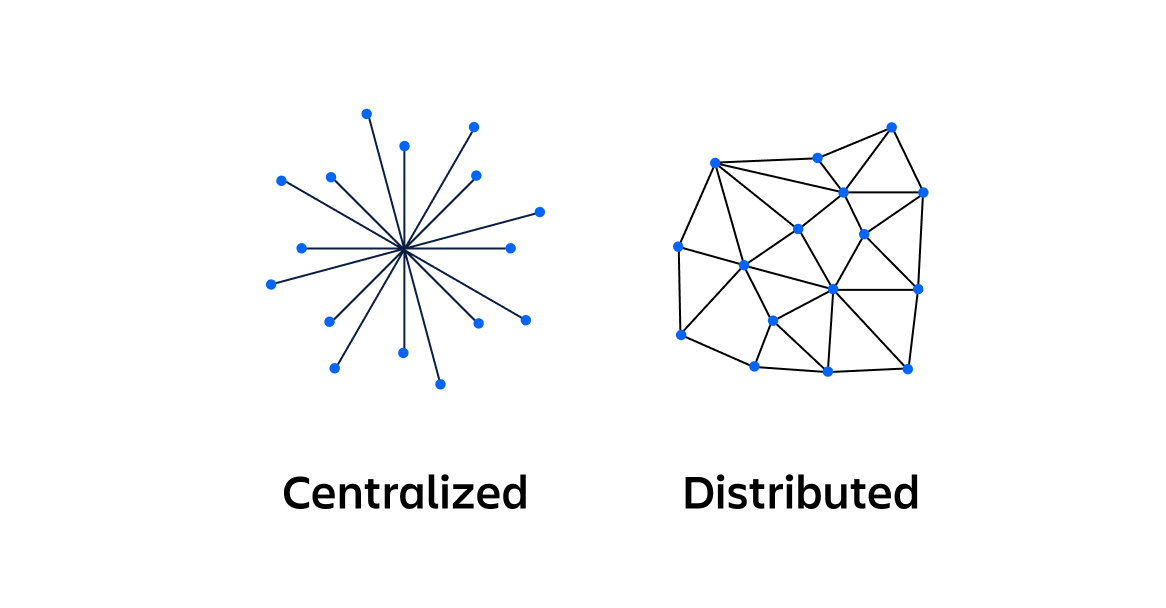
分布式训练架构相关知识 1.背景 随着chatGPT的火爆出圈,大模型也逐渐受到越来越多研究者的关注。有一份来自OpenAI的研究报告(Scaling laws for neural language models)曾经指出模型的性能常与模型的参数规模息息相关,那么如何训练一个超大规模的LLM也是大家比较关心的问题,常用的分布式训练框架有Megatron-LM和DeepSpeed,下面我们将简单介绍这些框架及其用到 2024-09-12 模型训练 #LLM #分布式
大型语言模型LLM训练流程详解 更新内容 这里是近期(2024年8月1日)更新的LLaMA3.1的模型后训练(Post-training)策略和流程 在预训练的基础上,通过几轮后训练对模型进行微调,使其更好地与人类反馈对齐。 每轮后训练包括监督微调(SFT)和直接偏好优化(DPO),后者使用了人工注释和合成的数据样本。 LLM pipline 1.提示收集 Collected Prompts 2024-08-02 大模型 #笔记整理 #深度学习 #大模型